|
|
Достоверность информационного обеспечения
Одним из основных условий эффективного функционирования АСУ является обеспечение требуемого уровня, достоверности информации, на основе которой принимаются управленческие решения.
Под достоверностью информации в АСУ понимают некоторую функцию вероятности ошибки, т.е. события, заключающегося в том, что реальная информация в системе о некотором параметре не совпадает в пределах заданной точности с истинным значением.
Необходимая достоверность достигается использованием различных методов, реализация которых требует введения в системы обработки данных (СОД) информационной, временной или структурной избыточности. Достоверность при обработке данных достигается путем контроля и выявления ошибок в исходных и выводимых данных, их локализации и исправления. Условие повышения достоверности – снижение доли ошибок до допустимого уровня. В конкретных АСУ требуемая достоверность должна устанавливаться с учетом нежелательных последствий, к которым может привести возникшая ошибка, и тех затрат, которые необходимы для ее предотвращения.
Важным этапом выбора и разработки методов и механизмов обеспечения достоверности информации является анализ процессов ее переработки. В ходе анализа изучают структуру обработки данных, строят модели возникновения ошибок и их взаимодействия, рассчитывают вероятности возникновения, обнаружения и исправления ошибок для различных вариантов структур обработки данных и использования механизмов обеспечения требуемого уровня достоверности.
Синтез механизмов обеспечения достоверности осуществляют при техническом и рабочем проектировании АСУ. На этапе синтеза создают технологическую структуру обработки информации, включая выбор методов и механизмов обеспечения достоверности. В качестве критерия используют один из показателей эффективности: максимизация достоверности информации, минимизация затрат на разработку и эксплуатацию систем повышения достоверности и некоторые другие.
Ошибки возникают на любом этапе функционирования АСУ. Их можно разделить на ошибки персонала АСУ и ошибки, вызванные неисправностью технических средств системы.
Ошибки персонала АСУ обусловлены психофизиологическими возможностями человека, объективными причинами (несовершенством моделей представления информации, недостаточной квалификацией персонала, несовершенством технических средств и т.п.) и субъективными причинами (небрежностью, безответственностью некоторых пользователей, преднамеренным искажением информации, плохой организацией труда и т.п.).
Ошибки, вызванные неисправностью технических средств системы, – это ошибки, связанные с неисправностью оборудования, несоответствием его техническим нормам, нарушением необходимых условий работы технических средств и хранения машинных носителей информации, с физическим износом элементов и узлов технических средств, различного рода помехами и т.д.
Иногда выделяют ошибки во входных данных, т.е. ошибки, которые возникают во внешней среде, вне рассматриваемой системы и поступают в нее в составе исходных данных.
Методы повышения достоверности обработки данных. Рассмотрим особенности процессов обработки данных в АСУ и взаимосвязь с этими процессами механизмов возникновения ошибок, контроля обрабатываемых данных и обнаружения ошибок.
При решении задач АСУ осуществляется преобразование  где
где  - множество входных переменных,
- множество входных переменных,  - множество выходных переменных. Преобразование π ставит в соответствие каждой n-й комбинации значений входных переменных
- множество выходных переменных. Преобразование π ставит в соответствие каждой n-й комбинации значений входных переменных  определенную совокупность значений выходных переменных
определенную совокупность значений выходных переменных  Таким образом,
Таким образом,  и π:
и π:  , Di – область определения входной переменной xi, i = =
, Di – область определения входной переменной xi, i = =  , a Fj – область определения выходной переменной уj; j =
, a Fj – область определения выходной переменной уj; j =  .
.
Пусть z – множество промежуточных переменных. Тогда функционирование АСУ представляется в виде ориентированного графа технологии обработки данных, множество вершин V которого соответствует множеству входных, промежуточных и выходных переменных, т.е.  , а множество дуг Е соответствует множеству процедур обработки этих переменных. Переменные и процедуры будем называть элементами графа I(π).
, а множество дуг Е соответствует множеству процедур обработки этих переменных. Переменные и процедуры будем называть элементами графа I(π).
Процедуры обработки реализуются персоналом и техническими средствами, надежность которых не является абсолютной. Пусть R – множество процессов, которые привели к появлению недостоверных исходных данных или вносящих помехи в нормальное функционирование АСУ и приводящих тем самым к появлению недостоверных данных. В этом случае АСУ осуществляет преобразование (π, R):  , где
, где  – область возможных значений переменной уj. Очевидно, что может содержать запрещенные (недостоверные) значения переменной yj. Для задания множества запрещенных значений
– область возможных значений переменной уj. Очевидно, что может содержать запрещенные (недостоверные) значения переменной yj. Для задания множества запрещенных значений  и выявления факта принадлежности конкретных значений выходных переменных к этому множеству используют механизмы контроля. При решении задач АСУ с механизмом контроля Mk осуществляется преобразование М = (π, R, Mk):
и выявления факта принадлежности конкретных значений выходных переменных к этому множеству используют механизмы контроля. При решении задач АСУ с механизмом контроля Mk осуществляется преобразование М = (π, R, Mk):  причем для каждого
причем для каждого  устанавливается:
устанавливается:  или
или  Механизмы контроля используют на различных этапах процесса обработки информации с целью обеспечения ее достоверности.
Механизмы контроля используют на различных этапах процесса обработки информации с целью обеспечения ее достоверности.
Методы контроля при обработке информации в АСУ классифицируют по различным параметрам: по количеству основных операций, охватываемых контролем – единичный (одна операция), групповой (группа последовательных операций), комплексный (контролируется, например, процесс сбора данных); по частоте контроля – непрерывный, циклический, периодический, разовый, выборочный, по отклонениям; по времени контроля – до выполнения основных операций, одновременно с ними, в промежутках между основными операциями, после них; по виду оборудования контроля – встроенный, контроль с помощью дополнительных технических средств, безаппаратурный; по уровню автоматизации – "ручной", автоматизированный, автоматический.
