|
|
Перспективи застосування
Штучний інтелект використовується в:
· системах діагностики в медицині
· системах зборки і контролю на виробництві
· систем дистанційного навчання і контролю знань в освіті
· експертних системах в будь-яких галузях і т.д.
Лекція 2. Напрямки використання систем ШІ
1. Огляд прикладних областей штучного інтелекту
1.1. Слабо структуровані прикладні області ШІ
1.2. Добре структуровані прикладні області ШІ
2. Тест Т’юрінга
2.1. Основна ідея тесту Т’юрінга.
2.2. Особливості тесту Т’юрінга.
2.3. “Вразливі” місця тесту Т’юрінга.
3. Основні проблеми штучного інтелекту
3.1. Представлення знань
3.2. Пошук
4. Ведення ігор
4.1. Створення простору станів
4.2. Пошук в просторі станів за допомогою евристик
5. Автоматичне доведення теорем
5.1. Системи Logic Theorist і General Problem Solver
5.2. Принцип автоматичного доведення теорем і систем математичних обґрунтувань
6. Експертні системи
6.1. Експертне знання
6.2. DENDRAL
6.3. MYCIN
6.4. PROSPECTOR
6.5. INTERNIST
6.6. XCON
6.7. Недоліки експертних систем
7. Розуміння природних мов
7.1. Програма SHRDLU
7.2. Семантичні мережі
8. Робототехніка
8.1. Використання великої кількості комбінацій при плануванні
8.2. Ієрархічна декомпозиція задачі
8.4. Агентно-орієнтовані прийняття рішень
8.3. Організація планування, яка дозволяє реагувати на зміни в навколишньому середовищі
9. Мови і середовища штучного інтелекту
9.1. Методи структурування знань
9.2. Високорівневі мови програмування
9.2.1. PROLOG
9.2.2. LISP
10. Машинне навчання
10.1. Автоматизований математик
10.2. Алгоритм ID3.
10.3. Meta-DENDRAL
10.4. Інтелектуальний інтерфейс Teiresias
11. Нейронні мережі
1. Огляд прикладних областей штучного інтелекту.
1.1. Слабо структуровані прикладні області ШІ
Методи штучного інтелекту ефективні для так званих слабо структурованих предметних областей, тобто таких областей, алгоритм дії в яких заздалегідь невідомий. Для таких областей характерна неясність і нечіткість у вхідних даних. Проте рішення мають бути однозначні, чіткі та зрозумілі, бажано також передбачити ефективність даного рішення. До таких областей відносяться: медицина, економічний менеджмент, керування складними технічними об'єктами, психологія, лінгвістика й ще багато інших.
1.2. Добре структуровані прикладні області ШІ
Що ж тоді не відноситься до прикладних областей штучного інтелекту? Це так звані добре структуровані предметні області. До них в першу чергу належать точні й інженерні науки, такі як математика, фізика, опір матеріалів, геодезія й цілий ряд інших. Застосування методів штучного інтелекту менш ефективне в цих областях тому, що для розв'язку завдань у цих науках уже існують свої власні надійні алгоритми й методи, випробувані протягом десятків або навіть сотень років.
2. Тест Т’юрінга
2.1. Основна ідея тесту Т’юрінга
Одна з перших робіт, в якій розглядається розум машини по відношенню до сучасних цифрових комп’ютерів “Обчислювальні машини і інтелект”, була написана в 1950 р. британським математиком Аланом Т’юрінгом і опублікована в журналі “Mind”.
Учений Алан T’юрінг сформулював тезу, спрямовану на визначення моменту, з якого машину можна вважати інтелектуальною або чи можна машину дійсно заставити думати.
Тест Т’юрінга порівнює здібності “розумної” машини зі здібностями людини – кращим і єдиним стандартом розумної поведінки. В тесті, який учений назвав “імітаційною грою”, машину та її суперника (людина) помістили в різні кімнати, відділені від кімнати, в якій знаходиться “імітатор” (дослідник), який не повинен бачити чи розмовляти з ними напряму – він спілкується виключно за допомогою текстового обладнання, наприклад, комп’ютерного терміналу. (див. мал.1). Імітатор задає їм будь-які запитання, з різних областей, довільної кількості. Наприклад, дослідник може попросити обох піддослідних реалізувати досить складний арифметичний підрахунок, припускаючи, що комп’ютер швидше дасть правильну відповідь, ніж людина. Щоб обхитрити цю стратегію, комп’ютер повинен знати, коли йому потрібно видати хибне число, щоб здатися людиною. Щоб виявити поведінку людини на основі емоційної природи, дослідник може попросити двох об’єктів висловитися з приводу якогось вірша чи картини. В такому випадку комп’ютер повинен знати про емоційний склад людини. Виключно на основі їхніх відповідей на запитання, які задаються через пристрій, імітатор повинен відрізнити комп’ютер від людини. Якщо він не зможе їх розрізнити, тоді Т’юрінг стверджує, що в такому випадку машину можна вважати розумною.
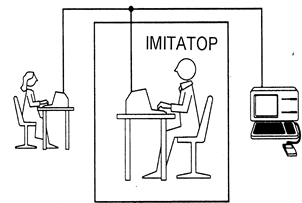
Мал.1. Тест Т’юрінга
2.2. Особливості тесту Т’юрінга
Даний тест має наступні важливі особливості:
1. Дає об’єктивне поняття про інтелект, як реакція свідомо розумної істоти на визначений набір запитань. Вводить стандарт для визначення інтелекту.
2. Не дає можливості зайти в тупік при виясненні питання типу : чи повинен комп’ютер використовувати якісь конкретні внутрішні процеси? Чи повинна машина усвідомлювати свої дії?
3. Виключає необ’єктивність на користь живих створінь, заставляючи того, хто запитує, фокусуватись виключно на змісті відповідей на питання.
Завдяки цим перевагам, тест Т’юрінга являє собою основу для багатьох схем, які використовуються на практиці для випробовування сучасних інтелектуальних машин.
2.3. “Вразливі” місця тесту Т’юрінга
Незважаючи на інтуїтивну привабливість, тест Т’юрінга має “вразливі” місця. Одним з них є прив’язаність та використання переважно символьних задач. Тест не торкається здібностей, потребуючих навиків перцепції чи спритності рук, хоча подібні аспекти являються важливою складовою людського інтелекту. Деколи, навпаки, тест Т’юрінга звинувачують в спробах втиснути машинний інтелект у форму людського інтелекту. Та все ж таки даний тест представляється важливою складовою в тестуванні та “атестації” сучасних інтелектуальних програм.
3. Основні проблеми штучного інтелекту
3.1. Представлення знань
Дві найбільш фундаментальні проблеми, які цікавлять розробників ШІ, – це представлення знань (knowledge representation) і пошук (search). Перша відноситься до проблеми отримання нових знань з допомогою формальної мови, яка підходить для комп’ютерних маніпуляцій, всього спектру знань, необхідних для формування розумової поведінки.
3.2. Пошук
Пошук – це метод вирішення проблеми, в якому систематично розглядається простір стану задач (problem states), тобто альтернативні стадії її розвитку. Потім в даному просторі альтернативних рішень відбувається вибірка в пошуках остаточної відповіді. Приклад стану задачі: довільні розміщення фігур на дошці в грі. Ньюелл і Саймон стверджують, що даний метод лежить в основі людського способу рішення різних задач. Дійсно, коли ігрок в шахмати аналізує наслідки різних ходів чи лікар обдумує різні альтернативні діагнози, то вони роблять вибір серед допустимо можливих альтернатив.
