|
|
МОДЕЛИ ПРОГНОЗИРОВАНИЯ ЭКОНОМИЧЕСКИХ ПРОЦЕССОВ
Прогноз– это вероятностное суждение о состоянии какого-либо объекта, процесса или явления к определенному моменту времени будущего и (или) о возможных путях и сроках достижения этого состояния.
В таком случае прогнозирование можно определить как процесс формирования (или разработки) прогнозов. Наука, изучающая гносеологическую природу процесса прогнозирования, разрабатывающая его теоретические основы и методологию, называется прогностикой.
В литературе встречаются сопутствующие прогнозированию понятия: предсказание и предвидение. Эти понятия различаются степенью достоверности оценок будущего; соответствующие им логические формы различных процессов выработки информации о будущем можно выразить следующим образом: прогнозирование – «что может быть»; предсказание – «по-видимому, будет»; предвидение – «непременно будет»; планирование – «должно быть».
Прогнозирование и составление планов – элементы единой системы планирования, объединенные общностью целей и задач. Однако, несмотря на это, методы прогнозирования и планирования существенно различаются. При планировании действует следующая схема: «цели – директивные; пути и средства их достижения – детерминированные; ресурсы – ограниченные». При прогнозировании схема иная: «цели – теоретически достижимые; пути и средства их достижения – возможные; ресурсы – вероятные». План может содержать только одно оптимальное решение развития, а прогноз – веер (или спектр) альтернатив. Прогнозирование дает представление о наиболее правдоподобных вариантах. Включение какого-либо из них в план – право соответствующего руководителя.
Процесс прогнозирования непременно предусматривает постановку цели: именно она определяет направленность последующих действий (получения необходимой информации, ее обработки, оценки и анализа, определения перспектив и вероятности реализации прогноза). Все этапы процесса разработки прогноза должны быть увязаны с поставленными целями и задачами. Причем в одних случаях на основе уже поставленной цели (или целей) прогнозируются пути ее (их) достижения, в других прогностическое исследование осуществляется для того, чтобы определить реально достижимую, отвечающую потребностям общественного развития цель. В первом случае имеет место так называемое нормативное (целевое) прогнозирование, во втором - генетическое (поисковое, исследовательское) прогнозирование.
Успех при разработке прогноза во многом зависит от правильного выбора метода прогнозирования, количество которых достаточно велико.
Любой метод прогнозирования базируется на идее экстраполяции. Экстраполяция основана на анализе предыстории развития, выявлении наиболее общих и устойчивых закономерностей и связей, учете благоприятных тенденций и перенесении полученных выводов на прогнозируемый период.
Изменение экономических явлений во времени наиболее полно отражается во временных рядах (рядах динамики)[1], позволяющих детально проанализировать особенности развития. Отдельные наблюдения временного ряда называются уровнями этого ряда. Уровни формируются под влиянием множества длительно и кратковременно действующих факторов и в том числе различного рода случайностей. Изменение условий развития явления приводит к более или менее интенсивной смене самих факторов, к изменению силы и результативности их воздействия и, в конечном счете, к вариации уровня изучаемого явления во времени.
В статистической литературе уровень ряда динамики традиционно представляется в виде суммы четырех компонент, которые непосредственно не могут быть измерены:
· тенденция (систематическое движение) - некоторое общее направление развития, долговременная эволюция;
· сезонная составляющая - это более или менее регулярные изменения временного ряда, возникающие с наступлением данного времени года и повторяющиеся с небольшими отклонениями из года в год;
· циклическая составляющая, характеризующая циклические колебания, свойственные любому воспроизводству;
· «случайная» («несистематическая», или «нерегулярная») компонента как результат влияния множества случайных факторов.
Следует отметить, что не всегда ряды динамики состоят из четырех компонент. Единственной компонентой, которая всегда встречается в этих рядах, является случайная составляющая, которая может присутствовать в сочетании только с определенной тенденцией или только с какими-то периодическими колебаниями. Чаще всего встречаются временные ряды, где можно установить тенденцию и случайную компоненту, особенно при использовании годичных данных, не отражающих влияние сезонности.