Различают системные (организационные), программные и аппаратные методы контроля достоверности [1.4].
Системные методы включают: оптимизацию структуры обработки; поддержание характеристик оборудования в заданных пределах; повышение культуры обработки; обучение и стимулирование персонала; создание оптимального числа копий и (или) предыстории программ, исходных и текущих данных; определение оптимальной величины пакетов данных и скорости первичной обработки, процедур доступа к массивам и др.
Программные методы повышения достоверности обработки информации состоят в том, что при составлении процедур обработки данных в них предусматривают дополнительные операции, имеющие математическую или логическую связь с алгоритмом обработки данных. Сравнение результатов этих дополнительных операций с результатами обработки данных дает возможность установить с определенной вероятностью наличие или отсутствие ошибок. На основании этого сравнения, как правило, появляется возможность исправить обнаруженную ошибку.
Можно выделить следующие программные методы контроля: счетные - двойной или обратный счет, использование контрольных сумм, контроль по формату, балансовые методы и др.; математические – способ подстановки, проверка с помощью дополнительных связей, проверка предельных значений, статистический прогноз; использующие избыточность информации – контрольных цифр, сравнение данных из различных источников, сравнение с внешними данными, контроль с использованием принципа обратной связи; логические - смысловые проверки, контроль по отклонениям, контроль по заданной последовательности записей, метод шаблонов, контроль за временем решения задач ЭВМ, экспертная оценка получаемых данных; прочие – контрольных испытаний, промежуточных точек и новых начал, комбинированные.
Аппаратные методы контроля и обнаружения ошибок могут выполнять практически те же функции, что и программные. Аппаратными методами обнаруживают ошибки ближе к месту их возникновения и недоступные для программных методов (например, перемежающиеся ошибки).
Следует отметить, что методы контроля достоверности позволяют выявлять ошибки, возникающие и из-за неправильной работы программ. Однако локализация и исправление ошибок в программах требует разработки и использования специальных методов тестирования и отладки, рассмотрение которых выходит за рамки настоящей книги.
Все перечисленные методы контроля обработки данных базируются на использовании определенной избыточности. Можно выделить структурную, временную и информационную избыточность, иногда выделяют также прагматическую избыточность. Соответственно различают методы контроля со структурной, временной и информационной избыточностью.
Структурная избыточность требует введения в состав АСУ дополнительных элементов (резервирование информационных массивов и программных модулей, реализация одних и тех же функций различными процедурами, схемный контроль в технических средствах АСУ и т.д.).
Временная избыточность связана с возможностью неоднократного повторения определенного контролируемого этапа обработки данных. Обычно этап обработки повторяют неоднократно и результаты обработки сравнивают между собой с целью контроля достоверности, или после обработки контроль достоверности осуществляют каким-либо методом, и в случае обнаружения ошибки производят исправления и повторную обработку.
Информационная избыточность может быть естественной и искусственной. Естественная информационная избыточность отражает объективно существующие связи между элементами СОД, наличие которых позволяет судить о достоверности информации. Искусственная информационная избыточность характеризуется введением дополнительных информационных разрядов для используемых данных и дополнительных операций в процедуры обработки данных, имеющих математическую или логическую связь с алгоритмом обработки данных. На основании анализа результатов дополнительных операций и процедур обработки данных, а также дополнительных информационных разрядов выявляется наличие или отсутствие ошибок определенного типа, а также возможности их исправления.
Прагматическая избыточность – наименее исследованный тип избыточности. Под величиной прагматической избыточности в сообщении относительно некоторого получателя понимают процент элементов сообщения (символов, разрядов, слов, предложений и т.п.), исключение которых не изменит отклика получателя на это сообщение. Примером прагматической избыточности является повторение материала при обучении, неоднократное повторение, разъяснение приказов и распоряжений и т.д.
Для решения задач анализа систем повышения достоверности обработки и защиты данных в АСУ используют понятия графа технологии обработки данных, индикаторного графа и графа ошибок.
Особенности различных структур обработки данных отражаются на графе технологии I(π) = G(V, E), введенном выше. Следует отметить, что основными структурными особенностями I(π) является наличие обратных связей и модульность программного и информационного обеспечения (характеристика вершин и дуг графа I(π) ).
Для упрощения анализа систем контроля и выбора соответствующих методов контроля вводится понятие индикаторного графа J(π). Вершинами данного графа являются индикаторы состояний j(wi) соответствующих информационных элементов (вершин графа технологий I(π)). При этом индикатор j(wi) = 1, если в информационном элементе содержится ошибка, и j(wi) = 0 в противном случае. Дуги индикаторного графа, соответствующие процедурам, отображают взаимодействие и распространение ошибок.
Ошибку в выходной переменной определим как ошибку результата. Она появляется вследствие возникновения ошибок в одном или нескольких промежуточных элементах данных. Таким образом, ошибки результата связаны с событиями ошибок в вершинах индикаторного графа логическими функциями И и ИЛИ, аргументами которых будут индикаторы промежуточных событий ошибки.
Одна из основных задач анализа системы контроля состоит в определении вероятностей ошибок выходных переменных. При этом необходимо установить зависимости между этими вероятностями и состояниями вершин индикаторного графа (т.е. вероятностями появления ошибок в промежуточных данных). Простейшим видом указанной зависимости является, например, зависимость типа "последовательное соединение", когда появление хотя бы одной ошибки в промежуточных данных (частная ошибка) приводит к появлению ошибки в выходных данных (ошибки результата).