4. Ведення ігор
4.1. Створення простору станів
Багато досліджень в області пошуку простору станів здійснювалися на основі розповсюджених настільних ігор, як шашки, шахмати та ін. Більшість ігор ведеться з використанням чітко визначеного набору правил: це дає можливість легко створити простір станів і позбавляє від неясності і плутанини, притаманних менш структурним проблемам. Пошук в просторі станів – принцип, що лежить в основі більшості досліджень в області ведення ігор.
4.2. Пошук в просторі станів за допомогою евристик
Ігри можуть породжувати незвичайно великі простори станів, для пошуку в яких застосовуються певні методики, що визначають, які альтернативи потрібно розглядати. Такі методики називаються евристиками і утворюють значну область досліджень штучного інтелекту. Евристика – корисна стратегія, але потенційно здатна упустити правильне рішення. Прикладом евристики може бути прохання перевірити чи включений прилад у розетку, перш ніж зробити припущення про його поломку. Значна частина того, що ми називаємо розумом, базується на евристиці, яку люди використовують при вирішенні ряду проблем чи задач.
5. Автоматичне доведення теорем
5.1. Системи Logic Theorist і General Problem Solver
Автоматичне доведення теорем – одне з найдавніших складових штучного інтелекту, основи якого беруть свій початок в системах Logic Theorist (логічний теоретик) Ньюелла і Саймона та General Problem Solver (універсальний вирішувач задач) аж до спроб Рассела і Уайтхеда побудувати всю математику на основі формальних формувань теорем із початкових аксіом. В будь-якому випадку дана галузь принесла найбільші досягнення. Завдяки дослідженням в області доведення теорем були формалізовані алгоритми пошуку і розроблені мови формальних представлень, такі як обрахування предикатів і логічна мова програмування PROLOG.
5.2. Принцип автоматичного доведення теорем і систем математичних обґрунтувань
Привабливість автоматичного доведення теорем заснована на строгості й спільності логіки. У формальній системі логіка опирається на автоматизацію. Різні проблеми можна спробувати вирішити, подавши опис задачі і належну відповідно їй інформацію у вигляді логічних аксіом та розглядати задачі як теореми, які потрібно довести. Цей принцип лежить в основі автоматичного доведення теорем і систем математичних обґрунтувань.
На жаль, в ранніх спробах написати програму для автоматичного доведення, яка б єдиним способом вирішувала складні задачі, не вдалося.
І ще однією причиною неабиякого інтересу до автоматичного доведення теорем є розуміння того, що системі не обов’язково вирішувати складні проблеми без втручання людини. Багато сучасних програм доведення працюють як розумні помічники, надаючи людям можливість розбивати задачі на підзадачі і продумувати евристики для перебору в просторі можливих обґрунтувань.
6. Експертні системи
6.1. Експертне знання
Одним з головних досягнень ранніх досліджень по штучному інтелекту стало усвідомлення важливості специфічного знання для предметної області (domain-specific). Наприклад, лікар добре діагностує хвороби не тому, що він володіє деякими вродженими загальними здібностями, а тому, що багато знає про медицину.
Експертне знання – це комбінація теоретичного усвідомлення проблеми і набору евристичних правил щодо її вирішення, які ефективні в даній предметній області. Експертні системи створюються за допомогою запозичення знань у людського експерта й кодування їх у форму, яку комп'ютер може застосувати до аналогічних проблем.
Стратегії експертних систем базуються на знаннях людини-експерта. Спеціаліст з ШІ або інженер із знанням (knowledge engineer) відповідає за реалізацію знання в програмі, яка повинна працювати ефективно і зовні розумно.
6.2. DENDRAL
Однією з перших систем, що використала специфічні для предметної області знання, була система DENDRAL, розроблена в Стенфорді в кінці 1960-х рр. DENDRAL створена з метою визначення будови органічних молекул з хімічних формул і спектрографічних даних про хімічні зв'язки в молекулах. DENDRAL вирішує проблему великого простору перебору, застосовуючи евристичні знання експертів-хіміків для вирішення задачі визначення структури. Методи DENDRAL виявилися досить ефективними. Система методично знаходить правильну будову із мільйону можливих за декілька спроб.
Програма DENDRAL однією з перших використала специфічні знання для досягнення рівня експерта при вирішенні проблем.
6.3. MYCIN
Методика сучасних експертних систем пов’язана з іншою програмою – MYCIN. Програма MYCIN розроблена в Стенфорді в середині 1970-х, однією з перших звернулася до проблеми прийняття рішень на основі ненадійної або недостатньої інформації. Вона виводить ясні і логічні пояснення своїх тлумачень, використовуючи структуру керуючої логіки, відповідну специфіці предметної області, та критерії для надійної оцінки своєї роботи. Багато методик розробки експертних систем, які використовуються сьогодні, вперше були розроблені в рамках проекту MYCIN.
6.4. PROSPECTOR
До числа інших класичних експертних систем відноситься програма PROSPECTOR, що визначає рудні родовища і їх типи, ґрунтуючись на геологічних даних про місцевість.
6.5. INTERNIST
Програма INTERNIST, застосовується для діагностики в сфері медицини внутрішніх органів.
6.6. XCON
Програма XCON, яка була розроблена в 1981 році, використовується для налаштування комп’ютерів VAX.
В даний час експертні системи вирішують ряд проблем в таких областях як медицина, освіта, бізнес, дизайн, наукові дослідження та ін. Варто зауважити, що більшість експертних систем написані для спеціалізованих предметних областей, які досить добре вивчені і чітко володіють певними стратегіями прийняття рішень.
6.7. Недоліки експертних систем
Незважаючи на перспективи, експертні системи мають ряд недоліків:
труднощі в передачі “глибоких знань” предметної області;
недостатня гнучкість;
неможливість надати осмислені пояснення;
труднощі в тестуванні;
обмежені можливості навчання на досвіді.
7. Розуміння природних мов
Одним із завдань штучного інтелекту є створення програм, які здатні розуміти людську мову і будувати на ній фрази. Здатність застосовувати і розуміти природну мову являється фундаментальним аспектом інтелекту людини, а її успішна автоматизація привела б до невимірної ефективності комп'ютерів.
7.1. Програма SHRDLU
Однією з перших програм, яка розуміла природну мову і могла “розмовляти” про просте взаємне розташування блоків різної форми і кольору, була програма SHRDLU. SHRDLU могла відповісти на запитання типу: “якого кольору блок на синьому кубику?”, а також виконувати дії виду “пересунь червону пірамідку на зелений брусок”.
7.2. Семантичні мережі
Незважаючи на успіхи, програма SHRDLU не здатна абстрагуватися від світу блоків. Методики представлення, використані в програмі, були досить простими, щоб передати семантичну організацію більш складних предметних областей. Головна частина поточних робіт в області розуміння природних мов направлена на пошук формалізмів представлення, які повинні бути досить загальними, щоб застосовуватися в широкому крузі додатків і уміти адаптовуватися до специфічної структури заданої області. Безліч різноманітних методик (більшість із яких є розвитком або модифікацією семантичних мереж) досліджуються із цією метою й використовуються при розробці програм, здатних розуміти природну мову в обмежених, але досить цікавих предметних областях. Проте повне розуміння мови на обчислювальній основі все ж таки залишається далеко за межами сучасних можливостей.