Обычно тенденцию (если установлено ее наличие) стремятся представить в виде более или менее гладкой кривой (траектории), которая аналитически выражается некоторой функцией времени, называемой трендом. Тренд характеризует основную закономерность движения во времени, свободную в основном (но не полностью) от случайных воздействий.
Предполагается, что, рассматривая любое явление как функцию времени, можно выразить влияние всех основных факторов, причем механизм их влияния в явном виде не учитывается. В связи с этим под трендом обычно понимают регрессию на время. Более общее понятие тренда, весьма удобное на практике, - это детерминированная составляющая динамики развития, определяемая влиянием постоянно действующих факторов. Отклонение от тренда представляет собой случайную составляющую. Исходя из этого, уровни временного ряда (Yt) можно представить следующим образом:
Yt = f (t) + e t, (1.1)
где f (t) – систематическая (детерминированная) составляющая, характеризующая
основную тенденцию изменения показателя во времени;
e t – случайная составляющая.
Задача прогнозирования состоит не только в том, чтобы выделить детерминированную часть в развитии процесса, но и в том, чтобы оценить и предсказать ту часть процесса, которая характеризуется случайной компонентой, т.е. случайным отклонением от тенденции.
При использовании в прогнозировании методов математико-статистического моделирования различают трендовые и факторные модели.
В трендовой модели уровень прогнозируемого показателя является функцией времени. На самом деле за этим временем скрывается комплекс причинных факторов и условий, определяющих форму и параметры тренда. Но все эти факторы заданы неявно, в виде их среднегодового влияния на результативный показатель Y через параметры тренда.
Факторные модели в явном виде отражают влияние различных обстоятельств и факторов на исследуемый и прогнозируемый показатель. Среди факторных моделей особого внимания заслуживают многофакторные модели, позволяющие использовать системный подход к изучению взаимосвязанных экономических явлений и процессов.
Независимо от вида и метода построения моделей вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т. е. соответствия модели исследуемому процессу. Для адекватных моделей имеет смысл ставить задачу оценки их точности, которая характеризуется величиной отклонения полученных по модели результатов от реального значения моделируемого показателя.
О точности прогноза принято судить по величине погрешности прогноза (ошибки) – разности между прогнозируемым и фактическим значением (реализацией) исследуемой переменной. Однако, такой подход к оценке точности возможен только в двух случаях. Во-первых, когда период упреждения уже окончился и исследователь имеет фактические значения переменной. При краткосрочном прогнозировании это вполне реально. Во-вторых, когда прогноз разрабатывается ретроспективно, т.е. прогнозирование осуществляется для некоторого момента времени в прошлом (для которого уже имеются фактические данные). При этом имеющаяся информация делится на две части. Одна из них, охватывающая более ранние данные, служит для оценивания параметров прогностической модели, а более поздние данные рассматриваются как реализации соответствующих прогностических оценок. Полученные ретроспективные ошибки прогноза в какой-то мере характеризуют точность примененной методики прогнозирования и могут оказаться полезными при сопоставлении нескольких методов.
1.1 Прогнозирование на основе трендовых моделей (кривых роста)
Сущность методики экономического прогнозирования с помощью трендов заключается в их временной экстраполяции. Основная цель такого прогноза – показать, каких результатов можно достичь в будущем, если двигаться к нему с той же скоростью, ускорением и т.д., что и в прошлом. Если такая оценка окажется неудовлетворительной, то сложившаяся в прошлом тенденция должна быть изменена с учетом тех факторов, под влиянием которых она складывается.
Первым этапом экстраполяции тренда является выбор функции (кривой роста), наилучшим образом описывающей эмпирический временной ряд и оценка ее параметров. Эта функция может быть получена путем аналитического выравнивания динамического ряда. При этом чаще всего применяются: многочлены (полиномы), экспонента (показательная функция); логистические кривые; кривая Гомперца.
Правильный выбор типа кривой во многом определяет успех прогнозирования. Ошибка здесь (при прочих равных условиях) оказывается более значимой по своим последствиям, чем ошибка, связанная со статистическим оцениваем параметров.