Рис. 4.7

Рис. 4.8
Графическим представлением такого взаимодействия является граф ошибок  , вершинами которого являются индикаторы входных и выходных переменных указанных выше логических функций, а дуги графа отображают причинно-следственные взаимодействия между индикаторами ошибок – частных, промежуточных и результата. Отметим, что вершина ошибки результата не содержит выходящих дуг.
, вершинами которого являются индикаторы входных и выходных переменных указанных выше логических функций, а дуги графа отображают причинно-следственные взаимодействия между индикаторами ошибок – частных, промежуточных и результата. Отметим, что вершина ошибки результата не содержит выходящих дуг.
Рассмотрим информационный граф технологии I(π) и соответствующий ему индикаторный граф J(π) (рис. 4.7 и 4.8). Пусть ошибка результата состоит в том, что нет связующего пути между вершинами а и d графа I(π) (определены, соответствующие комбинации частных ошибок индикаторного графа). Соответствующий граф ошибок представлен на рис. 4.9. На основании графа определяется возможность ошибки результата в зависимости от наступления частных ошибок.
Определение ошибок результата, их ранжирование и анализ причинно-следственных связей графа дают возможность найти частные ошибки, вызывающие появление ошибок результата, а также анализа и последующего выбора соответствующих методов контроля. Для формальной постановки задач анализа и синтеза систем повышения достоверности введены понятия минимального разреза и минимального пути графа.
Разрезом назовем множество частных ошибок, совместное появление которых влечет появление ошибки результата. Разрез является минимальным, если никакое его собственное подмножество не является разрезом. Если произошла ошибка результата, то произошли частные ошибки, образующие минимальный разрез.

Рис. 4.9
Путь есть множество частных ошибок, совместное непоявление которых влечет непоявление ошибки результата. Путь является минимальным, если никакое его собственное подмножество не является путем. Если ошибка результата не появилась, то не появились совместно и все частные ошибки, образующие минимальный путь.
Пусть k = { k1, ..., kl, ..., kk} – множество минимальных разрезов, р = {p1, ..., рr, ..., ps} – множество минимальных путей, I(у) – индикатор главного события, I(wi) - индикатор базисного события wi графа . Если граф ошибок является деревом, то справедливы следующие отношения:

которые определяют зависимости главного события ошибки от базисных событий через множества минимальных разрезов и путей.
Под уровнем ошибки результата L(y) понимают значение вероятности ее появления. Уровень ошибки является основной характеристикой используемых механизмов систем контроля.
Каждому механизму контроля обработки данных ставится в соответствие вектор системных характеристик, к которым относят вероятности обнаружения и исправления ошибок, стоимость разработки и внедрения методов контроля ошибок, эксплуатационные затраты, время обработки и внедрения, необходимую память, машинное время и т.д. Назовем механизм контроля эффективным, если  , где
, где  – допустимый уровень ошибки результата.
– допустимый уровень ошибки результата.
Общая задача анализа системы контроля состоит в определении уровня ошибки результата в зависимости от вероятностей p(wi) частных ошибок и сравнении его с допустимым.
Для произвольных древовидных структур графа в общем случае точное определение значения L(y) затруднительно. При независимых базисных событиях ошибки можно определить точную нижнюю и верхнюю границы уровня ошибок L(y) [2.16]:

где p(wi) – вероятность появления ошибки в элементе wi. Для повышения эффективности контроля необходимо уменьшать вероятности появления частных ошибок, что достигается использованием более совершенных методов контроля, введением различных вариантов избыточности в структуру АСУ.
Для случая, когда любая частная ошибка ведет к появлению ошибки результата, получены аналитические выражения для нахождения уровня ошибки L(y) и других вероятностных характеристик [2.16].
При решении практических задач построение графа ошибок для всей системы обработки данных может оказаться затруднительным из-за значительной размерности. В этом случае графы ошибок строят для отдельных задач (подзадач) и с их использованием проводят анализ взаимодействия ошибок.
Рассмотрим практический пример разработки графа ошибок при разработке подсистемы "Выпуск справок", входящей в состав АСУ "Обмен". Требовалось при заданном информационном и программном обеспечении выбрать методы контроля информационных элементов и процедур обработки данных, которые обеспечивают минимальное приращение вероятности ошибки результата (наличие ошибок в выходных документах подсистемы). На рис. 4.10 изображена модульная блок-схема подсистемы Выпуск справок". Процедуры обработки данных, информационные элементы и содержание массивов приведены соответственно в табл. 4.1-4.3.
Таблица 4.1

Таблица 4.2

Таблица 4.3


На основании анализа различных вариантов возникновения ошибок ведущих к появлению неверных выходных данных, построен граф ошибок (рис. 4.11) Описание событий, используемых в графе ошибок, приведено в табл. 4.4 и 4.5.
Таблица 4.4


Таблица 4.5

Одним из основных методов повышения достоверности при обработке информации является применение методов контроля с использованием принципа обратной связи. При этом данные, содержащие обнаруженные ошибки, направляются на исправление, после чего вновь повторяется процедура обработки. Методы контроля, использующие принцип обратной связи, можно разделить на два класса. К первому относятся методы, ориентированные на решение задач, в которых длины контролируемых участков могут быть произвольными величинами и являются, как правило, управляемыми параметрами. Эти методы используются в задачах обеспечения надежности информационных баз, определения оптимального интервала между контрольными точками в программе и др. Ко второму классу относят методы, используемые при решении задач, в которых длины контролируемых участков известны, так же как и структура обратных связей между участками, охваченными контролем.

Рис. 4.10
Каждый контролируемый участок характеризуется вектором характеристик - объемом обрабатываемых данных, требуемой вероятностью на своевременность обработки этого объема данных, законами возникновения ошибок (независимые ошибки, Марковская модель возникновения ошибок и др.), имеющимися временными или стоимостными ресурсами, требованиями к достоверности обработки информации, набором методов контроля, использование которых возможно на этом участке.

Рис. 4.11
Для анализа систем контроля данного класса используется понятие "стандартная" схема обработки данных (рис. 4.12). Цикл обработки данных распадается на непосредственно обработку, контроль и исправление ошибочных данных. На некоторых этапах обработки операции контроля и исправления недостоверных данных могут отсутствовать или могут осуществляться для группы из нескольких этапов, на каждом из которых в свою очередь осуществляется локальный контроль и исправление ошибок. После исправления ошибочных данных они вновь обрабатываются с последующим контролем и исправлением ошибок. Контроль и исправление могут повторяться случайное число раз.

