|
|
Сегментная структура программ
Как было показано выше, обращение к памяти осуществляется исключительно посредством сегментов - логических образований, накладываемых на любые участки физического адресного пространства. Начальный адрес сегмента, деленный на 16, т.е. без младшей шестнадцатеричной цифры, заносится в один из сегментных регистров; после этого мы получаем доступ к участку памяти, начинающегося с заданного сегментного адреса.
Каким образом понятие сегментов памяти отражается на структуре программы? Следует заметить, что структура программы определяется, с одной стороны, архитектурой процессора (если обращение к памяти возможно только с помощью сегментов, то и программа, видимо, должна состоять из сегментов), а с другой - особенностями той операционной системы, под управлением которой эта программа будет выполняться. Наконец, на структуру программы влияют также и правила работы выбранного транслятора - разные трансляторы предъявляют несколько различающиеся требования к исходному тексту программы. При подготовке этой книги для трансляции и отладки примеров программ использовался пакет TASM 5.0 корпорации Borland International; он удобен, в частности, наличием наглядного многооконного отладчика. Вопрос этот, однако, не принципиален, и читатель может для отладки примеров, приведенных в книге, воспользоваться любым ассемблером, ознакомившись предварительно с его описанием.
В настоящем разделе мы на простом примере рассмотрим особенности сегментной адресации и роль регистров процессора в выполнении прикладной программы. Однако для того, чтобы программа была работоспособна, нам придется включить в нее ряд элементов, не имеющих прямого отношения к рассматриваемым вопросам, но необходимых для ее правильного функционирования. К таким элементам, в частности, относится вызов функций DOS. Приведя полный текст программы, мы дадим краткие пояснения.
;Пример 1-1. Простая программа с тремя сегментами
;Укажем соответствие сегментных регистров сегментам
assume CS:code,DS:data
;Опишем сегмент команд
code segment ;Откроем сегмент команд
begin: mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных;
Выведем на экран строку текста
mov АН,09h ;Функция DOS вывода на экран
mov DX,offset msg ;Адрес выводимой строки
int 21h ;Вызов DOS
;Завершим программу
mov AX,4C00h ;Функция DOS завершения программы
int 21h ;Вызов DOS
code ends ;Закроем сегмент команд
;Опишем сегмент данных
data segment ;Откроем сегмент данных
msg db "Программа работает!$' ;Выводимая строка
data ends ;Закроем сегмент данных
;Опишем сегмент стека
stk segment stack ;Откроем сегмент стека
db 256 dup (?) ;Отводим под стек 256 байт
stk ends ;Закроем сегмент стека
end begin ;Конец текста с точкой входа
Следует заметить, что при вводе исходного текста программы с клавиатуры можно использовать как прописные, так и строчные буквы; транслятор воспринимает, например, строки MOV AX,DATA и mov ax.data одинаково. Однако с помощью соответствующих ключей можно заставить транслятор различать прописные и строчные буквы в отдельных элементах предложений. В настоящей книге в текстах программ и при описании операторов языка в основном используются строчные буквы, за исключением обозначений регистров, которые для наглядности выделены прописными буквами.
Предложения языка ассемблера могут содержать комментарии, которые отделяются от предложения языка знаком точки с запятой (;). При необходимости комментарий может занимать целую строку (тоже, естественно, начинающуюся со знака ";"). Поскольку в языке ассемблера нет знака завершения комментария, комментарий нельзя вставлять внутрь предложения языка, как это допустимо делать во многих языках высокого уровня. Каждое предложение языка ассемблера, даже самое короткое, должно занимать отдельную строку текста.
В программе 1-1 описаны три сегмента: сегмент команд с именем code, сегмент данных с именем data и сегмент стека с именем stk. Описание каждого сегмента начинается с ключевого слова segment, предваряемого некоторым именем, и заканчивается ключевым словом end, перед которым указывается то же имя, чтобы транслятор знал, какой именно сегмент мы хотим закончить. Имена сегментов выбираются вполне произвольно. Текст программы заканчивается директивой ассемблера end, завершающей трансляцию. В качества операнда этой директивы указывается точка входа в программу; в нашем случае это метка begin.