8. Робототехніка
8.1. Використання великої кількості комбінацій при плануванні
Дослідження в області планування розпочалися зі спроб сконструювати роботів, які могли б виконувати свої задачі з деяким ступенем гнучкості і здатністю реагувати на навколишнє середовище. Планування припускає, що робот повинен уміти виконувати деякі елементарні дії. Він пробує знайти послідовність таких дій, за допомогою яких можна виконати більш складну задачу, наприклад, рухатися по кімнаті, яка містить перешкоди.
По ряду причин планування являється складною проблемою, адже не абияку роль у цьому відіграє розмір простору все можливих послідовних кроків. Навіть досить простий робот здатний створити велику кількість різних комбінацій елементарних рухів. Уявіть собі робота, який може рухатися вперед, назад, вліво, вправо, і уявіть також, скількома різними шляхами він може рухатися по кімнаті. Але, якщо у кімнаті є перешкоди, то роботу потрібно оптимальним способом вибрати шлях навколо них. Для написання програми, яка могла б розумно визначити найкращий шлях із всіх допустимих, і при цьому не була б переповненою їхньою великою кількістю, потрібні складні методи для представлення простору знань і управління в просторі альтернатив.
8.2. Ієрархічна декомпозиція задачі
Одним із методів, який застосовується людиною при плануванні, є ієрархічна декомпозиція задачі (hierarchical problem decomposition). Наприклад, плануючи мандрівку в Лондон, ви, перш за все, займетесь окремими проблемами організації перельоту, поїздкою до аеропорту, самим перельотом і пошуком потрібного виду транспорту в Лондоні, хоча всі ці проблеми являються частиною великого загального плану. Кожна із цих задач може бути розбита на підзадачі, наприклад, купівля карти міста і т.д. Такий підхід не тільки обмежує розмір простору пошуку, але і дозволяє зберігати використовувані маршрути для подальшого застосування.
В той час, як люди розробляють плани дій без всяких зусиль, створення комп’ютерної програми, яка б займалася тим же – проблема. Здавалося б досить проста річ, як розбиття задачі на незалежні підзадачі, але насправді потрібно витончених евристик і знань в області планування. Не менш складна проблема – визначити, які плани потрібно зберегти і як їх узагальнити для використання в майбутньому.
8.3. Організація планування, яка дозволяє реагувати на зміни в навколишньому середовищі
Робот, який насліпо виконує послідовність дій, не реагуючи при цьому на зміни у своєму оточенні або не здатний виявляти і виправляти помилки у власному плані, навряд чи може вважатися розумним. Переважно від робота потребують створити план, заснований на недостатній інформації, і відкоректувати свою поведінку по мірі його виконання. Такий робот повинен розпочати рухатися по кімнаті, ґрунтуючись на сприйнятих даних, і коректувати свій шлях по мірі того, як виявляються інші перешкоди. Організація планів, що дозволяють реагувати на зміни умов зовнішнього середовища, – основна проблема планування.
8.4. Агентно-орієнтовані прийняття рішень
Робототехніка була однією з областей досліджень ШІ, що дала початок багатьом концепціям, які лягли в основу агентно-орієнтованого прийняття рішень. Дослідники, які отримали невдачі при вирішенні проблем, пов’язаних з великими просторами представлень і розробкою алгоритмів пошуку для традиційного планування, переформулювали задачу в термінах взаємодії півавтономних агентів. Кожний агент відповідає за свою частину завдання і загальне рішення виникає в результаті їх скоординованих дій.
9. Мови і середовища штучного інтелекту
9.1. Методи структурування знань
При дослідженні ШІ важливими результатами стали досягнення у сфері мов програмування і досягнення в середовищах розробки програмного забезпечення. Мови, розроблені для програмування ШІ, тісно пов’язані з теоретичною частиною даної області
Засоби програмування включають такі методи структурування знань, як об’єктно-орієнтоване програмування і каркаси експертних систем. Такі високорівневі мови програмування як LISP і PROLOG забезпечують модульну розробку, допомагають справитися з розмірами і складністю програм. Без подібних методик та інструментів навряд чи вдалося побудувати багато відомих систем штучного інтелекту. На даний момент багато алгоритмів ШІ реалізуються на традиційних для обчислювальної техніки мовах C++ і Java.
9.2. Високорівневі мови програмування
9.2.1. PROLOG
PROLOG – найбільш відомий приклад мови логічного програмування (logic programming). Сама назва цієї програми розшифровується як Programming in Logic (Програмування в логіці). Перша PROLOG-програма була написана на початку 1970-х років у Франції в рамках проекту щодо розуміння природної мови. PROLOG базується на теорії предикатів першого порядку. При виконанні програми інтерпретатор постійно реалізовує вивід на основі логічних специфікацій. Ідея використання можливості представлення теорії предикатів першого порядку – одна з головних переваг застосування мови PROLOG в комп’ютерних науках і зокрема в ШІ.
9.2.2. LISP
LISP – одна з найдавніших мов програмування, яка на даний момент знаходиться в користуванні. Вперше дана мова була запропонована Джоном Маккарті в кінці 50-х років. Спочатку LISP розглядався як альтернативна модель обрахунків на основі теорії рекурсивних функцій.
Основним структурним блоком даної програми являється список. (Звідси і абревіатура LISP – Lisp Processing або опрацювання списків). LISP підтримує велику кількість вбудованих функцій для роботи зі списками як зв’язними структурами.
10. Машинне навчання
Навчання є одним із головних складових розумової поведінки. Експертна система може виконувати довгі і складні обрахунки для вирішення певних задач. Але, якщо системі дати одну і ту ж задачу чи подібну їй в другий раз, то на відміну від людей, вона не “пригадає” рішення, а кожний раз знову і знову буде виконувати ті ж обрахунки – навряд чи це подібне на розумову поведінку.
10.1. Автоматизований математик
Хоча навчання є важкою областю, але існують деякі програми, які заперечують побоювання про її неприступність.
Однією з таких є програма АМ – Автоматизований Математик, розроблений для відкриття математичних законів. Відштовхуючись від закладених у нього понять і аксіом теорії множин, Математику вдалося вивести із них такі важливі математичні концепції, як потужність множин і багато інших результатів теорії чисел. АМ формулював теореми, модифікуючи власну базу знань і використовуючи при цьому евристичні методи для пошуку альтернативних теорем із можливих множин.
Також можна відмітити програму Коттона, яка створює “цікаві” цілочисельні послідовності.
10.2. Алгоритм ID3.
Вагомий внесок зробили дослідження Уінстона щодо таких структурних понять як побудова “арок” із набору “світу блоків”. Алгоритм ID3 призначений для виділення загальних принципів з різних прикладів.
10.3. Meta-DENDRAL
Система Meta-DENDRAL в органічній хімії виводить правила інтерпретації спектрографічних даних, використовуючи інформацію про речовини з відомою структурою.
10.4. Інтелектуальний інтерфейс Teiresias
Система Teiresias – інтелектуальний “інтерфейс” для експертних систем – перетворює повідомлення на мові високого рівня в нові правила своєї бази знань.
Програма Hacker будує плани для маніпуляцій в “світі блоків” за допомогою ітеративного процесу створення плану, його випробування і корекції виявлених недоліків.