Рис. 4.12
Производными "стандартной" схемы обработки данных являются последовательная схема обработки, последовательная схема с общей обратной связью, циклическая и последовательно-циклическая схема, сеть обработки данных.
Стандартная схема обработки данных. Процесс функционирования стандартной схемы обработки представлен на рис. 4.13. Процесс обработки единицы входных данных является процессом Бернулли, в котором q - есть вероятность ошибки при обработке единичного объема данных, а вероятность правильной обработки единичного объема есть р = 1 - q. Процесс контроля также является бернуллиевским, где f - есть вероятность обнаружения ошибки в единичном объеме данных и l = 1 - f - есть вероятность пропуска ошибки. Предполагается, что вероятность принятия правильно обработанного единичного объема данных за ошибку равна нулю; обнаруженные ошибки исправляются с вероятностью единица.
Под единицей объема данных в зависимости от задачи понимается символ, запись, сообщение, массив, документ и т.д., N - общий объем данных. Число циклов обработки единицы данных является случайным и попытка обработки считается успешной, если в фазе обработки не произошло ошибки или же ошибка произошла, но не была обнаружена в фазе контроля. Попытка считается неуспешной, если в фазе обработки произошла ошибка, которая была обнаружена.
Обозначим через ξk число попыток, затрачиваемых в фазе обработки на n-ю единицу данных, п = =  . Тогда число попыток T(N), затрачиваемых в фазе обработки на N единиц данных, равно сумме случайных величин ξk, k = . Если на реализацию попытки в фазе обработки требуется единичное время, то T(N) – есть время, затраченное на обработку N единиц данных.
. Тогда число попыток T(N), затрачиваемых в фазе обработки на N единиц данных, равно сумме случайных величин ξk, k = . Если на реализацию попытки в фазе обработки требуется единичное время, то T(N) – есть время, затраченное на обработку N единиц данных.

Рис. 4.13
Основной задачей анализа рассматриваемой схемы является нахождение закона распределения Ф(N, х) = р {T(N) ≤ х} случайной величины T(N). Задачи, связанные с определением вероятностных характеристик времени, которое тратится на обработку данных объема N в фазах обнаружения и исправления, решаются аналогично.
Рассмотрим вначале случай, когда ошибки при обработке возникают независимо. Процесс обработки единицы данных может завершиться успехом на (k + 1) -и попытке, если данные не содержат ошибок с вероятностью (qf)k либо содержат необнаруженные ошибки с вероятностью (qf)kq(1 – f). В противном случае процесс обработки данные единичного объема не заканчивается и они должны быть обработаны, по крайней мере, еще один раз. Вероятность этого события равна (qf)k+1. В этом случае величины |Л имеют геометрическое распределение

где i ≥ 1. Вероятность того, что за время i данные единичного объема будут обработаны без ошибок, определяется как

Представив p1(i) в виде p1(i) = pρ1ρ2, где ρ1 = (1 - qf)-1и ρ2 = 1 - (qf)i, получим, что при i → ¥ вероятность безошибочной обработки данных единичного объема равна рρ1и  только при f = = 1.
только при f = = 1.
На рис. 4.14 показаны непрерывные аналоги p1(i) для различных значений р, f, i. Вероятность того, что за время (i - 1) произошла обработка (N - 1)-й единицы данных и было (i - N) неудачных попыток обработки, равна  Вероятность удачной попытки равна р + ql, поэтому закон распределения времени обработки данных объемом N есть
Вероятность удачной попытки равна р + ql, поэтому закон распределения времени обработки данных объемом N есть

Математическое ожидание и дисперсия случайной величины T(N), распределенной по отрицательному биномиальному закону, определяется соответственно в виде

В табл. 4.6 приведены вероятности отсутствия ошибок, M[T(N)]и D[T(N)]при N = 1; 10 и i = 11; 110. При q → 0 M[T(N)]уменьшается и в пределе равно N. Использование хороших методов контроля (f → 1) увеличивает M[T(N)]. Если N велико, то на основании центральной предельной теоремы величина T(N), как сумма независимых одинаково распределенных случайных величин ξk, распределена по нормальному закону:

где 
Полученные результаты являются основой решения задач о выделении необходимых временных и стоимостных ресурсов на обработку данных заданного объема.
Таблица 4.6


Рис. 4.14
Для того чтобы с доверительной вероятностью, не меньшей а, были обработаны данные объема N, выделяемое с этой целью время 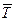 должно быть определено из условия
должно быть определено из условия

Пусть tа такое значение квантили нормального закона распределения, что Ф*(tа) = а. Так как Ф* (z) – монотонно возрастающая функция, условие реализуемости обработки данных объема N запишется в виде