Порядок описания сегментов в программе, как правило, не имеет значения. Часто программу начинают с сегмента данных, это несколько облегчает чтение программы, и в некоторых случаях устраняет возможные неоднозначности в интерпретации команд, ссылающиеся на данные, которые еще не описаны. Мы в начале программы расположили сегмент команд, за ним - сегмент данных и в конце - сегмент стека; такой порядок предоставляет некоторые удобства при отладке программы. Важно только понимать, что в оперативную память компьютера сегменты попадут в том же порядке, в каком они описаны в программе (если специальными средствами ассемблера не задать иной порядок загрузки сегментов в память).
Сегменты вводятся в программу с помощью директив ассемблера segment и ends. Что такое директива ассемблера? В тексте программы встречаются ключевые слова двух типов: команды процессора (mov, int) и директивы транслятора (в данном случае термины "транслятор" и "ассемблер" являются синонимами, обозначая программу, преобразующую исходный текст, написанный на языке ассемблера, в коды, которые будут при выполнении программы восприниматься процессором). К директивам ассемблера относятся обозначения начала и конца сегментов segment и ends; ключевые слова, описывающие тип используемых данных (db, dup); специальные описатели сегментов вроде stack и т. д. Директивы служат для передачи транслятору служебной информации, которой он пользуется в процессе трансляции программы. Однако в состав выполнимой программы, состоящей из машинных кодов, эти строки не попадут, так как процессору, выполняющему программу, они не нужны. Другими словами, операторы типа segment и ends не транслируются в машинные коды, а используются лишь самим ассемблером на этапе трансляции программы. С этим вопросом мы еще столкнемся при рассмотрении листингов программ.
Еще одна директива ассемблера используется в первом предложении программы:
assume CS:code,DS:data
Здесь устанавливается соответствие сегмента code сегментному регистру CS и сегмента data сегментному регистру DS. Первое объявление говорит о том, что сегмент code является сегментом команд, и встречающиеся в этом сегменте метки принадлежат именно этому сегменту, что помогает ассемблеру правильно транслировать команды переходов. В нашей программе меток нет, и эту часть предложения можно было бы опустить, однако в более сложных программах она необходима (при использовании транслятора MASM эта часть объявления необходима в любой, даже самой простой программе).
Второе объявление помогает транслятору правильно обрабатывать предложения, в которых производится обращение к полям данных сегмента data. Выше уже отмечалось, что для обращения к памяти процессору необходимо иметь две составляющие адреса: сегментный адрес и смещение. Сегментный адрес всегда находится в сегментном регистре. Однако в процессоре два сегментных регистра данных, DS и ES, и для обращения к памяти можно использовать любой из них. Разумеется, процессор при выполнении команды должен знать, из какого именно регистра он должен извлечь сегментный адрес, поэтому команды обращения к памяти через регистры DS или ES кодируются по-разному. Объявляя соответствие сегмента data регистру DS, мы предлагаем транслятору использовать вариант кодирования через регистр DS.
Однако отсюда совсем не следует, что к моменту выполнения команды с обращением к памяти в регистре DS будет содержаться сегментный адрес требуемого сегмента. Более того, можно гарантировать, что нужного адреса в сегментном регистре не будет. Директива assume влияет только на кодирование команд, но отнюдь не на содержимое сегментных регистров. Поэтому практически любая программа должна начинаться с предложений, в которых в сегментный регистр, используемый для адресации к сегменту данных (как правило, это регистр DS) заносится сегментный адрес этого сегмента. Так сделано и в нашем примере с помощью двух команд
mov AX,data ;Настроим DS
mov DS,AX ;на сегмент данных
с которых начинается наша программа. Сначала значение имени data (т.е. адрес сегмента data) загружается командой mov в регистр общего назначения процессора АХ, а затем из регистра АХ переносится в регистр DS. Такая двухступенчатая операция нужна потому, что процессор в силу некоторых особенностей своей архитектуры не может выполнить команду непосредственной загрузки адреса в сегментный регистр. Приходится пользоваться регистром АХ в качестве "перевалочного пункта".
Поместив в регистр DS сегментный адрес сегмента данных, мы получили возможность обращаться к полям этого сегмента. Поскольку в программе может быть несколько сегментов данных, операционная система не может самостоятельно определить требуемое значение DS, и инициализировать его приходится "вручную".
