|
|
Вивчення нового матеріалу.
Пошук у ширину.
Раніше ми вже розглядали різноманітні пошукові алгоритми: пошук заданої інформації в одновимірному масиві, в мережі, у рядку. Під час дослідження задач, що пов’язані з обробкою інформації, яку можна представити у вигляді графів, також постає питання пошуку. У першу чергу - це пошук шляху від однієї заданої вершини до іншої.
Існує два підходи до здійснення такого пошуку. Розглянемо перший із них - пошук у ширину.
Вивчення нового матеріалу.
Як відомо, одним із найпоширеніших способів представлення графа є матриця суміжності. Саме на перегляді цієї матриці і базується метод пошуку в ширину.
Для зручнішого пояснення цього методу розглянемо конкретний приклад графа, зображеного на малюнку 21, а та відповідній йому матриці суміжності (мал. 21, б). Нехай також відомо, що необхідно визначити існування у даному графі шляху від вершини 1 до вершини 7.

Почнемо пошук шуканої вершини 7 із заданої вершини 1 і зафіксуємо для себе цю інформацію, будуючи дерево пошуку, в якому на першому кроці нашого пошукового алгоритму є лише одна вершина 1 (мал. 22, а) та послідовність вершин, які переглядаються (мал. 22, б). Встановимо покажчики перегляду вершин у послідовності так: верхній вказуватиме на номер вершини, з якої ми дивимося, а нижній - на номер останньої «видимої» вершини. Відповідно на першому кроці такою вершиною є єдина вершина 1.
І ще одна інформація, яка може бути нам надалі корисною. Якщо забігти наперед і розглянути заданий граф (мал. 21, а), то можна помітити, що вершину з номером 1 знову побачимо, коли перейдемо до перегляду вершин 2, 3 та 4. Але повертатися у неї немає сенсу, оскільки при цьому ми «зациклимося» і будемо крутитися на одному і тому самому місці. Тому варто запам’ятовувати номери вершин, у яких ми вже побували, для
того, щоб виключити їх надалі з перегляду. Яким чином можна реалізувати такий захист? Можна запропонувати два способи: перший - проглядати послідовність переглянутих вершин (мал. 22, б), другий - використати множину для їх фіксації (мал. 22, в). Який з них ефективніший? Якщо кількість вершин невелика, то раціональніше скористатися множиною, якщо ж вона більша за 256 - то переглядом послідовності. Але у цьому разі інформацію про заданий граф необхідно представляти у вигляді списку суміжних вершин.

Продовжимо пошук вершини 7. З малюнка 21, а видно, що з вершини 1 ми бачимо вершини 2, 3 і 4. Ту саму інформацію ми можемо отримати і з таблиці суміжності (мал. 21, б), переглянувши рядок, що відповідає номеру вершини, з якої ми дивимося, тобто перший рядок таблиці. Давайте зафіксуємо цю інформацію у дереві пошуку (мал. 23, а), у послідовності номерів вершин, які ми переглянули (1) і які ми бачимо (2, 3, 4) (мал. 23,в). Серед них поки що шуканої вершини 7 немає.

Для подальшого пошуку перейдемо до однієї з нових вершин, які ми побачили. Це вершини 2, 3 і 4. У нашій послідовності (мал. 23, б) першою записана вершина 2, тому й перейдемо до неї. Які вершини ми бачимо з вершини 2 (мал. 21, а)? Це вершини 1, 3, 5 і 6. Цю саму інформацію можна отримати з другого рядка таблиці суміжності (мал. 21,6). Однак лише вершини 5 і 6 є новими, а вершини 1 і 3 ми вже бачили на попередніх кроках нашого алгоритму. Доповнимо дерево пошуку (мал. 24, а), послідовність переглянутих і «видимих» вершин (мал. 24, б) та множину (мал. 24, в) новою інформацією.