В основе выбора кривой должен лежать теоретический анализ сущности изучаемого явления, изменения которого отображаются временным рядом. Иногда во внимание принимаются соображения о характере роста уровней ряда. Так, если рост выпуска продукции в плане предусматривается в виде арифметической прогрессии, то выравнивание производится по прямой. Если же оказывается, что рост идет в геометрической прогрессии, то выравнивание надо производить по показательной функции. Необходимо отметить, что для определения тренда в экономических динамических рядах нецелесообразно использовать полиномы высоких степеней, поскольку полученные таким образом аппроксимирующие функции будут отражать случайные отклонения, а не детерминированную компоненту, что противоречит смыслу тенденции.
Наиболее распространенным методом оценки параметров зависимостей является метод наименьших квадратов.
На практике обычно окончательный подбор вида функции тренда, параметры которой определяются методом наименьших квадратов, производится эмпирически, путем построения ряда функций и сравнения их между собой по величине среднеквадратической ошибки (стандартного отклонения):
 , (1.2)
, (1.2)
где 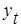 - фактические уровни временного ряда,
- фактические уровни временного ряда,
 - расчетные (вычисленные по уравнению тренда) значения уровней
- расчетные (вычисленные по уравнению тренда) значения уровней
временного ряда,
n - количество уровней во временном ряду (количество наблюдений),
m – количество оцениваемых в функции тренда параметров;
f = n – m – число степеней свободы; так, если выравнивание производится
по прямой, то f = n – 2; для параболы второй степени f = n – 3 и т. д.
После выбора одной или нескольких функций, описывающих тенденцию развития рассматриваемого процесса, следует выполнить проверку их качества.
Качество модели определяется ее адекватностью исследуемому процессу и точностью.
Модель считается адекватной, если систематическая компонента (тренд) определена правильно. При правильном выборе вида тренда отклонения от него (т.е. разности между фактическими уровнями ряда и их расчетными (вычисленными по модели) значениями) будут:
1) носить случайный характер. Это означает, что изменение остаточной компоненты не связано с изменением времени (не зависит от фактора времени);
2) иметь равное нулю математическое ожидание;
3) нормально распределены;
4) независимы друг от друга (т. е. в остаточной последовательности не будет существенной автокорреляции).
Точность модели определяется степенью близости расчетных уровней ряда к фактическим данным (формула (1.2)), а также с помощью других показателей, о которых речь пойдет дальше.
Для проверки случайности остатков можно применить критерий серий, суть которого в следующем.
Отклонения от тренда располагают в порядке возрастания их значений, т. е. в виде вариационного ряда, и в этом ряду находят медиану ем (среднее по расположению число для ряда с нечетным числом уровней или среднее арифметическое двух серединных величин при четном числе уровней).
Возвращаясь к исходному ряду остатков и сравнивая его уровни с медианой, ставят знак «плюс», если проверяемый уровень больше медианы, и «минус», если он меньше медианы (если они равны, то никакой знак не ставится). Последовательность подряд идущих плюсов или минусов образует серию, а количество плюсов или минусов в серии определяет ее длину. Иногда серия может состоять только из одного плюса или минуса, и тогда ее длина равна единице.
Последовательность плюсов и минусов характеризуется общим числом серий (V) и протяженностью самой длинной серии (Kmax).
Отклонения от тренда будут случайными, если выполнены следующие неравенства при 5%-ном уровне значимости:
Kmax < [3,3 ( lg  + 1)]; (1.3)
+ 1)]; (1.3)
V > [  ( +1 – 1,96
( +1 – 1,96 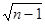 )]. (1.4)
)]. (1.4)
Квадратные скобки в этих формулах означают целую часть числа.
Если хотя бы одно из неравенств не выполняется, то гипотеза о случайном характере отклонений уровней временного ряда от тренда с вероятностью 0,95 отвергается.
Проверку соответствия распределения случайной компоненты (остаточной последовательности) нормальному закону распределения можно произвести лишь приближенно с помощью исследования показателей асимметрии и эксцесса, так как временные ряды не очень велики.