Назначением программы 1-1 предполагается вывод на экран текстовой строки "Программа работает!", описанной в сегменте данных. Следующие предложения программы как раз и выполняют эту операцию. Делается это не непосредственно, а путем обращения к служебным программам операционной системы MS-DOS, которую мы для краткости будем в дальнейшем называть просто DOS. Дело в том, что в составе команд процессора и, соответственно, операторов языка ассемблера нет команд вывода данных на экран (как и команд ввода с клавиатуры, записи в файл на диске и т.д.). Вывод даже одного символа на экран в действительности представляет собой довольно сложную операцию, для выполнения которой требуется длинная последовательность команд процессора. Конечно, эту последовательность команд можно было бы включить в нашу программу, однако гораздо проще обратиться за помощью к операционной системе. В состав DOS входит большое количество программ, осуществляющих стандартные и часто требуемые функции - вывод на экран и ввод с клавиатуры, запись в файл и чтение из файла, чтение или установка текущего времени, выделение или освобождение памяти и многие другие.
Для того, чтобы обратиться к DOS, надо загрузить в регистр общего назначения АН номер требуемой функции, в другие регистры - исходные данные для выполнения этой функции, после чего выполнить команду hit 21h (int - от interrupt, прерывание), которая передаст управление DOS. Вывод на экран строки текста можно осуществить функцией 09h, которая требует, чтобы в регистрах DS:DX содержался полный адрес выводимой строки. Регистр DS мы уже инициализировали, осталось поместить в регистр DX относительный адрес строки, который ассоциируется с именем поля данных msg. Длину выводимой строки указывать нет необходимости, так как функция 09h DOS выводит на экран строку от указанного адреса до символа доллара, который мы предусмотрительно включили в выводимую строку. Заполнив все требуемые для конкретной функции регистры, можно выполнить команду int 21h, которая осуществит вызов DOS.
Как завершить выполняемую программу? В действительности завершение программы - это довольно сложная последовательность операций, в которую входит, в частности, освобождение памяти, занятой завершившейся программой, а также вызов той системной программы (конкретно - командного процессора COMMAND.COM), которая выведет на экран запрос DOS, и будет ожидать ввода следующих команд оператора. Все эти действия выполняет функция DOS с номером 4Ch. Эта функция предполагает, что в регистре AL находится код завершения нашей программы, который она передаст DOS. Если программа завершилась успешно, код завершения должен быть равен 0, поэтому мы в одном предложении mov AX,4C00h загружаем в АН 4Ch, а в AL - 0, и вызываем D'OS уже знакомой нам командой int 21h.
Для того, чтобы выполнить пробный прогон приведенной программы, ее необходимо сначала оттранслировать и скомпоновать. Пусть исходный текст программы хранится в файле с именем P.ASM. Трансляция осуществляется вызовом ассемблера TASM.EXE с помощью следующей .команды DOS;
tasm /z/zi/n p/p,p
Ключ /z разрешает вывод на экран строк исходного текста программы, в которых ассемблер обнаружил ошибки (без этого ключа поиск ошибок пришлось бы проводить по листингу трансляции).
Ключ /zi управляет включением в объектный файл информации, не требуемой при выполнении программы, но используемой отладчиком.
Ключ /n подавляет вывод в листинг перечня символических обозначений в программе, от чего несколько уменьшается информативность
листинга, но сокращается его размер.
Стоящие далее параметры определяют имена файлов: исходного (P.ASM), объектного (P.OBJ) и листинга (P.LST). При желании можно в строке вызова транслятора указать полные имена файлов с их расширениями, однако необходимости в этом нет, так как по умолчанию транслятор использует именно указанные выше расширения.
Строка вызова компоновщика имеет следующий вид:
tlink /x/v p,p
Ключ /х подавляет образование листинга компоновки, который обычно не нужен.
Ключ /v передает в загрузочный файл информацию, используемую отладчиком. Стоящие далее параметры обозначают имена модулей: объектного (Р.ОЫ) и загрузочного (Р.ЕХЕ).
Поскольку при изучении этой книги вам придется написать и отладить большое количество программ, целесообразно создать командный файл (с именем, например, А.ВАТ), автоматизирующий выполнение однотипных операций трансляции и компоновки. Текст командного файла в простейшем варианте может быть таким (в предположении, что путь к каталогу с пакетом TASM был указан в параметре команды PATH):
tasm /z/zi/n p,p,p
tlink /х/v р,р
Запуск подготовленной программы Р.ЕХЕ осуществляется командой .р.ехе или просто
При загрузке программы сегменты размещаются в памяти, как показано на рис. 1.9.