Успішність програм машинного навчання наводить на думку про існування універсальних принципів, відкриття яких позволило б конструювати програми, що здатні навчатися в реальних проблемних областях.
11. Нейронні мережі
Інтелектуальні системи на основі штучних нейронних мереж дозволяють з успіхом вирішувати проблеми розпізнавання образів, виконання прогнозів, оптимізації асоціативної пам'яті і керування. Традиційні підходи до рішення цих проблем не завжди надають необхідної гнучкості і багато застосувань виграють від використання нейронних мереж.
Штучні нейронні мережі є електронними моделями нейронної структури мозку, який, головним чином, навчається з досвіду. Природній аналог доводить, що множина проблем, які поки що не підвладні розв'язуванню наявними комп'ютерами, можуть бути ефективно вирішені блоками нейронних мереж.
Тривалий період еволюції додав мозку людини багато якостей, що відсутні в сучасних комп'ютерах з архітектурою фон Неймана. До них відносяться:
розподілене представлення інформації і паралельні обчислення;
здатність до навчання й узагальнення;
адаптивність;
толерантність до помилок
низьке енергоспоживання.
Прилади, побудовані на принципах біологічних нейронів, мають перелічені характеристики, що можна вважати суттєвим здобутком у індустрії обробки даних.
Досягнення в галузі нейрофізіології надають початкове розуміння механізму природного мислення, де збереження інформації відбувається у вигляді образів, деякі з яких є складними. Процес зберігання інформації як образів, використання образів і вирішення поставленої проблеми визначають нову галузь в обробці даних, яка, не використовуючи традиційного програмування, забезпечує створення паралельних мереж та їх навчання.
Лекція 3. Системи ШІ, які базуються на знаннях
1. Представлення знань
1.1. Гіпотеза про фізичну символьну систему
1.2. Абстракція
1.3. Виразність. Ефективність
1.4. Приклад представлення числа 
1.5. Масив
1.5.1. Цифрове зображення хромосоми людини на стадії метафази
2. Критерії оцінки систем представлення знань
3. Схеми представлення знань
4. Необхідні властивості мови представлення штучного інтелекту.
5. Приклад опису задачі “світу блоків”
5.1. Обробка знань виражених в якісній формі
5.2. Логічне отримання нових знань з набору фактів і правил.
5.3. Відображення загальних принципів разом з конкретними ситуаціями.
6. Передача складних семантичних значень
6.1. Приклад опису семантичної мережі для канарейки
7. Семантичні мережі
7.1. Означення семантичної мережі
8. Судження на метарівні
8.1. Теорія Рассела
1. Представлення знань
1.1. Гіпотеза про фізичну символьну систему
Ньюелл (Newell) і Саймон (Simon) стверджують, що інтелектуальна діяльність як людини так і машини здійснюється з використанням наступних засобів:
1. Символьні шаблони (комбінація символів), призначені для опису важливих аспектів області призначення задач.
2. Операції з цими шаблонами, що дозволяють генерувати потенціальні вирішення проблем.
3. Пошук з метою вибору розв'язку із числа всіх можливих.
Описані припущення формулюють базис гіпотези про фізичну символьну систему (physical symbol system hypothesis). Ця гіпотеза лежить в основі спроб створення розумних машин і робить очевидними основні припущення в дослідженні штучного інтелекту. Гіпотеза про фізичну символьну систему неявно розрізняє поняття шаблонів (patterns), сформованих шляхом упорядкування символів і середовища (medium), в якому вони реалізовані. Якщо рівень інтелекту визначається виключно структурою системи символів, то будь-яке середовище, яке успішно реалізовує правильні шаблони і процеси, досягне цього рівня інтелекту, незалежно від того, складене воно із нейронів, логічних ланцюгів чи це просто механічна іграшка. Можливість побудови машини, яка б пройшла тест Т’юрінга, залежить від вищезгаданого розмежування. Згідно тези Черча комп’ютери здатні реалізувати довільний ефективно описаний процес обробки символьної інформації. Хіба з цього не слідує, що певним чином запрограмований цифровий комп’ютер володіє інтелектом?
Гіпотеза про фізичну символьну систему також коротко описує головні питання щодо дослідження в області штучного інтелекту: визначення структур символів і операцій необхідних для інтелектуального рішення задачі, а також розробка стратегій для ефективного і правильного пошуку потенційних рішень генерованих цими структурами і операціями. Ці взаємопов’язані проблеми представлення знань і пошуку (knowledge representation and search) лежать в основі сучасних досліджень в області штучного інтелекту.
Гіпотеза про фізичну символьну системуобговорюється критиками, які стверджують, що інтелект являється спадково біологічним і екзистенціальним і не може бути зафіксований за допомогою символів. Незважаючи на все, припущення гіпотез фізичної символьної системи лежать в основі майже всіх практичних і теоретичних робіт в експертних системах, в плануванні і розумінні природної мови.
1.2. Абстракція
Призначення будь-якої схеми представлення полягає в тому, щоб зафіксувати специфіку області визначення задачі і зробити цю інформацію доступною для механізму вирішення проблеми. Очевидно, що мова представлення повинна дозволяти програмісту виражати знання, необхідні для рішення задачі.
Абстракція (abstraction), тобто представлення тільки тієї інформації, яка являється необхідною для досягнення заданої цілі, являється необхідним засобом керування складними процесами. Крім того, кінцеві програми повинні бути раціональними в обчислювальнім відношенні.
1.3. Виразність. Ефективність
Виразність і ефективність є взаємопов’язаними характеристиками оцінки мов представлення знань. Багато засобів ефективних в одних задачах, зовсім не ефективні в других. Деколи виразністю можна пожертвувати на користь ефективності. В той час не можна обмежувати можливості такого відображення, яке дозволяє фіксувати істинні знання, що приводить до ефективного рішення конкретної задачі. Розумний компроміс між ефективністю і виразністю – нетривіальна задача для розробників інтелектуальних систем.
Мови представлення знань являються засобом, що дозволяє рішати задачі. По суті, спосіб представлення знань повинен забезпечити природну структуру його вираження, що дозволяє вирішити проблему. Спосіб представлення повинен зробити це знання доступним комп’ютеру і допомогти програмісту описати його структуру.
1.4. Приклад представлення числа
Розглянемо приклад представлення числа на комп’ютері (мал.1), використовуючи відомі способи. В загальному, для повного опису даного числа потрібно нескінченний ряд цифр, що не може бути виконано на машині зі скінченним числом станів. Єдиний розв’язок даної дилеми – представлення числа у вигляді двох частин: його значущих цифр і положення десяткової крапки в межах цих цифр. Створимо представлення числа , яке функціонувало б в більшості практичних додатках.
Число
Десятковий еквівалент 3,1415927…
 Представлення з плаваючою крапкою
Представлення з плаваючою крапкою
 |  |
Мантиса Експонента
Представлення в пам’яті комп’ютера 11100010
Мал.1. Різні представлення числа
Представлення числа уступає у виразності, але виграє в ефективності. Таке представлення дозволяє виконувати багатократні арифметичні операції, забезпечує ефективність їх виконання, дозволяє аналізувати помилки округлення. Подібно всім представленням, це лише абстракція, символьний шаблон, визначаючий бажаний логічний об’єкт, але безпосередньо не сам об’єкт.