Для расчета показателей асимметрии ( А ) и эксцесса ( Э ) и их среднеквадратических ошибок ( sА и sЭ соответственно) можно использовать следующие формулы:
 ,
,  , (1.5)
, (1.5)
 ,
,  . (1.6)
. (1.6)
Если одновременно выполняются неравенства:
ç А ç < 1,5 sA, ½Э +  ½ < 1,5 sЭ, (1.7)
½ < 1,5 sЭ, (1.7)
то с вероятностью 0,95 гипотеза о нормальном характере распределения остатков не отвергается. Если же выполняется хотя бы одно из неравенств:
ç А ç ³ 2 sA, ½Э +  ½ ³ 2 sЭ, (1.8)
½ ³ 2 sЭ, (1.8)
то о нормальном законе распределения речь не идет. Другие случаи требуют дополнительной проверки с помощью более сложных критериев.
Проверка равенства математического ожидания случайной компоненты нулю, если она распределена по нормальному закону, осуществляется на основе
t-критерия Стьюдента. Расчетное значение этого критерия задается формулой:
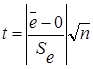 , (1.9)
, (1.9)
где 
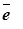 - среднее арифметическое уровней остаточной последовательности е t;
- среднее арифметическое уровней остаточной последовательности е t;
Sе - стандартное (среднеквадратическое) отклонение для этой последовательности.
Если расчетное значение t меньше табличного значения ta с заданным уровнем значимости a и числом степеней свободы (n-1), то гипотеза о равенстве нулю математического ожидания случайной последовательности принимается; в противном случае эта гипотеза отвергается, и модель считается неадекватной.
В адекватной модели ряд остатков не должен быть автокоррелирован. Проверка на автокорреляцию выполняется с помощью d-критерия Дарбина-Уотсона, в соответствии с которым вычисляется d - статистика:
 . (1.10)
. (1.10)
Результат сравнивается с двумя табличными значениями: верхним (dВ) и нижним (dН), которые зависят от количества наблюдений, числа независимых переменных и выбранного уровня значимости.
Если d-статистика (при d < 2) находится в интервале от 0 до dН, то уровни ряда сильно коррелированны, а модель неадекватна. При попадании значения d-статистики в интервал от dВ до 2 уровни ряда являются независимыми, т. е. проверяемое условие выполняется. Если же рассчитанная величина d попадает в зону между dН и dВ, то однозначного вывода сделать нельзя и следует применять другие критерии. Когда вычисленное значение d превышает 2, то описанной проверке (с теми же выводами) подвергается величина d* = 4 - d.
Вывод об адекватности трендовой модели делается, если все указанные выше четыре проверки дают положительный результат.
Проверка точности модели проводится с целью оценки ошибки в подборе кривой роста. Выражение для стандартной ошибки задается формулой (1.2). Кроме того, часто используется средняя ошибка аппроксимации:
 . (1.11)
. (1.11)
С той же целью используется коэффициент детерминации:
 . (1.12)
. (1.12)
Модели, для которых  , l имеют минимальное значение, а D – максимальное, лучше отображают исследуемый процесс.
, l имеют минимальное значение, а D – максимальное, лучше отображают исследуемый процесс.
Экстраполяция дает возможность получить точечное значение прогноза. Однако, экономические переменные являются, как правило, непрерывными и, следовательно, указание их точечных значений, строго говоря, лишено содержания, поскольку «попадание» в точку имеет нулевую вероятность. Отсюда следует, что прогноз должен быть дан в виде «вилки», интервала значений. Одним из путей получения такой «вилки» является определение доверительного интервала прогноза, в который с определенной вероятностью должно попасть фактическое значение прогнозируемого показателя (реализация).
Доверительный интервал для прогноза (интервальный прогноз), очевидно, должен учитывать не только неопределенность, связанную с положением тренда, но и возможность отклонения от этого тренда. Обозначим соответствующую стандартную ошибку прогноза как sp, тогда доверительный интервал прогноза представляется в виде:
 , (1.13)
, (1.13)
где  - точечный прогноз с периодом упреждения, равным L;
- точечный прогноз с периодом упреждения, равным L;
ta - табличное значение t-критерия Стьюдента при уровне значимости a% и числе степеней свободы (n-2).