Соответствующее условие для стоимостного ресурса  записывается аналогично. Эти соотношения, устанавливая взаимосвязь между характеристиками методов контроля и обработки информации и требуемыми временными и стоимостными ресурсами, являются основой для решения задач выбора оптимальных методов контроля в СОД.
записывается аналогично. Эти соотношения, устанавливая взаимосвязь между характеристиками методов контроля и обработки информации и требуемыми временными и стоимостными ресурсами, являются основой для решения задач выбора оптимальных методов контроля в СОД.
Представление результатов анализа механизмов контроля обработки данных с целью обеспечения достоверности информации в виде совокупности графовых моделей позволяет определить характеристики и исследовать практически любые возможные структуры обработки данных, учитывать различные случаи возникновения и взаимодействия ошибок.
Задачи синтеза механизмов контроля обработки информации для повышения ее достоверности возникают на этапе технического проектирования АСУ, а совершенствования этих механизмов – на этапе промышленной эксплуатации и модернизации. Эти задачи состоят в выборе наиболее рациональных методов контроля достоверности для элементов программного и информационного обеспечения. При этом выбор оптимальной совокупности указанных методов определяется требованиями к достоверности информации, законами возникновения и взаимодействия ошибок, ресурсами на разработку, внедрение и эксплуатацию механизмов контроля достоверности, возможностью использования конкретных методов контроля достоверности и защиты. При постановке и решении этих задач также используют введенные ранее понятия графа ошибок, индикаторного графа, "стандартной" схемы обработки и т.д.
Задача синтеза оптимальной системы повышения достоверности состоит в выборе методов контроля достоверности для частных ошибок, при использовании которых уровень ошибок L(p) минимален и при ограничениях на временные, стоимостные и другие виды ресурсов, выделяемые с целью обеспечения достоверности. Так как определение аналитического вида функции L(p) для произвольных древовидных структур не представляется возможным, то в качестве целевой функции задачи синтеза системы повышения достоверности рассматривается снижение уровня ошибок на ∆L(p) при использовании методов контроля достоверности, которое необходимо максимизировать по абсолютной величине.
Пусть при i =  ; j =
; j =  переменная хij = 1, если для частной ошибки wi используется j-и метод контроля достоверности, и хij = 0 - в противном случае. Пусть также ∆ij -уменьшение вероятности частной ошибки wi, вызванное использованием j-го метода контроля достоверности, τij и сij – соответствующие временные и стоимостные затраты для j-го метода и события wi; Т и С - ограничения на временные и стоимостные затраты. Тогда задача синтеза оптимальной системы контроля достоверности записывается в виде:
переменная хij = 1, если для частной ошибки wi используется j-и метод контроля достоверности, и хij = 0 - в противном случае. Пусть также ∆ij -уменьшение вероятности частной ошибки wi, вызванное использованием j-го метода контроля достоверности, τij и сij – соответствующие временные и стоимостные затраты для j-го метода и события wi; Т и С - ограничения на временные и стоимостные затраты. Тогда задача синтеза оптимальной системы контроля достоверности записывается в виде:

при ограничениях: на структуру контроля

на временные затраты, связанные с контролем,

на стоимостные затраты, связанные с контролем,

К числу ограничений может быть отнесен также и объем памяти вычислительного комплекса, выделяемый для целей контроля достоверности.
Одним из методов повышения достоверности при обработке информации является применение в базисных вершинах методов контроля с использованием принципа обратной связи. Задача оптимизации структуры обработки информации состоит при этом в выборе такой структуры обработки (т.е. определении узлов обработки, этапов контроля и исправления обнаруженных ошибок, выборе методов обнаружения и исправления ошибок), которая обеспечивает максимум достоверности обрабатываемой информации при заданных ограничениях на время и материальные затраты. Для синтеза систем контроля данного класса, так же как и для их анализа, используются модели, в которых для каждой базисной вершины графа применяется понятие "стандартной" схемы обработки данных [2.16].
Резервирование информационных массивов, основанное на информационной избыточности, является эффективным методом повышения достоверности информации в АСУ и уменьшения вероятности потерь от ее разрушения. При этом под разрушением информационного массива понимается событие, приводящее к невозможности его дальнейшего использования вследствие появления ошибочных данных или выхода из строя физического носителя информации.
В настоящее время в СОД применяют три стратегии резервирования информационных массивов [2.16].
Стратегия I. Используется некоторое число копий информационных массивов. Если основной массив разрушился, то используется первая его копия, если она разрушилась, то используется следующая копия и т.д.
Стратегия II. Используются особенности организации обновления массивов текущих данных, которые заключаются в том, что в качестве копий текущего массива служат его предыстории (предыдущие массивы и массивы изменений). Если текущий массив разрушился, то он восстанавливается программой обновления из предыдущего массива и массива изменений. Если и этот массив разрушился, то его можно восстановить из предыдущей предыстории и т.д.
Стратегия III. Смешанная стратегия, т.е. для текущего массива создаются его копии и хранится заданное число предыстории. Использование и восстановление массивов происходит аналогично предыдущим стратегиям. Причем вначале используются копии, а в случаях их разрушения массив восстанавливается из предыстории.
Развитием указанных стратегий резервирования являются методы, используемые в архивах машинных носителей, предназначенных для обеспечения длительного и надежного хранения информационных массивов и программных модулей [2.16]. В архиве хранится основной массив (оригинал) и К (К = 1, 2, 3, ...) уровней дубликатов, из которых создаются копии пользователей для непосредственного использования на ЭВМ. Выделены две возможные стратегии организации работы архива машинных носителей.
Стратегия А-1. Копии пользователей получают из дубликата уровня К. Если дубликат разрушается, то его восстанавливают из дубликата уровня (К – 1) или при К = 1 из оригинала, после чего вновь делается попытка получения копии. При этом уже полученные копии в качестве дубликатов использоваться не могут.
Стратегия А-2. Копии пользователей получают из дубликата уровня К, но при его разрушении дубликат может быть получен из любой ранее созданных копий пользователей.
Основными характеристиками перечисленных стратегий резервирования являются вероятность успешного обновления (использования) информационного массива ρ; вероятность разрушения основного массива и его копий и (или) предыстории (1 – ρ); среднее время решения задачи (обновления) при условии успешного ее решения E[Ty]; среднее время до разрушения массива и его копий Е[Тp];среднее время решения задачи (обновления) вне зависимости от того, успешно она решена или нет Е[Т], т.е. среднее время доступа к ЭВМ при использовании заданной стратегии резервирования; коэффициент готовности СОД KГ; средние эксплуатационные затраты системы F в фиксированном интервале времени функционирования системы.
Основные результаты сравнения эффективности использования перечисленных стратегий резервирования с точки зрения экстремизации вероятностных, временных и стоимостных критериев сводятся к следующим.
1. Наибольшую вероятность успешного обновления массива обеспечивает стратегия I резервирования.
2. Если вероятность разрушения массива при обновлении мала – q → 0, то наименьшее время доступа к ЭВМ обеспечивает стратегия II резервирования.
3. Если вероятность разрушения велика – q → 1/2, и время получения копии массива превышает время обновления – τ > θ, то наименьшее время доступа к ЭВМ обеспечивает стратегия III, а при θ > τ - стратегия П.
4. Наибольшую величину коэффициента готовности при q → 0 обеспечивает стратегия II, а при q → → 1/2, θ > τ - стратегия I резервирования.
5. При q → 1/2 и τ < θ минимальные эксплуатационные затраты обеспечивает стратегия I, а при q → 0 – стратегия II резервирования.
6. Наибольшую вероятность неразрушения оригинала в архиве машинных носителей обеспечивает стратегия А-2.
На этапах отладки и опытной эксплуатации АСУ, а также при работе с массивами информации большого объема и содержащих информацию, разрушение которой наносит существенный ущерб системе (например, приводит к ее отказу), целесообразно использовать метод восстановительного резервирования. Под восстановительным резервированием понимают создание и хранение одной или нескольких копий и (или) предыстории массива (в зависимости от принятой стратегии резервирования), которые предназначены только для воссоздания разрушенной текущей версии. При этом к массивам, хранящимся в цикле восстановительного резервирования, применяется только операция копирования, что повышает сохранность информации.
Задача определения оптимальных стратегий резервирования существенно усложняется, когда для решения функциональных задач в СОД используется несколько информационных массивов, имеющих различные характеристики.
Существенно усложняются задачи резервирования массивов в вычислительных сетях. Использование различных стратегий резервирования в сетях ЭВМ имеет ряд особенностей, обусловленных спецификой вычислительных систем. В этом случае при анализе стратегий резервирования и выборе оптимальной стратегии необходимо учитывать топологию сети, надежность и стоимость использования каналов связи и ЭВМ сети, задержку сообщений и т л.
Территориальная распределенность сетей ЭВМ позволяет выделить следующие основные варианты использования стратегий резервирования: централизованное, децентрализованное и динамическое хранение резерва.
При централизованном хранении резерва задача выбора оптимальной стратегии решается традиционными методами с учетом надежности, стоимости использования и временных характеристик узлов и каналов связи сети.
При децентрализованном хранении используются следующие дисциплины обработки поступающих запросов к массивам: адресация запроса в ближайший согласно некоторому критерию узел с резервом требуемого модуля или массива; одновременная адресация запроса в N узлов с резервом; последовательная передача запроса по узлам с резервом, принадлежащим пути длины N; из узла, в котором получен запрос, поочередно опрашиваются N узлов с резервом.
Возможно динамическое хранение резерва, при котором в некоторые моменты времени происходит перемещение резерва по узлам сети. Очередное местоположение резерва определяется согласно некоторой процедуре (случайной, фиксированной или аддитивной). При анализе и расчете оптимальных стратегий в этом случае необходимо учитывать возможность разрушения резерва при его перемещении и стоимостные, затраты на реализацию этого перемещения.
Для решения задач оптимального резервирования в сетях используют эвристические методы. При этом значительные трудности вызывает большая размерность решаемых задач, что приводит к необходимости разработки специальных методов ее снижения.
Защита информации