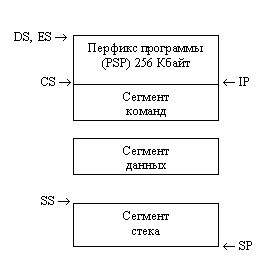
Рис. 1.9. Образ программы в памяти.
Образ программы в памяти начинается с сегмента префикса программы (Program Segment Prefics, PSP), образуемого и заполняемого системой. PSP всегда имеет размер 256 байт; он содержит таблицы и поля данных, используемые системой в процессе выполнения программы. Вслед за PSP располагаются сегменты программы в том порядке, как они объявлены в программе. Сегментные регистры автоматически инициализируются следующим образом: ES и DS указывают на начало PSP (что дает возможность, сохранив их содержимое, обращаться затем в программе к PSP), CS - на начало сегмента команд, a SS - на начало сегмента стека. В указатель команд IP загружается относительный адрес точки входа в программу (из операнда директивы end), а в указатель стека SP - величина, равная объявленному размеру стека, в результате чего указатель стека указывает на конец стека (точнее, на первое слово за его пределами).
Таким образом, после загрузки программы в память адресуемыми оказываются все сегменты, кроме сегмента данных. Инициализация регистра DS в первых строках программы позволяет сделать адресуемым и этот сегмент.
Рисунок 1.9 еще раз подчеркивает важнейшую особенность архитектуры процессоров Intel: адрес любой ячейки памяти состоит из двух слов, одно из которых определяет расположение в памяти соответствующего сегмента, а другое - смещение в пределах этого сегмента. Смысл сегментной части адреса, хранящейся всегда в одном из сегментных регистров, в реальном и защищенном режиме различен; в МП 86 сегментная часть адреса, после умножения ее на 16, определяет физический адрес начала сегмента в памяти.
Отсюда следует, что сегмент всегда начинается с адреса, кратного 16, т.е. на границе 16-байтового блока памяти (параграфа). Сегментный адрес можно рассматривать, как номер параграфа, с которого начинается данный сегмент. Размер сегмента определяется объемом содержащихся в нем данных, но никогда не может превышать величину 64 Кбайт, что определяется максимально возможной величиной смещения.
Сегментный адрес сегмента команд хранится в регистре CS, а смещение к адресуемому байту - в указателе команд IP. Как уже отмечалось, после загрузки программы в IP заносится смещение первой команды программы; процессор, считав ее из 'памяти, увеличивает содержимое IP точно на длину этой команды (команды процессоров Intel могут иметь длину от 1 до 6 байт), в результате чего IP указывает на вторую команду программы. Выполнив первую команду, процессор считывает из памяти вторую, опять увеличивая значение IP. В результате в IP всегда находится смещение очередной команды, т. е. команды, следующей за выполняемой. Описанный алгоритм нарушается только при выполнении команд переходов, вызовов подпрограмм и обслуживания прерываний.
Сегментный адрес сегмента данных обычно хранится в регистре DS, a смещение может находится в одном из регистров общего назначения, например, в ВХ или SI. Однако в МП 86 два сегментных регистра данных - DS и ES. Дополнительный сегментный регистр ES часто используется для обращения к полям данных, не входящим в программу, например к видеобуферу или системным ячейкам. Однако при необходимости его можно настроить и на один из сегментов программы. В частности, если программа работает с большим объемом данных, для них можно предусмотреть два сегмента и обращаться к одному из них через регистр DS, а к другому - через ES.
Стек
Стеком называют область программы для временного хранения произвольных данных. Разумеется, данные можно сохранять и в сегменте данных, однако в этом случае для каждого сохраняемого на время данного надо заводить отдельную именованную ячейку памяти, что увеличивает размер программы и количество используемых имен. Удобство стека заключается в том, что его область используется многократно, причем сохранение в стеке данных и выборка их оттуда выполняется с помощью эффективных команд push и pop без указания каких-либо имен.
Стек традиционно используется, например, для сохранения содержимого регистров, используемых программой, перед вызовом подпрограммы, которая, в свою очередь, будет использовать регистры процессора "в своих личных целях". Исходное содержимое регистров изатекается из стека после возврата из подпрограммы. Другой распространенный прием - передача подпрограмме требуемых ею параметров через стек. Подпрограмма, зная, в каком порядке помещены в стек параметры, может забрать их оттуда и использовать при своем выполнении.
Отличительной особенностью стека является своеобразный порядок выборки содержащихся в нем данных: в любой момент времени в стеке доступен только верхний элемент, т.е. элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента делает доступным следующий элемент.