Чи завершили ми наш пошук? Зрозуміло, що ні, оскільки ні у дереві пошуку, ні у послідовності ми ще не дісталися шуканої вершини 7. Тому переходимо у послідовності вершин до наступної «побаченої» вершини 3. Тепер її можна буде назвати не лише «побаченою», але ще й «переглянутою». Згідно із зображенням графа і відповідної йому таблиці суміжності з вершини З ми бачимо вершини 1, 2, 4 і 5. Але вони не є новими, тому ми їх не фіксуємо ні у дереві пошуку, ні у послідовності вершин, ні у множині (мал. 25, а, б, в).
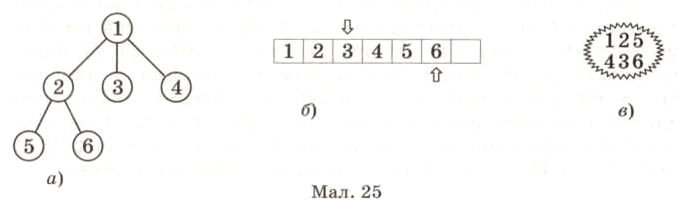
Переходимо до наступної вершини у послідовності, якою є вершина 4. Звідси ми бачимо вершини 1 і 3. Але і ці вершини вже є «побаченими», тому у нашому алгоритмі змінюється лише вершина, яку ми переглядаємо наступною. Такою вершиною є вершина з номером 4, тобто наступна у нашій послідовності «переглянутих» і «видимих» вершин (мал. 26, б). З вершини 4 ми знову-таки нічого нового не побачимо, оскільки вершини 1 та 3 ми вже бачили раніше. Інформація на малюнках 26, а та 26, в залишилася незмінною.

Продовжуючи логіку нашого алгоритму, переходимо до вершини 5 - наступної у нашій послідовності (мал. 27, б). З вершини 5 ми бачимо вершини 2,3,7. Перші дві з цих вершин уже були переглянуті, а от вершина 7 не тільки нова, але й ще шукана. Тому алгоритм можна вважати завершеним, а відповідь на поставлене на початку запитання буде такою: «У заданому графі вершина 7 є досяжною з вершини 1».

Проаналізуємо описаний алгоритм з точки зору його реалізації у вигляді програми. Як було вже сказано вище, інформація про граф міститиметься у таблиці суміжності або у списку суміжності. Інформація про «переглянуті» і «побачені» вершини - в одновимірному масиві. Алгоритм обробки цього масиву відповідає роботі зі структурою даних «черга», де «голова» черги вказує на поточну вершину, з якої ми дивимося далі, а «хвіст» вказує на останню видиму вершину. Під час виконання алгоритму «голова» переміщується вправо на нову вершину, в яку ми переходимо для подальшого перегляду нових вершин, а «хвіст» також переміщується вправо одночасно з дописуванням нових видимих вершин.
Тепер ми можемо проаналізувати умови завершення роботи алгоритму пошуку в ширину. Таких випадків є два: шукана вершина знайдена і відомий шлях до неї, або шукана вершина є недосяжною і шлях до неї відсутній.
Ми розглянули саме перший випадок пошуку вершини в графі, коли шукана вершина 7 є досяжною із заданої вершини 1. Шлях від вершини 1 до вершини 7 присутній у черзі, але без додаткової інформації він дещо прихований. Для отримання цього шляху необхідно запам’ятовувати також і номери вершин, з яких ми побачили кожну наступну вершину. На малюнку 28 ця інформація позначена індексами для кожної поточної вершини, записаної у чергу.

