|
|
II. Практическая часть.
Тульский филиал Финуниверситета
КОНТРОЛЬНАЯ РАБОТА
по дисциплине «Методы принятия управленческих решений»
Вариант №6
Выполнила:студентка 2 курса
факультета МиБИ
направления бакалавр менеджмента
группы дневной
Подприговорова И.А.
№ л.д.100.26/120238
Проверил: Кузнецов Г.В.
Тула 2014г
Содержание.
I. Теоретическая часть.
Задание 1……………………………………………………………………………..3
II. Практическая часть.
Задание 2……………………………………………………………………………...5
Задание 3……………………………………………………………………………...
Задание 4………………………………………………………………………………
Задание 5………………………………………………………………………………
Список используемой литературы………………………………………………….
I. Теоретическая часть.
Задание 1.
Методы имитационного моделирования.
Производственные процессы в экономических системах настолько сложны и многообразны ,что аналитические модели исследования операций(модели математического программирования, СМО и др.) зачастую не могут умпешно применяться при принятии решений. Причина кроется в том ,что математические модели ,имеющие надежные методы вычисления ,являются слишком упрощенными и неадекватны реальным процессам либо адекватные математические модели не могут быть реализованы в силу вычислительных трудностей.
Метод статистического моделирования (метод Монте-Карло)
Датой рождения метода Монте-Карло принято считать 1949 г., когда появилась статья под названием «The Monte Carlo method». Создателями этого метода считают американских математиков Дж. Неймана и С. Улама. В СССР первые статьи о методе Монте-Карло были опубликованы в 1955—1956 гг. Любопытно, что теоретическая основа метода была известна давно. Более того, некоторые задачи статистики рассчитывались иногда с помощью случайных выборок, т. е. фактически методом Монте-Карло.
Однако до появления электронных вычислительных машин (ЭВМ) этот метод не мог найти сколько-нибудь широкого применения, ибо моделировать случайные величины' вручную—очень трудоемкая работа. Таким образом, возникновение метода Монте-Карло как весьма универсального численного метода стало возможным только благодаря появлению ЭВМ.
Само название «Монте-Карло» происходит от города Монте-Карло в княжестве Монако, знаменитого своим игорным домом. Идея метода чрезвычайно проста и состоит она в следующем. Вместо того, чтобы описывать процесс с помощью аналитического аппарата (дифференциальных или алгебраических уравнений), производится «розыгрыш» случайного явления с помощью специально организованной процедуры, включающей в себя случайность и дающей случайный результат. В действительности конкретное осуществление случайного процесса складывается каждый раз по-иному; так же и в результате статистического моделирования мы получаем каждый раз новую, отличную от других реализацию исследуемого процесса. Что она может нам дать? Сама по себе ничего, так же как, скажем, один случай излечения больного с помощью какого-либо лекарства. Другое дело, если таких реализаций получено много. Это множество реализаций можно использовать как некий искусственно полученный статистический материал, который может быть обработан обычными методами математической статистики. После такой обработки могут быть получены любые интересующие нас характеристики: вероятности событий, математические ожидания и дисперсии случайных величин и т. д. При моделировании случайных явлений методом Монте-Карло мы пользуемся самой случайностью как аппаратом исследования, заставляем ее «работать на нас». Нередко такой прием оказывается проще, чем попытки построить аналитическую модель. Для сложных операций, в которых участвует большое число элементов (машин, людей, организаций, подсобных средств), в которых случайные факторы сложно переплетены, где процесс — явно немарковский, метод статистического моделирования, как правило, оказывается проще аналитического (а нередко бывает и единственно возможным).
В сущности, методом Монте-Карло может быть решена любая вероятностная задача, но оправданным он становится только тогда, когда процедура розыгрыша проще, а не сложнее аналитического расчета.
В задачах исследования операций метод Монте-Карло применяется в трех основных ролях:
1) при моделировании сложных, комплексных операций, где присутствует много взаимодействующих случайных факторов;
2) при проверке применимости более простых, аналитических методов и выяснении условий их применимости;
3) в целях выработки поправок к аналитическим формулам типа «эмпирических формул» в технике.
Метод Монте-Карло используется очень часто, порой некритично и неэффективным образом. Он имеет некоторые очевидные преимущества:
а) Он не требует никаких предложений о регулярности, за исключением квадратичной интегрируемости . Это может быть полезным, так как часто очень сложная функция, чьи свойства регулярности трудно установить.
б) Он приводит к выполнимой процедуре даже в многомерном случае, когда численное интегрирование неприменимо, например, при числе измерений, большим 10.
в) Его легко применять при малых ограничениях или без предварительного анализа задачи.
Он обладает, однако, некоторыми недостатками, а именно:
а) Границы ошибки не определены точно, но включают некую случайность. Это, однако, более психологическая, чем реальная, трудность.
б) Статическая погрешность убывает медленно.
в) Необходимость иметь случайные числа.[1]
II. Практическая часть.
Задание 2.
1) Предприятие осуществляет выпуск комплектующих изделий А и В, для производства которых используются сталь и цветные металлы. Технологический процесс предполагает обработку изделий на токарных и фрезерных станках. Технологическими нормами производства изделий предусмотрены определенные затраты сырья (кг) и времени (станко-час). Технологические данные производственного процесса представлены в таблице.
В течение месяца предприятие располагает ограниченными ресурсами сырья и времени обработки изделий в производственных цехах. Прибыль от реализации изделия А составляет 100 руб./шт., изделия В — 150 руб./шт.
Таблица 1
Нормы расходы ресурсов на изготовление изделий, запасы
ресурсов и прибыль от реализации
| Продукция / ресурсы | Сырье, кг | Обработка, станко-час | Прибыль, руб. | ||
| Цветные металлы | Сталь | Токарные работы | Фрезерные работы | ||
| Изделие А | |||||
| Изделие В | |||||
| Ресурсы |
1.Найдите оптимальный план производства (количество изделий А и В), дающий наибольшую прибыль.
2.Проведите анализ решения с использованием двойственных оценок.
Решение :
Пусть х1 – количество изделий вида А, х2 – количество изделий вида В.
От изделия A прибыль за одну штуку – 100 руб.
От изделия B прибыль за одну штуку – 150 руб.
Целевая функция :

