|
|
Меры центральной тенденции выборки, свойства с доказательствами, вычисление для табулированных данных.
Мерами центральной тенденции (МЦТ) называют численные показатели типичных свойств эмпирических данных. Эти показатели дают ответы на вопрос о том, например, \"который средний уровень интеллекта студентов педагогического университета в? \",\" Которое типичное значение показателя ответственности определенной группы лиц? \"Существует сравнительно небольшое количество таких показателей - мер и в первую очередь: мода, медиана, среднее арифметическое. Каждая конкретная МЦТ имеет свои особенности, которые делают ее ценным для характеристики объекта исследования в определенных условиях.
-мода выборки вычисляется просто, ее можно определить \"на глаз\" Для очень больших групп данных мода достаточно стабильной степени центра распределения;
xmod – наиболее часто встречающееся значение случайной величины.
xmod = x(nmax)
-медиана занимает промежуточное положение между модой и средним с точки зрения ее подсчета. Эта мера особенно легко определяется при ранжированых данных;
xmed – среднее значение упорядоченного вариационного ряда чисел если n – нечетное 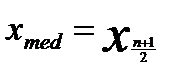
Если n – четное 
-среднее арифметическое предусматривает использование всех значений выборки, причем все они влияют на значение этой меры.

Табулирование данных
Для анализа и интерпретации исходных количественных данных их необходимо обобщить. Чаще всего 1 этапом представления исходных данных является упорядочивание их по величине (по возрастанию или по убыванию). Если исходная выборка упорядочена по возрастанию, т.е. сначала расположено наблюдение, наименьшее по величине, затем 2 по величине и т.д., то такая выборка называется вариационным рядом и обозначается следующим образом: х(1), х(2), …, х(n) - упорядочены, х(1) < х(2) < … < х(n) (некоторые элементы 84, 84, 106, 106 могут совпадать); х1, х2 - не упорядочены, в произвольном порядке.
Когда исходная выборка имеет достаточно большой объем, то используют табулирование данных – т.е. представляют исходную выборку в виде таблицы соответствующего вида.
Табулирование обычно осуществляется в 4 этапа:
1 этап – определение размаха выборки. Для этого из максимального элемента выборки вычитают минимальный.
R= хmax – xmin = x(n) - x(1), где R – размах выборки.
2 этап – определение ширины интервала, группирование данных. Прежде чем искать ширину интервала, необходимо определиться с количеством интервалов в группировании. Очень небольшое количество интервалов может слишком упростить и сгладить общую тенденцию, а слишком большое количество интервалов может привести к излишней детализации рассматриваемого явления. Рекомендация: количество интервалов выбирается таким образом, чтобы в каждый интервал попадало в среднем 5-6 элементов выборки. Для этого объем выборки делим на 5 и на 6, в результате получаем два числа.
k1=n/5, k2 = n/6, где n - объем выборки. После этого в качестве требуемого количества интервала выбирается целое число к, находящееся между k1 и k2 . Пример: n=32, k1=32/5=6,4; k2 =32/6=5,3; отсюда получается в качестве к будет 6 (к=6 или к=5). Тогда ширина интервала группирования получается путем деления размаха выборки на количество интервалов.
h= R/k, где h – ширина.
Т.к. в большинстве случаев наши исходные данные являются целыми числами, то ширину интервала можно также округлить до ближайшего целого числа. h=50/6=8,3=8
3 этап– определение границ интервалов группирования данных. При этом нужно обращать внимание на то, чтобы левая граница первого интервала не оказалась справа от наименьшего значения на числовой оси.
4этап – непосредственно само табулирование данных. На этом этапе мы подсчитываем, сколько элементов выборки попало в каждый интервал. Количество наблюдений, попавших в интервал, называется частотой. Результатом табулирования данных является таблица, состоящая из двух столбцов, первый из которых содержит границы интервала, второй – частоты.
Простая табуляция - подсчет количества событий, которые попадают в каждую категорию, когда категории базируются на одной переменной.
Перекрестная табуляция - подсчет количества событий, которые попадают в каждую из нескольких категорий, когда категории базируются на двух и более переменных, рассматриваемых одновременно.