Элементы стека располагаются в области памяти, отведенной под стек, начиная со дна стека (т.е. с его максимального адреса) по последовательно уменьшающимся адресам. Адрес верхнего, доступного элемента хранится в регистре-указателе стека SP. Как и любая другая область памяти программы, стек должен входить в какой-то сегмент или образовывать отдельный сегмент. В любом случае сегментный адрес этого сегмента помещается в сегментный регистр стека SS. Таким образом, пара регистров SS:SP описывают адрес доступной ячейки стека: в SS хранится сегментный адрес стека, а в SP - смещение последнего сохраненного в стеке данного (рис. 1.10, а). Обратите внимание на то, что в исходном состоянии указатель стека SP указывает на ячейку, лежащую под дном стека и не входящую в него.

Рис. 1.10. Организация стека:
а - исходное состояние, б - после загрузки одного элемента (в данном примере - содержимого регистра АХ), в - после загрузки второго элемента (содержимого регистра DS), г - после выгрузки одного элемента, д - после выгрузки двух элементов и возврата в исходное состояние.
Загрузка в стек осуществляется специальной командой работы со стеком push (протолкнуть). Эта команда сначала уменьшает на 2 содержимое указателя стека, а затем помещает операнд по адресу в SP. Если, например, мы хотим временно сохранить в стеке содержимое регистра АХ, следует выполнить команду
push АХ
Стек переходит в состояние, показанное на рис. 1.10, б. Видно, что указатель стека смещается на два байта вверх (в сторону меньших адресов) и по этому адресу записывается указанный в команде проталкивания операнд. Следующая команда загрузки в стек, например,
push DS
переведет стек в состояние, показанное на рис. 1.10, в. В стеке будут теперь храниться два элемента, причем доступным будет только верхний, на который указывает указатель стека SP. Если спустя какое-то время нам понадобилось восстановить исходное содержимое сохраненных в стеке регистров, мы должны выполнить команды выгрузки из стека pop (вытолкнуть):
pop DS
pop AX
Состояние стека после выполнения первой команды показано на рис. 1.10, г, а после второй - на рис. 1.10, д. Для правильного восстановления содержимого регистров выгрузка из стека должна выполняться в порядке, строго противоположном загрузке - сначала выгружается элемент, загруженный последним, затем предыдущий элемент и т.д.
Совсем не обязательно при восстановлении данных помещать их туда, где они были перед сохранением. Например, можно поместить в стек содержимое DS, а извлечь его оттуда в другой сегментный регистр - ES;
push DS
pop ES ; Теперь ES=DS, а стек пуст
Это распространенный прием для перенесения содержимого одного регистра в другой, особенно, если второй регистр - сегментный.
Обратите внимание (см. рис 1.10) на то, что после выгрузки сохраненных в стеке данных они физически не стерлись, а остались в области стека на своих местах. Правда, при "стандартной" работе со стеком они оказываются недоступными. Действительно, поскольку указатель стека SP указывает под дно стека, стек считается пустым; очередная команда push поместит новое данное на место сохраненного ранее содержимого АХ, затерев его. Однако пока стек физически не затерт, сохраненными и уже выбранными из него данными можно пользоваться, если помнить, в каком порядке они расположены в стеке. Этот прием часто используется при работе с подпрограммами.
Какого размера должен быть стек? Это зависит от того, насколько интенсивно он используется в программе. Если, например, планируется хранить в стеке массив объемом 10 000 байт, то стек должен быть не меньше этого размера. При этом надо иметь в виду, что в ряде случаев стек автоматически используется системой, в частности, при выполнении команды прерывания int 21h. По этой команде сначала процессор помещает в стек адрес возврата, а затем DOS отправляет туда же содержимое регистров и другую информацию, относящуюся к прерванной программе. Поэтому, даже если программа совсем не использует стек, он все же должен присутствовать в программе и иметь размер не менее нескольких десятков слов. В нашем первом примере мы отвели под стек 128 слов, что безусловно достаточно.
Система прерываний
Система прерываний любого компьютера является его важнейшей частью, позволяющей быстро реагировать на события, обработка которых должна выполнятся немедленно: сигналы от машинных таймеров, нажатия клавиш клавиатуры или мыши, сбои памяти и пр. Рассмотрим в общих чертах компоненты этой системы.