 - прибыль от реализации изделий обоих видов.
- прибыль от реализации изделий обоих видов.
Функциональные ограничения (по затратам сырья и времени):

Прямые ограничения. Т.к. количество изделий не может быть отрицательным числом, то : 
Найдем решение с помощью надстройки Excel Поиск решения.
Представим рабочий лист Excel с занесенными исходными данными (рисунок 1)

Рисунок 1 – Фрагмент листа Excel с исходными данными
В ячейках В3, С3 будут значения переменных Х1, Х2.
Далее в ячейку D4 заносим значение целевой функции . Для этого используем встроенную математическую функцию СУММПРОИЗВ.
Порядок вычисления:
1) Активируем Мастер функции (в главном меню выбираем Вставка/Функция)
2) в окне Категория выбираем Математические, в окне Функция – СУММПРОИЗВ. Щелкаем на кнопку ОК.

Рисунок 2 – Диалоговое окно «Мастер функции»
3) Заполняем аргументы функции (рисунок 3)
Массив_1 – ячейки содержащий набор прибыли на изделия (В4:С4)
Массив_2 – ячейки, содержащие в будущем значения переменных Х1, Х2 (В3:С3). Щелкаем на клавишу F4, чтобы аргумент функции в этом массиве остался постоянным ($В$3:$С$3).

Рисунок 3 – Диалоговое окно «Функции СУММПРОИЗВ»
4) Нажимаем клавишу ОК
Далее ячейку с функцией D4 копируем в левые части ограничений, т.е. в ячейки D6, D7, D8 и D9.

Рисунок 4 – Фрагмент листа Excel с введенными зависимостями для функции цели и ограничений
Теперь можно использовать надстройку Поиск решения. Порядок вычисления:
1) В главном меню выбираем Сервис, в надстройках Поиск решения
2) Заполняем аргументы Поиска решения
Установить целевую ячейку – заносим ячейку с функцией цели D4.
Равной максимальному.
Изменяя ячейки – заносим диапазон ячеек со значением переменных Х1 Х2 (В3:C3)

Рисунок 5 – Заполнение аргументов «Поиск решения»
В Параметрах отмечаем Линейная модель и Неотрицательные значения.

Рисунок 6 – Ввод параметров поиска решения
Нажимаем кнопку ОК и в меню Поиск решения Выполнить.