На современном этапе развития АСУ все большее значение приобретает защита информации, что связано, главным образом, с увеличением объемов данных, к которым одновременно обращается для решения различных задач большое число пользователей. Это приводит к повышению уязвимости информации, под которой понимают возможность ее несанкционированного использования, искажения или уничтожения в результате доступа пользователей, не обладающих специальными полномочиями, к конфиденциальным сведениям. Для уменьшения вероятности несанкционированного использования информации разрабатывают специальные механизмы ее защиты.
Серийно выпускаемая вычислительная техника имеет некоторые встроенные аппаратные и программные средства защиты. Так, например, многие ЭВМ оснащают специальными аппаратными средствами, позволяющими изолировать пользователей друг от друга и от операционной системы, что обеспечивает возможность эффективного контроля операций по выборке и посылке на хранение данных и уменьшает возможность несанкционированного доступа. Предусматривают специальные средства центрального процессора для обеспечения безопасности информации, в том числе программно-читаемые часы для регистрации времени свершения тех или иных событий; программно-читаемый закрепленный в памяти аппаратными средствами код идентификации, различный для каждого центрального процессора; инструкции по очистке блока памяти внесением нулей; использование только специфицированных кодов операций и т.п.
Чтобы не допустить искажения или потери информации, предусмотрена система защиты памяти при записи и считывании информации. Наиболее важной является защита при записи, однако в отдельных случаях необходимо знать, какая программа сделала попытку считать данные или исполнить команду из запрещенной для нее зоны. Попытка нарушить защиту памяти вызывает прерывание программы-нарушителя. Обычно используют несколько способов организации защиты памяти. Часто встречается защита двумя регистрами, называемыми граничными или регистрами защиты и содержащими номера нижнего и верхнего граничных блоков сегмента. При появлении команды записи по некоторому адресу он последовательно сравнивается с граничными регистрами. Если требуемый адрес находится за пределами сегмента, указанного нижним и верхним регистрами, то возникает прерывание и после установления его причины управление передается специальной программе, обрабатывающей нарушения защиты памяти. Установку значений указанных регистров при работе ЭВМ в режиме разделения времени провопит специальная управляющая программа-супервизор. Аналогично функционирует система защиты с тремя регистрами. Третий регистр устанавливает, распространяется ли защита на внутреннюю область, определяемую верхним и нижним регистрами (состояние 0), или внешнюю (состояние 1).
В настоящее время развивается тенденция хранить программы в оперативной памяти не целиком, а составленными из отдельных сегментов. Для защиты этих сегментов можно использовать несколько пар регистров защиты, подобных описанным выше. Однако с ростом числа регистров растет число выполняемых логических операций, что усложняет схемную реализацию механизма защиты и может вызвать существенное снижение быстродействия ЭВМ.
Достаточно широко используют метод защиты оперативной памяти по ключу. Память разбивают на блоки, каждому из которых ставится в соответствие некоторый ключ. Условия выполнения программы запоминаются в слове памяти, называемом словом состояния программы. Супервизор помещает в это слово ключ защиты программы. Кроме того, в это же слово записывают первые позиции ключей каждого блока памяти, используемых текущей программой. При появлении адреса из некоторого блока памяти сравнивается ключ защиты в слове состояния программы и первые разряды ключа этого блока памяти. Несовпадение свидетельствует о попытке нарушения защиты и вызывает прерывание.
В системах, работающих в режиме разделения времени, функции защиты возлагают на трансляторы, что накладывает определенные ограничения на языки программирования, так как трансляторы должны до исполнения программ осуществить контроль. Этот метод часто используют для работы с языками, близкими к естественным. В этом случае символическим идентификаторам соответствует определенный адрес памяти (ячейка памяти, например, получившая обозначение А, всегда будет находиться по адресу А' для первого пользователя, по адресу А" для второго и т.д., что упрощает контроль при трансляции).
Несмотря на широкое использование серийных средств защиты данных в ЭВМ, они не обеспечивают надежное перекрытие всех потенциально возможных каналов несанкционированного использования или утечки информации, что диктует необходимость разработки механизмов защиты при проектировании АСУ. Одна из основных их характеристик - вероятность "взлома", в результате которого будет нарушена безопасность информации, т.е. произойдет либо несанкционированное использование, либо разрушение (искажение или стирание) отдельных элементов или всех данных. Выбор механизмов защиты определяется особенностями рассматриваемой СОД, критериями синтезируемой системы защиты, используемыми методами защиты, имеющимися ресурсами и т.д. Существующие методы и механизмы защиты включают в себя процедурные, программные и аппаратные способы организации защиты.
Процедурные методы защиты обеспечивают доступ к данным только тем пользователям, которые имеют соответствующие разрешения. Например, для систем с разделением времени процедурные методы защиты должны обеспечивать контроль доступа со стороны пользователей, использующих терминалы ввода–вывода. Идентификация осуществляется путем проверки паролей терминалов, кодов пользователей, шифров работ и посылки обратного сигнала об их законности. Реализация процедурных методов защиты обеспечивается установлением паролей для терминалов, грифов секретности данных, созданием организационных и физических ограничений (сейфы, вахтеры, охрана и т д.), а повышение их эффективности достигается путем соответствующего обучения и повышения уровня ответственности персонала. Ответственность за нарушение безопасности данных при этом возлагается на группу лиц, в обязанности которых входят: управление доступом к данным; учет попыток несанкционированного доступа к защищенным данным; регистрация лиц, имеющих копии данных ограниченного использования; анализ функционирования системы защиты и повышение качества ее работы; анализ последствий, вызванных "взломом" системы защиты. Процедурные методы защиты используют в основном на этапах первичной обработки данных и выдачи результатов обработки пользователям.
Программные и аппаратные методы защиты используют в основном на этапе обработки данных на ЭВМ. Они обеспечивают: обслуживание только "законных" пользователей; доступ к объектам защиты в соответствии с установленными правами и правилами; возможность изменения (модификации) правил взаимодействия между пользователями и объектами защиты; возможность получения -информации о безопасности объектов защиты. Некоторые программные методы обеспечивают возможность анализа функционирования системы защиты с целью повышения качества ее работы и анализа последствий, вызванных "взломом".
Структура и характеристики аппаратных и программных методов защиты зависят от характеристик процессора и структуры памяти. С точки зрения взаимодействия пользователей в системе защита обеспечивает одну из следующих альтернатив: взаимную изоляцию данных пользователей и наличие библиотеки общего пользования; некоторые данные могут использоваться и (или) изменяться рядом пользователей, что контролируется механизмом защиты; удовлетворение специфических требований пользователей в доступе к объектам защиты, что обеспечивается программируемыми механизмами защиты.
Упрощенным представлением организации защиты является следующая модель: "Каждый объект защиты окружен непроницаемым барьером с единственным проходом, у которого поставлен охранник".
Функцией охранника является проверка полномочий пользователей, которая осуществляется следующим образом: полномочия пользователя удостоверяются, если совпадает пароль, которым располагает охранник, и пароль, сообщенный пользователем.