Сигналы аппаратных прерываний, возникающие в устройствах, входящих в состав компьютера или подключенных к нему, поступают в процессор не непосредственно, а через два контроллера прерываний, один из которых называется ведущим, а второй - ведомым (рис. 1.11)
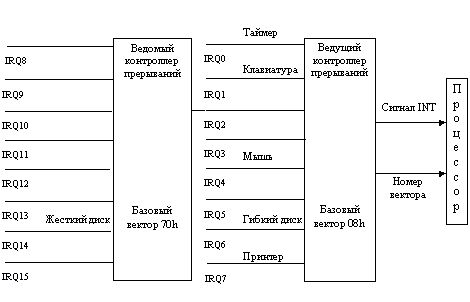
Рис. 1.11. Аппаратная организация прерываний.
Два контроллера используются для увеличения допустимого количества внешних устройств. Дело в том, что каждый контроллер прерываний может обслуживать сигналы лишь от 8 устройств. Для обслуживания большего количества устройств контроллеры можно объединять, образуя из них веерообразную структуру. В современных машинах устанавливают два контроллера, увеличивая тем самым возможное число входных устройств до 15 (7 у ведущего и 8 у ведомого контроллеров).
К входным выводам IRQ1...IRQ7 и IRQ8...IRQ15 (IRQ - это сокращение от Interrupt Request, запрос прерывания) подключаются выводы устройств, на которых возникают сигналы прерываний. Выход ведущего контроллера подключается к входу INT микропроцессора, а выход ведомого - к входу IRQ2 ведущего. Основная функция контроллеров - передача сигналов запросов прерываний от внешних устройств на единственный вход прерываний микропроцессора. При этом, кроме сигнала INT, контроллеры передают в микропроцессор по линиям данных номер вектора, который образуется в контроллере путем сложения базового номера, записанного в одном из его регистров, с номером входной линии, по которой поступил запрос прерывания. Номера базовых векторов заносятся в контроллеры автоматически в процессе начальной загрузки компьютера. Для ведущего контроллера базовый вектор всегда равен 8, для ведомого - 70h. Таким образом, номера векторов, закрепленных за аппаратными прерываниями, лежат в диапазонах 8h...Fh и 70h...77h. Очевидно, что номера векторов аппаратных прерываний однозначно связаны с номерами линий, или уровнями IRQ, а через них - с конкретными устройствами компьютера. На рис. 1.11 указаны некоторые из стандартных устройств компьютера, работающих в режиме прерываний.
Процессор, получив сигнал прерывания, выполняет последовательность стандартных действий, обычно называемых процедурой прерывания. Подчеркнем, что здесь идет речь лишь о реакции самого процессора на сигналы прерываний, а не об алгоритмах обработки прерываний, предусматриваемых пользователем в программах обработки прерываний.
Объекты вычислительной системы, принимающие участие в процедуре прерывания, и их взаимодействие показаны на рис. 1.12.

Рис. 1.12. Процедура обслуживания прерывания.
Самое начало оперативной памяти от адреса 0000h до 03FFh отводится под векторы прерываний - четырехбайтовые области, в которых хранятся адреса обработчиков прерываний (ОбрПр на рис. 1.12). В два старшие байта каждого вектора записывается сегментный адрес обработчика, в два младшие - смещение (относительный адрес) точки входа в обработчик. Векторы, как и соответствующие им прерывания, имеют номера, причем вектор с номером 0 располагается, начиная с адреса 0, вектор 1 - с адреса 4, вектор 2 - с адреса 8 и т.д. Вектор с номером п занимает, таким образом, байты памяти от n*4 до n*4+3. Всего в выделенной под векторы области памяти помещается 256 векторов.
Получив сигнал на выполнение процедуры прерывания с определенным номером, процессор сохраняет в стеке выполняемой программы текущее содержимое трех регистров процессора: регистра флагов, CS и IP. Два последних числа образуют полный адрес возврата в прерванную программу. Далее процессор загружает CS и IP из соответствующего вектора прерываний, осуществляя, тем самым, переход на обработчик прерывания, связанный с этим вектором.
Обработчик прерываний всегда заканчивается командой iret (interrupt return, возврат из прерывания), выполняющей обратные действия - извлечение из стека сохраненных там слов и помещение их назад в регистры IP и CS, а также в регистр флагов. Это приводит к возврату в основную программу в ту самую точку, где она была прервана.