Стандартную ошибку прогноза для случая, когда тренд характеризуется прямой, можно вычислить по формуле:
 . (1.14)
. (1.14)
Как видим, ширина доверительного интервала зависит от количества наблюдений и периода упреждения. При увеличении ретроспективного периода n (продолжительности наблюдений) значения K (т. е. и ширина интервала) уменьшаются, а с ростом величины L они растут.
Основной вопрос – в какой мере в будущем сохранится найденная тенденция, - естественно, не может быть решен с помощью таких доверительных интервалов. Это дело содержательного экономического анализа и, вероятно, экспертной оценки.
1.2 Сезонная и случайная компоненты
В общем случае каждый уровень динамического ряда (Yt ) может быть представлен в аддитивной форме:
Yt = Тt + St + Et (1.15)
где Тt – тренд динамического ряда – регулярная компонента, характеризующая общую тенденцию;
St – сезонная компонента, или внутригодичные колебания, а в общем случае – циклическая составляющая;
Et – случайная компонента, образующаяся под влиянием различных (как правило, неизвестных) причин.
К сезонным относятся явления, которые обнаруживают в своем развитии определенные закономерности, более или менее регулярно повторяющиеся из месяца в месяц, из квартала в квартал. Так, под сезонностью понимают неравномерность производственной деятельности в отраслях промышленности, связанных с переработкой сельскохозяйственного сырья, поступление которого зависит от времени года. Кроме того, при прогнозировании объемов продаж часто приходится учитывать тенденции сезонности, так как данные о продажах и соответствующие им временные ряды зачастую носят именно сезонный характер. Например, объемы продаж могут достигать пика в начале года (рождественские и новогодние праздники), а затем, до начала следующего года, постепенно возвращаться к исходному, более низкому уровню. Тогда прогноз не просто составляется на основе предшествующих результатов наблюдений, он базируется на двух следующих компонентах.
· Компонента тренда представляет тенденцию временного ряда (базовой линии) к повышению либо к понижению.
· Компонента сезонности представляет любое резкое повышение, понижение или пик базовой линии, которые происходят с одинаковым промежутком времени.
(Базовая линия представляет собой числовое выражение результатов наблюдений, проводимых на протяжении длительного периода времени.)
Сезонная компонента характеризуется длительностью периода сезонных колебаний, их амплитудой, расположением максимумов и минимумов во времени. В зависимости от стабильности указанных характеристик во времени сезонная компонента носит постоянный или переменный характер.
Сезонная компонента St имеет период Т0, т.е. St+То = St, Т0 = 12 для месячных данных и Т0 = 4 для квартальных данных.
Величина Т0 содержится в Т целое число (m) раз, т.е. Т = m Т0.
При относительном постоянстве амплитуды сезонных колебаний целесообразно использовать аддитивную модель (компоненты складываются), при ее изменении в соответствии с тенденцией - мультипликативную (представляющую произведение компонент).
Для определения сезонной и случайной компонент вычисляется динамический ряд:
St + Et = Yt – Тt . (1.16)
Сезонная и случайная компоненты представляют собой составляющие временного ряда, которые остаются после выделения из него тренда. Если все составляющие найдены правильно, то математическое ожидание случайной компоненты равно нулю и ее колебания около среднего значения постоянны (имеет место гомоскедастичность).
При разделении сезонной и случайной компонент обычно первой вычленяют сезонную компоненту, а оставшуюся часть временного ряда (1.16) относят к случайной составляющей.
Вместе с тем следует заметить, что конкретные временные ряды часто не содержат сезонной (циклической) составляющей, поэтому необходимо проверять гипотезу о наличии или отсутствии сезонных колебаний с помощью какого-либо критерия (например, дисперсионного или гармонического) или визуально по графику.
При подтверждении сезонного процесса осуществляется фильтрация сезонной составляющей[2].