1.5. Масив
Масив – ще одне представлення, прийняте в теорії обчислювальних систем. Для багатьох задач воно більш природне і ефективне, ніж архітектура пам’яті, реалізована в апаратних засобах. Це представлення уступає у виразності, що наглядно показано на наступному прикладі обробки зображення.
1.5.1. Цифрове зображення хромосоми людини на стадії метафази
На (мал.2) дано цифроване зображення хромосом людини на стадії метафази. В процесі обробки зображення визначається номер і структура хромосоми, виявляються розриви, відсутні фрагменти та інші аномалії.

Мал.2. Цифроване зображення хромосом людини на стадії метафази
Візуальна картина складається з точок зображення. Кожна точка чи піксель характеризується розміщенням і числовим значенням, що представляють рівень сірого кольору. Тому всю картину природно представити у вигляді двомірного масиву, де номер рядка і стовпчика елементу масиву визначає місце розміщення пікселя (координати X і Y), а сам елемент масиву – рівень сірого кольору в даній точці. Для обробки даного зображення потрібно реалізувати такі операції, як пошук ізольованих точок для видалення шуму, знаходження граничних рівнів для розпізнання об’єктів і їх меж, сумування неперервних елементів для визначення розмірів і щільності образів. Потім отримані дані можуть бути перетворені. Цей алгоритм зручно програмувати на мові FORTRAN, в якій безпосередньо реалізовані операції з масивами.
Масиви пікселей не можуть достатньо точно відображати семантичну організацію образа. Наприклад, масив пікселей не може представити організацію хромосом в окремому ядрі клітки, їх генетичну функцію чи роль метафази в поділі клітки. Ці знання легко фіксувати, використовуючи такі поняття, як вирахування предикатів чи семантичні мережі.
2. Критерії оцінки систем представлення знань
3. Схеми представлення знань
Схема представлення знань повинна задовольняти наступним умовам:
1. Адекватно виражати всю необхідну інформацію.
2. Підтримувати ефективне виконання кінцевого коду.
3. Забезпечувати природний спосіб вираження потрібних знань.
4. Необхідні властивості мови представлення штучного інтелекту
Загалом кажучи, задачі штучного інтелекту не вирішуються шляхом їх спрощення чи “підгнанням” до уже існуючих понять, які пропонуються традиційними формальними системами, наприклад, масивами. Ці задачі скоріш за все пов’язані з якісними, а не кількісними проблемами, з аргументацією, а не обчисленнями, з організацією великих об’ємів знань, а не реалізацією окремого чіткого аргументу. Щоб задовольнити цим потребам, мова представлення штучного інтелекту повинна володіти наступними властивостями:
1. Опрацьовувати знання, виражені в якісній формі.
2. Отримувати нові знання із набору фактів і правил.
3. Відображати загальні принципи і конкретні ситуації.
4. Передавати складні семантичні значення.
5. Забезпечувати судження на метарівні.
Розглянемо ці властивості більш детально.
5. Приклад опису задачі “світу блоків”
5.1. Обробка знань виражених в якісній формі
Програмування штучного інтелекту потребує засобів фіксації (вираження) і міркувань про якісні аспекти задачі. Розглянемо простий приклад – розміщення блоків на столі (мал.3).

Мал.3. “Світ блоків”
Для представлення розміщення блоків можна використовувати декартову систему координат, де значення X і Y задають координати кожної вершини блоку. Хоча цей підхід описує світ блоків і являється правильним представленням для багатьох задач, в даному випадку він невдалий, оскільки не дозволяє зафіксувати властивості і відношення, необхідні для якісних висновків, таких як, які з блоків покладені один на одного і які мають відкритий верх, щоб можна було їх взяти і підняти.
Вирахування предикатів (predicate calculus) безпосередньо фіксує цю наглядну інформацію. У вирахуванні предикатів світ блоків може бути описаний логічними твердженнями:
clear(c)
clear(a)
ontable(a)
ontable(b)
on(c, b)
cube(b)
cube(a)
pyramid(c)
Перше слово кожного виразу (on, clear і т.д.) – предикат (predicate), що означає деякі властивості чи відношення параметрів, поданих в круглих дужках. Параметри – це символи, що означають об’єкти (блоки) у предметній області. Сукупність логічних пропозицій описує важливі властивості і відношення світу блоків.
5.2. Логічне отримання нових знань з набору фактів і правил
Довільний інтелектуальний об’єкт повинен володіти здатністю логічно отримувати додаткові знання з наявного опису реального світу. Наприклад, люди не запам’ятовують точний опис кожної пережитої ситуації. Скоріш ми здатні обдумувати про абстрактні описи об’єктів і стани.
В прикладі із світу блоків можна визначити тест, що встановлює, чи являється блок відкритим, тобто чи не має на його верхній грані другого об’єкту. Це важливе питання для робототехнічної системи, в якій рука робота повинна піднімати блоки і вкладати їх один на одного. Цю властивість не обов’язково явно приписувати кожному блоку. Можна визначити загальне правило, яке дозволяє системі робити логічні виводи із наявних фактів. В обчисленні предикатів це правило може виглядати так 
Воно означає наступне: для довільного елементу X елемент X являється відкритим, якщо не існує такого Y, що Y знаходиться на X . Це правило може застосовуватися в різних ситуаціях при заміні значень X і Y. Обчислення предикатів надає великі зручності при вираженні знань, дає можливість проектувати гнучкі і достатньо загальні системи, які уміють діяти розумно в різних ситуаціях.
Нейронні мережі також виводять нові знання із наявних фактів, хоча правила, які використовуються ними, скриті. Класифікація – це загальноприйнята форма логічного виводу, яка виконується такими системами. Наприклад, нейронну мережу можна навчити розпізнавати всі конфігурації блоків, в яких піраміда розміщується зверху блоку, який має форму куба.
5.3. Відображення загальних принципів разом з конкретними ситуаціями
На прикладі з блоками було показано, як використовуються змінні в обчисленні предикатів. Оскільки інтелектуальна система повинна бути максимально доступною, довільна мова програмування потребує змінні. Необхідність якісних суджень робить використання і реалізацію змінних надзвичайно важкою і витонченою задачею у порівнянні з трактуваннями в традиційних мовах програмування. Значення, типи і правила обробки даних мовами програмування, орієнтованих на обчислення, надзвичайно обмежені і не придатні для реалізації інтелектуальних систем. Для обробки зв’язаних змінних і об’єктів існують спеціальні мови представлення знань. Висока здатність узагальнення – це ключова властивість нейронних мереж, систем навчання та інших адаптивних систем. Ефективне навчання системи-агента полягає в тому, щоб навчитися узагальнювати дані, отримані в процесі такого навчання, а потім правильно застосувати отримання знання в нових ситуаціях.
6. Передача складних семантичних значень
В багатьох областях штучного інтелекту рішення задачі потребує використання високо структурованих взаємозв’язаних знань. Наприклад, щоб описати автомобіль, недостатньо перерахувати його складові частини. Адекватний опис повинен враховувати також спосіб з’єднання і взаємодії цих частин. Структурне представлення необхідне в багатьох задач, починаючи з таких таксономічних систем, як система класифікації рослин по видм і родам, і закінчуючи засобами опису таких складних об’єктів, як дизельний двигун чи тіло людини в термінах, які є складовими їх частин. В прикладі блоків основою повного опису розміщення була взаємодія предикатів.