Рисунок 7 – Сообщение о выполнении задачи
Выделяем все виды отчетов и нажимаем ОК. Получаем:

Рисунок 8 – Результаты решения задачи
Ответ:  при х1 = 40, х2 = 160.
при х1 = 40, х2 = 160.
Экономический смысл: Максимальную прибыль от реализации изделий обоих видов в 28000 руб. предприятие сможет получить, если будет реализовывать 40 шт. изделий вида А и 160 шт. изделий вида В.
2) Проведем анализ решения с использованием двойственных оценок.
С каждой задачей линейного программирования тесно связана другая линейная задача, называемая двойственной.
Вводим переменные:
Переменные двойственной задачи yi называют объективно обусловленными оценками, или двойственными оценками, или «ценами» ресурсов, или теневыми ценами.
Количество переменных в двойственной задачи соответствует количеству функциональных ограничений прямой задачи. В прямой задачи 4 функциональных ограничения, следовательно, в двойственной задачи будет 4 переменные.

у1 – двойственная оценка ресурса цветных металлов;
у2 – двойственная оценка стали;
у3 – двойственная оценка токарных работ;
у4 – двойственная оценка фрезерных работ;
Составляем функцию цели:
Коэффициентами при переменных функции цели двойственной задачи являются левые части ограничений прямой задачи, а направление цели меняется на противоположное.
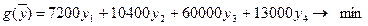
 - общая стоимость запасов всех видов ресурсов.
- общая стоимость запасов всех видов ресурсов.
Составляем ограничения:
Матрица из коэффициентов системы ограничений исходной задачи транспонируется, знак неравенства меняется на противоположный, свободными членами будут являться коэффициенты из целевой функции исходной задачи:

 - стоимость ресурсов всех видов для изготовления изделия вида А;
- стоимость ресурсов всех видов для изготовления изделия вида А;
 - стоимость ресурсов всех видов для изготовления изделия вида В;
- стоимость ресурсов всех видов для изготовления изделия вида В;
Решение:
Найдем решение с помощью надстройки Excel Поиск решения.
Представим рабочий лист Excel с занесенными исходными данными (рисунок 9)

Рисунок 9 – Фрагмент листа Excel с исходными данными
В ячейках В2, С2 ,D2 ,E2 будут значения переменных Y1, Y2 ,Y3 ,Y4.
Далее в ячейку F3 заносим значение целевой функции . Для этого используем встроенную математическую функцию СУММПРОИЗВ.
Порядок вычисления:
1) Активируем Мастер функции (в главном меню выбираем Вставка/Функция)
2) в окне Категория выбираем Математические, в окне Функция – СУММПРОИЗВ. Щелкаем на кнопку ОК.
3) Y1, Y2 ,Y3 ,Y4 – находим с помощью Поиска решений.(рисунок 10)

Рисунок 10 – Результаты решения задачи
Вывод :Сырье цветне металлы имеет более высокую двойственную оценку, следовательно, является более дефицитным ресурсом. Увеличение запасов цветных металлов на 1 кг приведет к росту прибыли на 2,85 руб. А при увеличении обработки стали на 1 станко-час прибыль вырастет на 0,71 руб.
у3 и у4 = 0 – токарные и фрезерные работы используются в оптимальном плане не полностью, находятся в избытке. Увеличение запасов этих видов ресурсов не повлияет на объем производства и прибыль.
Задание 3.
Зафиксирован объем продаж Y(t) (тыс. шт.) одного из продуктов фирмы за одиннадцать месяцев. Временной ряд данного показателя представлен в таблице 2.
Таблица 2
Динамика объема продаж
| t | |||||||||||
| y(t) |
Требуется:
1) построить график временного ряда, сделать вывод о наличии тренда;
2)построить линейную модель Y(t)=aо+а1t , параметры которой оценить с помощью метода наименьших квадратов (МНК);
3) оценить адекватность построенной модели, используя свойства остаточной компоненты e(t);
4) оценить точность модели на основе использования средней относительной ошибки аппроксимации;
5) по построенной модели осуществить прогноз спроса на следующие два месяца (доверительный интервал прогноза рассчитать при доверительной вероятности P = 75%);
6)фактические значения показателя, результаты моделирования и прогнозирования представить графически.
7) Используя пакеты Excel, VSTAT, подобрать для данных своего варианта наилучшую трендовую модель и выполнить прогнозирование по лучшей модели на два ближайших периода вперед. В отчете по данному заданию представить соответствующие листинги с комментариями.
Решение:
1. Построим график временного ряда (рисунок 11) :

