|
|
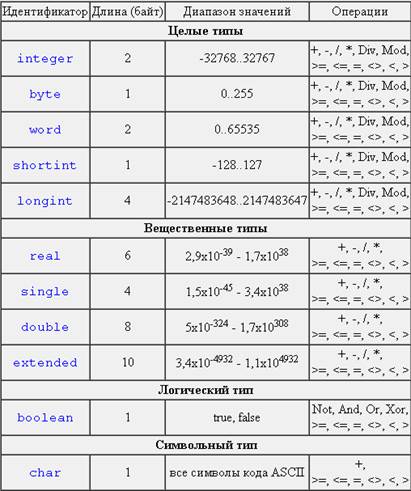
Целочисленные типы данных
Структура программы
Файлы, содержащие текст программы на С++, должны иметь расширение cpp. Следующий пример простой, но вполне законченной программы поможет понять многие из принципов построения программ на языке Си.
Наша первая программа вводит два числа, вычисляет их сумму и печатает результат с поясняющим текстом "Cумма".
#include
int main()
{
int a,b,c;
a=5; b=7; c=a+b;
printf("Cумма = %d \n",c)
}
| Дадим некоторые пояснения. В языке Си любая программа, состоит из нескольких программных единиц и каждая из них - функция. Функцией называется ряд последовательных инструкций, говорящих компьютеру, как выполнить определенную задачу. Многие функции, которые могут вам понадобиться, уже написаны, откомпилированы и помещены в библиотеки, так что вам достаточно просто указать компилятору использовать одну из стандартных функций. Необходимость написания собственной функции возникает только в том случае, если подходящей нет в библиотеках. |
Имена функций выбираются произвольно (только латинскими буквами), но одно из них main, именно с нее начинается выполнение программы. Такая главная функция обычно обращается к другим функциям, которые находятся в одном файле с головной программой или извлекают из библиотеки предварительно подготовленных функций. Все программы на Си (и Си++) должны начинаться с функции, называемой main(). Она выглядит так: main() Круглые скобки являются частью имени функции и ставить их надо обязательно, так как именно они указывают компилятору, что имеется в виду функция, а не просто английское слово main. В противном случае компиляция не будет завершена. Фактически каждая функция включает в свое имя круглые скобки, но в большинстве случаев в них содержится некая информация. В дальнейшем, ссылаясь на функцию, мы всегда будем ставить после ее имени круглые скобки.
Простейшая структура программы такова:
main()- Функция, означающая начало программы точку входа
{- Здесь начинается функция
.....;
.....;-Здесь помещаются инструкции, которые должен выполнить компьютер.....;
} -Здесь функция заканчивается Последовательность инструкций, составляющих функцию, часто называют телом функции. Точка с запятой в языке Си является разделителем и отмечает конец инструкции. Разделитель показывает компилятору, что данная инструкция завершена и дальше начинается следующая инструкция или заканчивается программа. Точку с запятой необходимо ставить после каждой отдельной инструкции.
Ниже приведена завершенная программа на Си/Си++, которая выводит на экран монитора слово «OK»: main() { puts("OK"); }
Типы данных.
Паскаль.
Целые типы. Диапазон возможных значений целых типов зависит от их внутреннего представления, которое может занимать один, два или четыре байта.
Вещественные типы тоже имеют конечное число значений, которое определяется форматом внутреннего представления вещественного числа. Однако количество возможных значений вещественных типов настолько велико, что сопоставить с каждым из них целое число (его номер) не представляется возможным.
Значениями логического типа может быть одна из предварительно объявленных констант FALSE (ложь) или TRUE (истина).
Поскольку логический тип относится к порядковым типам, его можно использовать в операторе счётного типа.
Символьный тип. CHAR – занимает 1 байт. Значением символьного типа является множество всех символов ПК. Каждому символу присваивается целое число в диапозоне 0…255. Это число служит кодом внутреннего представления символа.

С++

Тип данных bool
Первый в таблице — это тип данных bool - целочисленный тип данных, так как диапазон допустимых значений — целые числа от 0 до 255. Но как Вы уже заметили, в круглых скобочках написано — логический тип данных, и это тоже верно. Так какbool используется исключительно для хранения результатов логических выражений. У логического выражения может быть один из двух результатов true или false. true - если логическое выражение истинно, false - если логическое выражение ложно.
Но так как диапазон допустимых значений типа данных bool от 0 до 255, то необходимо было как-то сопоставить данный диапазон с определёнными в языке программирования логическими константами true и false. Таким образом, константе true эквивалентны все числа от 1 до 255 включительно, тогда как константе false эквивалентно только одно целое число — 0. Рассмотрим программу с использованием типа данных bool.
В строке 9 объявлена переменная типа bool, которая инициализирована значением 25. Теоретически после строки 9, в переменной boolean должно содержаться число 25, но на самом деле в этой переменной содержится число 1. Как я уже говорил, число 0 — это ложное значение, число 1 — это истинное значение. Суть в том, что в переменной типа bool могут содержаться два значения — 0 (ложь) или 1 (истина). Тогда как под тип данных bool отводится целый байт, а это значит, что переменная типа bool может содержать числа от 0 до 255. Для определения ложного и истинного значений необходимо всего два значения 0 и 1. Возникает вопрос: «Для чего остальные 253 значения?».