Семантичні відношення також необхідні для опису причинних зв’язків між подіями. Вони дозволяють зрозуміти прості розповіді, наприклад, дитячі казки, чи подати план дій робота як послідовність елементарних дій, які повинні бути виконані у визначеному порядку.
Хоча всі ці ситуації можуть бути представлені у вигляді сукупності предикатів чи адекватних їм формалізм ах, для програміста, який має справу зі складними поняттями, який прагне дати стійкий опис процесів у програмі, необхідне деяке високорівневе представлення структури процесу.
6.1. Приклад опису семантичної мережі для канарейки
Наприклад, канарейку можна описати так. Канарейка – це маленька жовта пташка, а пташка – це крилата літаюча хребетна істота. Це формулювання може бути представлене у вигляді набору логічних предикатів:
hassize(canary, small)
hascovering(bird, feathers)
hascolor(canary, yellow)
hasproperty(bird, files)
isa(canary, bird)
isa(bird, vertebrate)
Предикатний опис можна представити графічно, використовуючи для відображення предикатів, які визначають відношення, дуги (arc) чи зв’язки (link) (Мал.4)

Мал.4. Опис семантичної мережі для канарейки
Такий опис називається семантичною мережею (semantic network) і являється фундаментальною методикою представлення семантичного значення. В даному прикладі системі потрібно слідувати тільки по двох дугах, щоб рішити, що канарейка – це хребетна істота. Це значно ефективніше, ніж пошук в базі даних, який містить опис на мові обрахунків предикатів типу isa(X, V).
Крім того, знання можуть бути організовані так, щоб відображати природну структуру експонента класу із даної предметної області. Деякі зв’язки, наприклад, isa див.мал.5., вказують на належність до класу і задають властивості, які характерні для опису даного класу, які наслідують всі члени класу. Механізм наслідування безпосередньо вбудований в мову і дозволяє зберігати знання на найвищому рівні абстракції. Наслідування – інструмент представлення таксономічної (класифікованої) структурованої інформації, який гарантує, що всі члени класу володіють загальними властивостями.
7. Семантичні мережі
7.1. Коротка історія розвитку семантичних мереж
Термін "семантична мережа " (або "концепція слів") виник в 1968-69 рр. у роботах Р. Куілліана. Він має на увазі цілий клас загальних підходів, для яких характерно використання графічних схем з вузлами, з'єднаними дугами (графів ). Особливість полягає в тому, що в теорії семантичних мереж розглядаються циклічні і пов’язані графи.
Спочатку семантичні мережі були розроблені для аналізу природних мов і побудови психологічних моделей людської пам'яті (завдання автоматичного перекладу - положення Арістотеля про те, що "людина мислить мовою", завдання добору синонімів до заданого слова й ін.). На цьому етапі вважалося, що в пропозиції є якась "центральна тема", "розкрутивши" яку, машина може "зрозуміти" зміст (семантику) пропозиції.
Подальший розвиток моделі пов'язаний з іменами Р. Сіммонса (Robert Sіmmons), С. Шапиро (Stuart С. Shapіro, звернув увагу на наявність "відносин різного роду"), Хенд- рікса (Hendrіx, увів поняття "розділеної мережі /partіtіoned network") і Шенка (Roger С. Schank, увів поняття "концептуальної залежності.
7.2. Означення семантичної мережі
Семантична мережа — інформаційна модель предметної області, що має вигляд орієнтованого графа, вершини якого відповідають об'єктам предметної області, а ребра задають відносини між ними. Об'єктами можуть бути поняття, події, властивості, процеси. У семантичній мережі роль вершин виконують поняття бази знань, а дуги (причому направлені) задають відношення між ними.
Таким чином, семантична мережа є одним із способів представлення знань, відображає семантику предметної області у вигляді понять і відносин між ними.
Теорія графів ефективно і природно виражає складні семантичні знання. Крім того, вона дозволяє описувати структурну організацію бази знань. Семантичні мережі – це достойна альтернатива обчислення предикатів.
Можливо, найбільш важливою властивістю семантичної мережі є здатність описувати семантичні значення для систем розуміння природної мови. Наприклад, якщо необхідно зрозуміти дитячу казку, статтю в журналі чи зміст Web-сторінки, то у відповідній прикладній програмі потрібно закодувати семантичну інформацію і відношення, які відображають знання. Семантичні мережі – потрібний для цього механізм.
7.3. Види семантичних мереж
Мережі різного виду отримуються залежно від того, які обмеження накладають на вершини й дуги. Якщо вершини мережі не мають внутрішню структуру, то такі мережі називають простими мережами, якщо вершини мають внутрішню структуру, то такі мережі називають ієрархічними. Динамічні семантичні мережі (сценарії) – мережі з подіями. Одне з основних відмінностей ієрархічної мережі від простої мережі полягає у можливості розділяти мережі на підмережі й встановлювати відношення не тільки між вершинами, але і між підмережами. Різні підмережі, що існують у мережі, можуть бути впорядковані у вигляді дерева під мереж, вершини якого – підмережі, а дуги – відносини видимості. Поняття підмережі аналогічно поняттю дужок у математичній нотації, поняття видимості – поняттю змінної, що перебуває усередині й зовні дужок .
8. Судження на метарівні
Інтелектуальна система повинна не тільки знати сам предмет, але також знати про те, що саме вона знає про цей предмет. Вона повинна уміти рішати задачі і пояснювати ці рішення, описувати свої знання як в конкретних так і в загальних термінах, взнавати їх обмеження і вчитися в процесі взаємодії з навколишнім середовищем. Ця “усвідомленість своїх знань” становить більш високий рівень знань, названий метазнаннями, необхідними для проектування і адекватного опису інтелектуальних систем.
8.1. Теорія Рассела
Проблему формалізації метазнань вперше досліджував Бертран Рассел (Russell) в своїй теорії логічних типів. Коротко її описати можна так: якщо множини можуть бути складовими других множин, то можуть існувати множини, які являються складовими самих себе. Згідно теорії Рассела це призводить до нерозв’язних парадоксів. Рассел відкинув ці парадокси, класифікуючи множини як ті, що відносяться до різних типів, в залежності від того, містять вони окремі елементи чи множини елементів і т.д. Множини не можуть бути членами множин, що відносяться до типу меншого чи рівного значення. Це відповідає різниці між знаннями і метазнаннями. Але при спробі описати ці судження Рассел зіткнувся з багатьма труднощами.
Здатність навчатися на прикладах, досвіді чи розуміти інструкції високого рівня залежить від застосування метазнань. Методи представлення знань, розроблені для програмування задач штучного інтелекту, забезпечують можливість адаптації і модифікації, необхідних для систем, що навчаються, і формують основу для подальших досліджень.