В действительности запросы на обработку прерываний могут иметь различную природу. Помимо описанных выше аппаратных прерывания от периферийных устройств, называемых часто внешними, имеются еще два типа прерываний: внутренние и программные.
Внутренние прерывания возбуждаются цепями самого процессора при возникновении одной из специально оговоренных ситуаций, например, при выполнении операции деления на ноль или при попытке выполнить несуществующую команду. За каждым из таких прерываний закреплен определенный вектор, номер которого известен процессору. Например, за делением на 0 закреплен вектор 0, а за неправильной командой - вектор 6. Если процессор сталкивается с одной из таких ситуаций, он выполняет описанную выше процедуру прерывания, используя закрепленный за этой ситуацией вектор прерывания.
Наконец, еще одним чрезвычайно важным типом прерываний являются программные прерывания. Они вызываются командой hit с числовым аргументом, который рассматривается процессором, как номер вектора прерывания. Если в программе встречается, например, команда
int 13h
то процессор выполняет ту же процедуру прерывания, используя в качестве номера вектора операнд команды int. Программные прерывания применяются в первую очередь для вызова системных обслуживающих программ - функций DOS и BIOS. С командой int 2In вызова DOS мы уже сталкивались в примере 1-1 и будем встречаться еще многократно. В дальнейшем будут также приведены примеры использования команды int для вызова прикладных обработчиков программных прерываний.
Важно подчеркнуть, что описанные действия процессора выполняются совершенно одинаково для всех видов прерываний - внутренних, аппаратных и программных, хотя причины, возбуждающие процедуру прерывания, имеют принципиально разную природу.
Большая часть векторов прерываний зарезервирована для выполнения определенных действий; часть из них автоматически заполняется адресами системных программ при загрузке системы. Приведем краткую выдержку из таблицы векторов, позволяющую продемонстрировать разнообразие ее состава:
00h -внутреннее прерывание, деление на 0;
0lh -внутреннее прерывание, пошаговое выполнение (при TF=1);
02h -немаскируемое прерывание (вывод NMI процессора);
08h -аппаратное прерывание от системного таймера;
09h -аппаратное прерывание от клавиатуры;
0Eh -аппаратное прерывание от гибкого диска;
10h - программное прерывание, программы BIOS управления видеосистемой;
13h - программное прерывание, программы BIOS управления дисками;
16h - программное прерывание, программы BIOS управления клавиатурой;
IDh -не вектор, адрес таблицы видеопараметров, используемой BIOS;
lEh -не вектор, адрес таблицы параметров дискеты, используемой BIOS;
21h - программное прерывание, диспетчер функций DOS;
22h - программное прерывание, адрес перехода при завершении процесса, используемый DOS;
23h -программное прерывание, обработчик прерываний по <Ctrl>/C, используемый DOS;
25h - программное прерывание, абсолютное чтение диска (функция DOS);
26h - программное прерывание, абсолютная запись на диск (функция DOS);
60h...66h - зарезервировано для программных прерываний пользователя;
68h...6Fh - программные прерывания, свободные векторы;
70h -аппаратное прерывание от часов реального времени (с питанием от аккумулятора);
76h -аппаратное прерывание от жесткого диска;
Как видно из таблицы, векторы прерываний можно условно разбить
на следующие группы:
векторы внутренних прерываний процессора (0lh, 02h и др.);
векторы аппаратных прерываний (08h...0Fh и 70h...77h);
программы BIOS обслуживания аппаратуры компьютера (10h, 13h, 16h и др.);
программы DOS (21h, 22h, 23h и др.);
адреса системных таблиц BIOS (IDh, lEh и др.).
Системные программы, адреса которых хранятся в векторах прерываний, в большинстве своем являются всего лишь диспетчерами, открывающими доступ к большим группам программ, реализующих системные функции. Так, видеодрайвер BIOS (вектор 10h) включает программы смены видеорежима, управления курсором, задания цветовой палитры, загрузки шрифтов и многие другие. Особенно характерен в этом отношении вектор 21h, через который осуществляется вызов практически всех функций DOS: ввода с клавиатуры и вывода на экран, обслуживания файлов, каталогов и дисков, управления памятью и процессами, службы времени и т.д. Для вызова требуемой функции надо не только выполнить команду int с соответствующим номером, но и указать системе в одном из регистров (для этой цели всегда используется регистр АН) номер вызываемой функции. Иногда для "многофункциональных" функций приходится указывать еще и номер подфункции (в регистре AL).