Рассмотрим некоторые методы защиты для режима прямого доступа.
1. Помещения, где находятся терминалы, запирают. Доступ к ресурсам вычислительного комплекса имеют пользователи, которые обладают ключами.
2. Доступ к терминалам разрешается в случае предъявления соответствующего пропуска вахтеру.
3. Каждый терминал имеет список пользователей, которым разрешен доступ с этого терминала к ресурсам вычислительного комплекса. Пользователь сообщает системе свой код (пароль), который сверяется со списком. Если пароли совпадают, доступ разрешается.
4. Для каждого пользователя, код которого помещен в список, указывается временной интервал, в течение которого он имеет право обращаться к системе. В этом случае для доступа необходимо знать не только код пользователя, но и разрешенный ему временной интервал.
5. Пользователь начинает работу с терминалом, вводя свое имя "открытым текстом". По каналу связи имя передается в ЭВМ, где в защищенной таблице отыскивается соответствующий засекреченный ключ шифра. Этот ключ передается шифровальному устройству, входящему в состав ЭВМ, после чего на терминал посылается подтверждение о готовности. Тем временем пользователь вводит этот же ключ в свой терминал. Если ключи совпадают, то сеанс связи продолжается.
6. Если пароль пользователя не может быть сохранен в тайне, он должен быть только однократным. В этом случае пользователь ведет список паролей, вычеркивая из него уже использованные. В других случаях применяется контроль срока действия или общего числа применений конкретного пароля.
7. Список паролей пользователей в системе должен быть надежно защищен. Например, все оригиналы паролей при вводе подвергаются преобразованию Н. Таким образом, в системе хранится список не оригиналов, а отображений паролей пользователей. Преобразование Н должно быть плохо обращаемым, т.е. возможность найти значение пароля по его отображению должна быть минимальной. Пользователь, обращаясь к системе, предъявляет свой пароль, который преобразуется и сверяется со списком отображении. Совпадение свидетельствует о законности обращения пользователя. Засекреченным должен быть только пароль, а список отображений может и не быть засекреченным, поскольку практически невозможно получить пароль по его отображению.
8. Набор данных может быть защищен установлением для него списка пользователей, имеющих право доступа к этому набору.
9. Кроме списка пользователей можно указывать и типы доступа (чтение, запись, редактирование), которые разрешены конкретному пользователю в отношении этого набора данных.
10. Если набор состоит из неоднородных (в смысле защиты) данных, то для каждого типа данных устанавливается список пользователей и указывается, какие виды доступа разрешены каждому пользователю.
В процессе разработки системы в первую очередь должны быть определены требования к защите информации. Они заключаются в том, что всю информацию по ее смысловому содержанию делят на группы различного уровня защиты, доступные: всем пользователям для чтения и обновления; всем для чтения и определенным категориям пользователей для обновления; определенным группам пользователей только для чтения и другим для чтения и обновления; определенным группам пользователей только для чтения и в индивидуальном порядке для чтения и обновления; в индивидуальном порядке для чтения и обновления. Отнесение информации к той или иной группе секретности определяется тем, какой ущерб может быть нанесен системе при ее несанкционированном использовании.
Во всех случаях введения тех или иных методов защиты должны быть разработаны организационные меры, предусматривающие функционирование защиты, в частности хранение и смену паролей. С одной стороны, должна быть обеспечена "защита защиты" – например, невозможность кому-либо узнать пароль пользователя, в том числе сотрудникам ВЦ и эксплуатационному персоналу АСУ. С другой стороны, надо помнить о возможности такой ситуации, когда пользователь забыл или утерял свой пароль. В первом случае надо предусмотреть процедуру восстановления права пользователя на доступ к данным по старому или новому паролю. Во втором случае надо надежно "закрыть" данные, чтобы ими не могло воспользоваться лицо, нашедшее пароль.
Для маскировки наличия защиты может использоваться метод правдоподобных ответов. Он заключается в том, что лицу, обратившемуся с запросом к неразрешенным для него сведениям, выдается ответ, внешне совпадающий с запрашиваемым, но содержание заполняется случайным образом. Этот метод достаточно эффективен, так как не провоцирует на новые попытки "взлома" защиты. Недостаток метода заключается в том, что лица, имеющие право доступа, но обращающиеся с паролями небрежно, могут получить неверные сведения и, не подозревая об этом, использовать их в своей деятельности. Обычно эффективными являются "открытые" методы защиты, когда сам метод не представляет секрета, но воспользоваться им постороннему лицу невозможно.
Задачи синтеза систем защиты состоят в выборе совокупности методов защиты, обеспечивающей экстремальное значение определенной характеристики системы защиты при ограничениях на ряд других характеристик. В постановках задач синтеза систем защиты в качестве ограничивающих факторов и показателей эффективности защиты выступают стоимостные и временные затраты на разработку и эксплуатацию методов защиты, потери от "взлома" системы защиты, вероятность и среднее время несанкционированного доступа к объектам защиты.
Исходной информацией для постановки и решения задач синтеза являются следующие данные: W - множество объектов защиты; LW – число структурных уровней защиты, которое необходимо последовательно преодолеть при доступе к объекту w; характеристики k-гометода зашиты, 1 ≤ k ≤ kl, использование которого возможно на l-м структурном уровне, т.е. qkl(w) – вероятность "взлома" (преодоления) l-го структурного уровня защиты объекта w при условии "взлома" предшествующих уровней;  и
и  – стоимостные затраты соответственно на разработку и эксплуатацию;
– стоимостные затраты соответственно на разработку и эксплуатацию;  и
и  - временные затраты соответственно на разработку и эксплуатацию; dkl(w) – потери в системе, вызванные преодолением ограничений рассматриваемого метода защиты; tkl(w) - время одной попытки несанкционированного доступа. Переменные: xkl(w) = 1, если k-й метод зашиты, относящийся к l-му уровню, закреплен за объектом w и xkl(w) = 0, в противном случае
- временные затраты соответственно на разработку и эксплуатацию; dkl(w) – потери в системе, вызванные преодолением ограничений рассматриваемого метода защиты; tkl(w) - время одной попытки несанкционированного доступа. Переменные: xkl(w) = 1, если k-й метод зашиты, относящийся к l-му уровню, закреплен за объектом w и xkl(w) = 0, в противном случае  , 1 ≤ l ≤ LW, 1 ≤ k ≤ kl.
, 1 ≤ l ≤ LW, 1 ≤ k ≤ kl.
Задача выбора оптимальной совокупности методов зашиты, обеспечивающей максимальное среднее время несанкционированного доступа, записывается в виде

при ограничениях:
на структуру зашиты

на вероятность несанкционированного доступа по структурным уровням и объектам защиты

где ql(w) - допустимое значение вероятности несанкционированного доступа для l-го уровня и объекта w;
по стоимостным затратам на проектирование и эксплуатацию системы защиты

где СП, СЭ - выделяемые ресурсы на проектирование и эксплуатацию системы защиты;
по временным затратам на проектирование и эксплуатацию системы защиты

где ТП, ТЭ - допустимые временные затраты на проектирование и эксплуатацию
системы защиты;
на потери от "взлома" защиты

где D - допустимые суммарные потери от "взлома" зашиты.
Решение рассмотренной задачи линейного целочисленного программирования с булевыми переменными осуществляется методом "ветвей и границ" с использованием стандартных программных средств. Для сокращения размерности решаемой задачи целесообразно выделять подмножества идентичных (в смысле зашиты) объектов и производить выбор методов защиты для "представителей" этих подмножеств.
Синтез динамических систем защиты осуществляется аналогично.