Лекція 4. Моделі рішення задач
1. Класифікація представлення задач
1.1. Логічні моделі
1.1.1. Предметна область
1.1.2. Сутності
1.1.3. Клас сутності
1.1.4. Судження
1.1.5. Мова представлення знань
1.1.6. Логічна модель
1.2. Мережеві моделі
1.2.1. П-сутність
1.2.2. М-сутність
1.2.3. Семіотичні моделі проблемних областей
1.2.4. Денотативна семантика
1.2.5. Конотативна семантика
1.2.6. Десигнат
1.2.7. Термінальний об’єкт
1.2.8. Семантика термінальних об’єктів
1.3. Продукційні моделі
1.3.1. Поняття продукції
1.3.2. Вираз продукції
1.3.3. Ім’я продукції і
1.3.4. Сфера застосування продукції Q
1.3.5. Ядро продукції A  B
B
1.3.6. Умова застосування ядра продукції P
1.3.7. Післяумови продукції N
1.3.8. Система продукцій
2. Сценарії
2.2. Сценарії
2.1. Стереотипні знання
3. Інтелектуальний інтерфейс
3.1. Класифікація рівнів розуміння
3.1.1. Перший рівень розуміння
3.1.2. Другий рівень розуміння
3.1.3. Третій рівень розуміння
3.1.4. Четвертий рівень розуміння
3.1.5. П’ятий рівень розуміння
3.1.5.1. Мовний акт
3.1.5.2. Локуція
3.1.5.3. Іллокуція
3.1.5.4. Перлокуція
3.1.6. Перший метарівень
3.1.7. Другий метарівень
4. Структурна схема реалізації рівнів розуміння
1. Класифікація представлення задач
1.1. Логічні моделі
Постановка і рішення будь-якої задачі завжди пов’язані з її “зануренням” в потрібну предметну область. Наприклад, вирішуючи задачу щодо складання розкладу обробки деталей на метало ріжучих станках, ми втягуємо в предметну область такі об’єкти, як конкретні станки, деталі, інтервали часу, і загальні поняття “станок”, “деталь”, “тип станка” і т. д.
1.1.1. Предметна область
Усі предмети і події, що складають основу загального розуміння необхідної для рішення задачі інформації, називаються предметною областю.
1.1.2. Сутності
Сутності – це реальні чи абстрактні об’єкти, з яких уявно складається предметна область. Сутності предметної області знаходяться у визначених відносинах одна з одною (асоціаціях), які також можна розглядати як сутності і включати в предметну область.
1.1.3. Клас сутності
Сукупність подібних сутностей складає клас сутностей, що є новою сутністю предметної області.
Відносини між сутностями виражаються за допомогою суджень.
1.1.4. Судження
Судження – це уявно можлива ситуація, що може мати місце для пропонованих сутностей чи не мати місця. У мові (формальній чи природній) судженням відповідають пропозиції. Судження і пропозиції також можна розглядати як сутності і включати в предметну область.
1.1.5. Мови представлення знань
Мови, призначені для опису предметних областей, називаються мовами представлення знань. Універсальною мовою представлення знань є природна мова. Проте використання природної мови в системах машинного представлення знань наштовхується на великі труднощі. Але головна перешкода заклечається у відсутності формальної семантики природної мови, яка мала б достатньо ефективну операційну підтримку.
Для представлення математичного знання в математичній логіці давно користуються логічними формалізмами – в основному обчисленням предикатів, що має ясну формальну семантику і операційну підтримку. Тому обчислення предикатів було першою логічною мовою, яку застосовували для формального опису предметних областей, пов’язаних з рішенням прикладних задач.
1.1.6.Логічна модель
Описи предметних областей, виконані в логічних мовах, називаються (формальними) логічними моделями.
1.2. Мережеві моделі
Введемо ряд означень. Під сутністю будемо розуміти об’єкт довільної природи. Цей об’єкт може існувати в реальному світі.
1.2.1. П-сутності
Під П-сутностю будемо розуміти об’єкт довільної природи, який може існувати в реальному світі.
1.2.2. М-сутності
У базі знань об’єкту довільної природи відповідає деякий опис, повнота якого визначається тією інформацією, що має про П-сутність інформаційна система. Таке представлення в базі знань називається М-сутністю.
1.2.3. Семіотичні моделі проблемних областей
Поділ сутностей на два типи дозволяє використовувати в мережевих моделях ідеї, які вперше були сформульовані в теорії семіотичних моделей і заснованому на них ситуаційному управлінні. Під семіотичними моделями проблемних областей будемо розуміти комплекс процедур, що дозволяють відображати в базі знань П-сутності і їхні зв’язки, зафіксовані в проблемній області інженером по знаннях, у сукупності пов’язаних між собою М-сутностей.
1.2.4. Денотативна семантика
Спосіб інтерпретації взаємозалежних П-сутностей буде називатися денотативною семантикою.
1.2.5. Конотативна семантика
Спосіб інтерпретації взаємозалежних М-сутностей називається конотативною семантикою.
1.2.6. Десигнат
Десигнат – це найпростіший елемент у мережевій моделі. Він входить в клас термінальних об’єктів мережевої моделі.
1.2.7. Термінальний об’єкт
Термінальним об’єктом називається М-сутність, що не може бути розкладена на більш прості сутності. Інші М-сутності називаються похідними об’єктами чи похідними М-сутностями. Приклад термінальних об’єктів: цілі числа, ідентифікатори, рядки, списки і т.п.
1.2.8. Семантика термінальних об’єктів
Семантика термінальних об’єктів визначається набором припустимих процедур, що оперують з ними, наприклад, арифметичні дії над числами, порівняння між собою рядків чи ідентифікаторів, операції введення-висновку, що включають необхідні трансформації представлень і т.д.
1.3. Продукційні моделі
1.3.1. Поняття продукції
Продукції разом з фреймами є найбільш популярними засобами представлення знань в ІС. З одного боку продукції близькі до логічних моделей. Це дозволяє організовувати ефективні процедури виводу. З другого боку продукції більш наочно відображають знання, ніж класичні моделі. У них відсутні обмеження, що характерні для логічних обрахунків, що дає можливість змінювати інтерпретацію елементів продукції.
1.3.2. Вираз продукції
У загальному вигляді під продукцією розуміється вираз наступного вигляду:
(і); Q; P; A B; N.
1.3.3. Ім’я продукції і
і – ім’я продукції, за допомого якого дана продукція виділяється з усієї множини продукції. В якості імені може виступати деяка лексема, що відображає суть даної продукції (наприклад, “покупка книги” чи “набір коду замка”), чи порядковий номер продукції в їхній множині, що зберігається в пам’яті системи.
1.3.4. Сфера застосування продукції Q
Q – характеризує сферу застосування продукції. Такі сфери легко виділяються в когнітивних структурах людини. Наші знання як би “розкладені по поличках”. На одній “поличці” зберігаються знання про те, як потрібно готувати їжу, на другій – як добратися до роботи і т.д. Поділ знань на окремі сфери дозволяє економити час на пошук потрібних знань.
1.3.5. Ядро продукції A B
Головним елементом продукції являється її ядро: A B. Інтерпретація ядра продукції може бути різною і залежить від того, що стоїть ліворуч і праворуч від знаку секвенції . Звичайне прочитання ядра продукції виглядає так: ЯКЩО А, ТО В.
Більш складніші конструкції ядра допускають в правій частині альтернативний вибір, наприклад, ЯКЩО А, ТО В1, ІНАКШЕ В2. Секвенція може тлумачитися в звичайному логічному змісті як знак логічного слідування В із істинного А (якщо А не являється істинним виразом, то про В нічого сказати не можна). Можливі інші інтерпретації ядра продукції, наприклад А описує деяку умову, необхідну для того, щоб можна було б здійснити дію В.