Исходя из этой ситуации, договорились использовать числа от 2 до 255 как эквивалент числу 1, то есть истина. Вот именно по этому в переменной boolean содержится число 25 а не 1. В строках 10 -13 объявлен оператор условного выбора if, который передает управление оператору в строке 11, если условие истинно, и оператору в строке 13, если условие ложно. Результат работы программы смотреть на рисунке 1.
Тип данных char
Тип данных char - это целочисленный тип данных, который используется для представления символов. То есть, каждому символу соответствует определённое число из диапазона [0;255]. Тип данных char также ещё называют символьным типом данных, так как графическое представление символов в С++ возможно благодаря char. Для представления символов в C++ типу данных char отводится один байт, в одном байте — 8 бит, тогда возведем двойку в степень 8 и получим значение 256 — количество символов, которое можно закодировать. Таким образом, используя тип данных char можно отобразить любой из 256 символов. Все закодированные символы представлены в таблице ASCII.
Итак, в строке 9 объявлена переменная с именем symbol, ей присвоено значение символа 'a' (ASCII код). В строке 10оператор cout печатает символ, содержащийся в переменной symbol. В строке 11 объявлен строковый массив с именем string, причём размер массива задан неявно. В строковый массив сохранена строка "cppstudio.com". Обратите внимание на то, что, когда мы сохраняли символ в переменную типа char, то после знака равно мы ставили одинарные кавычки, в которых и записывали символ. При инициализации строкового массива некоторой строкой, после знака равно ставятся двойные кавычки, в которых и записывается некоторая строка. Как и обычный символ, строки выводятся с помощью оператора cout, строка 12. Результат работы программы показан на рисунке 2.
Итак, в строке 9 объявлена переменная с именем symbol, ей присвоено значение символа 'a' (ASCII код). В строке 10оператор cout печатает символ, содержащийся в переменной symbol. В строке 11 объявлен строковый массив с именем string, причём размер массива задан неявно. В строковый массив сохранена строка "cppstudio.com". Обратите внимание на то, что, когда мы сохраняли символ в переменную типа char, то после знака равно мы ставили одинарные кавычки, в которых и записывали символ. При инициализации строкового массива некоторой строкой, после знака равно ставятся двойные кавычки, в которых и записывается некоторая строка. Как и обычный символ, строки выводятся с помощью оператора cout, строка 12. Результат работы программы показан на рисунке 2.
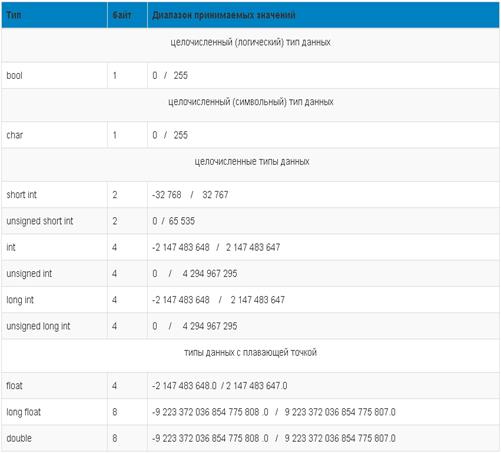
Целочисленные типы данных
Целочисленные типы данных используются для представления чисел. В таблице 1 их аж шесть штук: short int, unsigned short int, int, unsigned int, long int, unsigned long int. Все они имеют свой собственный размер занимаемой памяти и диапазоном принимаемых значений. В зависимости от компилятора, размер занимаемой памяти и диапазон принимаемых значений могут изменяться. В таблице 1 все диапазоны принимаемых значений и размеры занимаемой памяти взяты для компилятора MVS2010. Причём все типы данных в таблице 1 расположены в порядке возрастания размера занимаемой памяти и диапазона принимаемых значений. Диапазон принимаемых значений, так или иначе, зависит от размера занимаемой памяти. Соответственно, чем больше размер занимаемой памяти, тем больше диапазон принимаемых значений. Также диапазон принимаемых значений меняется в случае, если тип данных объявляется с приставкой unsigned - без знака. Приставка unsigned говорит о том, что тип данных не может хранить знаковые значения, тогда и диапазон положительных значений увеличивается в два раза, например, типы данных short int и unsigned short int.
Приставки целочисленных типов данных:
short - приставка укорачивает тип данных, к которому применяется, путём уменьшения размера занимаемой памяти;
long - приставка удлиняет тип данных, к которому применяется, путём увеличения размера занимаемой памяти;
unsigned (без знака) - приставка увеличивает диапазон положительных значений в два раза, при этом диапазон отрицательных значений в таком типе данных храниться не может.
Так, что, по сути, мы имеем один целочисленный тип для представления целых чисел — это тип данных int. Благодаря приставкам short, long, unsigned появляется некоторое разнообразие типов данных int, различающихся размером занимаемой памяти и (или) диапазоном принимаемых значений.