Другий випадок може бути розтлумачений так: «голова» чгрги досягнула її «хвоста», асеред нових «побачених» вершин так і не з’явилася шукана. Це означає, що ми переглянули всі досяжні вершини графа, але не змогли дістатися до шуканої.
Підіб’ємо підсумок наших міркувань і опишемо алгоритм пошуку в ширину в словесній формі.
- Вказати номер вершини k, з якої починається пошук заданої шуканої вершини І.
- Почати перегляд вершин заданого графа з вершини k, записавши її в чергу: і := k. Одночасно ця вершина є і останньою «побаченою» вершиною: j := k.
- Зафіксувати всі нові вершини, які можна побачити з вершини і, в порядку зростання їх номерів, записуючи їх у чергу і збільшуючи при цьому на кожному кроці індекс «хвоста» черги j на 1 (j := j + 1).
- Якщо серед нових «побачених» вершин, записаних у чергу, є шукана вершина, то перейти до п. 8.
- Для переходу до перегляду наступної «побаченої» вершини збільшити значення індексу «голови» черги і (і := і + 1).
- Якщо значення індексу «голови» черги і збіжиться зі значенням індексу його «хвоста» j, то перейти до п.10.
- Перейти до перегляду наступної «побаченої» вершини і (п. 3).
- Вивести інформацію про те, що шукану вершину І досягнуто і шлях до неї від вершини k існує.
- Перейти до п. 11.
- Вивести інформацію про те, що шукана вершина І недосяжна від вершини k і шлях до неї відсутній.
- Завершити алгоритм.
Перейдемо до реалізації описаного алгоритму у вигляді фрагмента Pascal-програми:
head := 1; tail := 2; а[1] := k; {Ініціалізація початкових значень.}
flag := false; s := [k];
while (head < tail) and not flag do {«Голова» менша за «хвіст» та}
begin {не досягнуто шуканої вершини.}
і := 1; {Перегляд к-го рядка таблиці суміжності спочатку.}
while (І <= n) and not flag do {Вести пошук, доки не досягнуто кінця рядка}
begin {або не знайдено шуканої вершини.}
if (d[a[head], І]= 1) and not (І in S) {Якщо поточна вершина є «видимою»}
then {і ще не переглядалася, тоді}
Begin
a[tail] := І; S := S + [і]; {записуємо її у «хвіст» черги та додаємо}
inc(tail); {до множини, збільшуємо індекс «хвоста» черги.}
if і = I then flag := true; {Фіксуємо умову досягнення шуканої вершини.}
end;
inс(і) {Перехід до наступного елемента к-го рядка таблиці суміжності.}
end;
if not false {Якщо не досягнуто шуканої вершини,}
then inc(head) {то збільшуємо індекс «голови» черги.}
end;
If flag then write(f_OUt, ’YES’) {Інформація про те, що знайдено шукану вершину.}
{Інформація про те, що}
else write(f out, ’NO’); {не знайдено шукану вершину.}
Для реалізації алгоритму, що визначає шлях від заданої до шуканої вершини, необхідно зробити корективи.
Опис одновимірного масиву, який реалізує структуру даних «черги», можна запропонувати такий:
а: аггау[1 ..100] of record
top, prev: byte; end;
Початкові значення параметрів «черги» будуть такими: head := 1; tail := 2; a[l].top := k; a[i].prev := 0; а фрагмент програми, що поповнює «чергу» новими «видимими» вершинами, такий:
if (d[a[head].top, і] = 1) and not (і in s)
Then
Begin
a[tail].top := i; a[tail].prev := head;
inc(tail); s := s + [i];
if і = I then flag := true;
end;
Для виведення інформації про існуючий шлях від заданої вершини до шуканої можна запропонувати такий фрагмент програми мовою Pascal:
If flag then
Begin
writeln(f_out, ’YES’);
repeat {Виведення номера поточної вершини}
write(f_out, a[tail]-top, ’ ’); {визначеного шляху.}
{Перехід до вершини, з якої було видно}
tail := a[tail].prev; {поточну вершину шляху.}
until a[tail].prev = 0; {Завершення визначення шляху.}
write(f_OUt, a[tail].top); {Виведення номера вершини, що є початком шляху.}
End
else write(f_out, ’NO’);
Підіб’ємо остаточний підсумок розглянутого методу. По-перше, тепер зрозуміло, чому цей метод носить назву «пошук у ширину». Адже дійсно ми ведемо пошук шуканої вершини, розглядаючи на кожному новому кроці одночасно всі нові вершини по рядках таблиці суміжностей, які ще не бачили. По-друге, можна зробити висновок, що метод пошуку в ширину дає най-
коротший шлях від заданої першими до шукішої. Для того щоб остаточно у цьому пересвідчитися, далі ми перейдемо до іншого методу - пошуку в глибину.
Спробуємо провести оцінку алгоритму пошуку в ширину. Під час формування черги з вершин заданого графа, що складається з п вершин і т ребер, кожна вершина переглядається лише один раз. Це відповідає оцінці О(п). Але при цьому переглядаються всі ребра, яким належить поточна вершина. Отже, оцінка перегляду ребер становить 0(т). Оскільки перегляд ребер іде паралельно з переглядом вершин, що їм належать, то остаточна оцінка алгоритму визначається як 0(п + пі). Отже, можна зробити висновок, що час роботи алгоритму прямо пропорційний розміру заданого графа.