1.3.6. Умова застосування ядра продукції P
Елемент Р – умова застосування ядра продукції. Звичайно Р являє собою логічний вираз (як правило, предикат). Коли Р приймає значення “істина”, ядро продукції активізується. Якщо Р хибне, то ядро продукції не може бути використане. Наприклад, якщо в продукції “НАЯВНІСТЬ ГРОШЕЙ; ЯКЩО ХОЧЕШ КУПИТИ РІЧ Х, ТО ЗАПЛАТИ В КАСУ ЇЇ ВАРТІСТЬ І ВІДДАЙ ЧЕК ПРОДАВЦЮ” умова застосування ядра продукції хибна, тобто нема грошей, то застосувати ядро продукції неможливо.
1.3.7. Післяумови продукції N
Елемент N описує післяумови продукції. Вони актуалізуються тільки в тому випадку, якщо ядро продукції реалізувалося. Післяумови продукції описують дії і процедури, які необхідно виконати після реалізації В. Наприклад, після купівлі деякої речі в магазині, необхідно в описі товарів, які є в даному магазині, зменшити кількість речей такого типу на одиницю. Виконання N можевідбуватися не зразу після реалізації ядра продукції.
1.3.8. Система продукцій
Якщо в пам’яті системи зберігається деякий набір продукцій, то вони утворюють систему продукцій. В системі продукцій повинні бути задані спеціальні процедури управління продукція ми, за допомогою яких відбувається актуалізація продукції із числа актуалізованих.
У ряді ІС використовуються к комбінації мережевих і продукційних моделей представлення знань. У таких моделях декларативні знання описуються в мережевому компоненті моделі, а процедурні знання – продукційному.
2. Сценарії
2.1. Стереотипні знання
Важливу роль в системах представлення знань відіграють стереотипні знання, які описують відомі стандартні ситуації реального світу. Такі знання дозволяють відновлювати інформацію, пропущену в описі ситуації, передбачити появу нових фактів, які можна очікувати в даній ситуації, установлювати зміст походження ситуації з погляду більш загального ситуативного контексту.
2.2. Сценарії
Для опису стереотипного знання використовуються різні моделі. Серед них найбільш поширеними являються сценарії.
Сценарієм називається формалізований опис стандартної послідовності взаємозалежних фактів, що визначають типову ситуацію предметної області. Це можуть бути послідовності дій чи процедур, що описують способи досягнення цілей діючих осіб сценарію (наприклад, обід у ресторані, відрядження, політ літака, вступ у вуз). В ІС сценарії використовуються в процедурах розуміння природно-мовних текстів, планування поведінки, навчання, прийняття рішень, управління змінами середовища та ін.
3. Інтелектуальний інтерфейс
Припустимо, що при вході ІС поступає текст. Будемо вважати, що ІС розуміє текст, якщо вона дає правильні з точки зору людини відповіді на будь-які запитання, які відносяться до того, про що йдеться мова у тексті. Під “людиною” мається на увазі конкретна людина-експерт, якій доручено оцінити здібності системи щодо розуміння. Це вносить долю суб’єктивізму, бо різні люди можуть по-своєму розуміти одні і ті ж тексти.
3.1. Класифікація рівнів розуміння
В існуючих ІС можна виділити п’ять основних рівнів розуміння і два рівня метарозуміння.
3.1.1. Перший рівень розуміння
Перший рівень характеризується схемою, яка показує, що будь-які відповіді на запитання система формує тільки на основі прямого змісту, введеного із тексту. Якщо, наприклад, в систему введений текст: “О 8 годин ранку, після сніданку, хлопчик пішов до школи. О 14 годині він повернувся додому. Після обіду пішов гуляти ”, то на першому рівні розуміння система зобов’язана вміти відповідати вірно на запитання типу: “Коли хлопчик пішов у школу?” або “Що зробив хлопчик після обіду?”. У лінгвістичному процесі відбувається морфологічний, синтаксичний і семантичний аналіз тексту і питань, що відносяться до нього. На виході лінгвістичного процесора отримуємо внутрішнє представлення тексту і питань, з якими може працювати блок висновку. Використовуючи спеціальні процедури, цей блок формує відповіді. Вже на першому рівні вимагає від ІС визначених засобів представлення даних і висновку на цих даних.
3.1.2. Другий рівень розуміння
На другому рівні добавляються засоби логічного висновку, які базуються на інформації, що міститься в тексті. Це різноманітні логіки тексту (часова, просторова і т.п.), які здатні породжувати інформацію, що явно відсутня в тексті. Для нашого прикладу на другому рівні можливе формування правильних відповідей на запитання типу: “Що було раніше: похід хлопчика в школу чи його обід?” або “Чи гуляв хлопчик після повернення зі школи?”. ІС зможе відповісти на подібні запитання тільки після побудови часової структуру тексту.
Схема ІС, за допомогою якої може бути реалізований другий рівень розуміння, має ще одну базу знань. В ній зберігаються закономірності, які відносяться до часової структури подій, можливої їх просторової організації і т.п., а логічний блок володіє всіма необхідними засобами для роботи з псевдо фізичними логіками.
3.1.3. Третій рівень розуміння
До засобів другого рівня добавляються правила поповнення тексту знаннями системи про середовище. Ці знання в ІС, як правило, носять логічний характер і фіксуються у вигляді сценаріїв чи процедур певного типу. На третьому рівні розуміння ІС повинна дати правильні відповіді на запитання типу: “Де був хлопчик о 10 годині ранку?” або “Звідки хлопчик вернувся о 14 годині дня?”. Для цього потрібно знати, що означає процес “перебування в школі” і, зокрема, що цей процес являється неперервним і що суб’єкт, що бере участь у ньому, весь час знаходиться “в школі”.
Схема ІС, в якій реалізується розуміння третього рівня, ззовні не відрізняється від схеми другого рівня. Проте в логічному блоці повинні бути передбачені засоби не тільки для чисто дедуктивного висновку, але і для висновку по сценаріях.
Три перераховані рівня розуміння реалізовані у всіх практично працюючих ІС. Перший рівень і частково другий входять в різні системи спілкування на природній мові. Наступні два рівні розуміння реалізовані в існуючих ІС лиш частково.
3.1.4. Четвертий рівень розуміння
Замість тексту в ІС використовується розширений текст, що породжується лише при наявності двох каналів одержання інформації. По одному в систему передається текст, по другому – додаткова інформація, яка відсутня в тексті. При комунікації у людини роль другого каналу, як правило, відіграє зір. Більше одного каналу комунікації мають інтелектуальні роботи, які володіють зором.
Зоровий канал комунікації дозволяє фіксувати стан середовища “тут і зараз” і вводити в текст інформацію, що спостерігається. Система стає здатною до розуміння текстів, в які ведені слова, що прямо пов’язані з тою ситуацією, в якій породжується текст. На більш низьких рівнях розуміння не можливо зрозуміти, наприклад, текст: “Подивіться, що зробив хлопчик! Він не повинен був брати це!”.І При присутності зорового каналу процес розуміння стає можливим.
При наявності четвертого рівня розуміння ІС здатна відповідати на запитання типу: “Чому хлопчик не повинен був брати це?” або “Що зробив хлопчик?”. Якщо питання, яке надійшло в систему, відповідає третьому рівню, то система видасть потрібну відповідь. Якщо для відповіді необхідно застосувати додаткову інформацію, то внутрішнє представлення тексту і питання передається в блок, який здійснює співвідношення тексту з тою реальною си