Рисунок 11 – График временного ряда
Вывод. Анализ рисунка 11 показывает, что в ряду динамики имеется тенденция к увеличению показателя.
2. Построение линейной трендовой модели
Общий вид линейной модели:  , гдеа0, а1 – параметры модели.
, гдеа0, а1 – параметры модели.
Для расчета параметров модели используют метод наименьших квадратов. Найдем параметры с помощью Excel. Для этого:
- кликаем правой кнопкой мышки по точкам графика;
- в появившемся меню выбираем «Добавить линию тренда»;
- ставим галочку «Показывать уравнение на диаграмме».
Получили линейную трендовую модель:
y=1,5091x+11,491
Вывод. Параметр а1 = 1,5091 показывает, что в среднем ежемесячно объем продаж изделия повышался на 1,5091 тыс. шт.
3. Оценим адекватности построенной модели
Рассчитываем теоретические (расчетные) значения объема продаж  путем подстановки t в линейное уравнение тренда y=1,5091x+11,491
путем подстановки t в линейное уравнение тренда y=1,5091x+11,491
Рассчитываем случайную ошибку (погрешность, остатки), как разность фактических и теоретических значений по каждому уровню временного ряда:
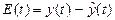
Расчет представлен в таблице 3.
3.1. Проверка независимости ряда остатков
Для проверки независимости ряда остаточной компоненты (отсутствия автокорреляции в ряду остатков) применяем критерий Дарбина-Уотсона:

Значение критерия распределено в интервале от 0 до 4. Рассчитанное значение dw сравнивают с d1 и d2.
Расчетное значение dw равно 0. В остатках существует полная положительная автокорреляция.
На уровне значимости α = 0,05, для n = 11 d1 = 0.94, d2 = 1.34 (определили по таблице значений статистики Дарбина – Уотсона).
Вывод. Поскольку  , то свойство независимости остатков выполняется. Ряд остатков не содержит автокорреляцию.
, то свойство независимости остатков выполняется. Ряд остатков не содержит автокорреляцию.
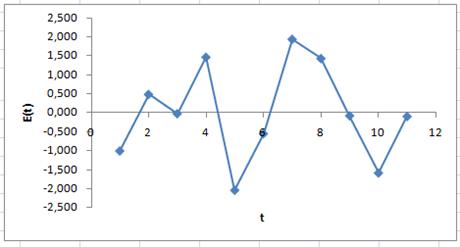
Рисунок 12 – График остатков
3.2. Проверка случайности ряда остатков
Применяем критерий поворотных точек (критерий пиков).
Значение случайной переменной считается поворотной точкой, если оно одновременно больше соседних с ним элементов или, наоборот, меньше значений предыдущего и последующего за ним члена.
Для выполнения предпосылки должно выполняться неравенство:


График остатков приведен на рисунке 12.
По графику видно, что количество поворотных точек m = 4.
Вывод. m = 4 > 3. Неравенство выполняется, значит, свойство выполняется, остатки в линейной трендовой модели имеют случайный характер.
Таблица 3
Вспомогательная таблица оценки адекватности модели
| t | y(t) | урасч(t) | E(t) | (E(t)-E(t-1))^2 | E(t)^2 | IE(t)/y(t)I | |
| 13,000 | -1,000 | - | 1,000 | 0,083 | |||
| 14,509 | 0,491 | 2,223 | 0,241 | 0,033 | |||
| 16,018 | -0,018 | 0,259 | 0,000 | 0,001 | |||
| 17,527 | 1,473 | 2,223 | 2,169 | 0,078 | |||
| 19,036 | -2,036 | 12,314 | 4,147 | 0,120 | |||
| 20,545 | -0,545 | 2,223 | 0,298 | 0,027 | |||
| 22,055 | 1,945 | 6,205 | 3,785 | 0,081 | |||
| 23,564 | 1,436 | 0,259 | 2,063 | 0,057 | |||
| 25,073 | -0,073 | 2,277 | 0,005 | 0,003 | |||
| 26,582 | -1,582 | 2,277 | 2,502 | 0,063 | |||
| 28,091 | -0,091 | 2,223 | 0,008 | 0,003 | |||
| Сумма | -0,000 | 32,483 | 16,218 | 0,550 |
3.3. Проверка подчинения ряда остатков нормальному закону распределения
Для проверки применяем R/S-критерий. Расчет скорректированного среднего квадратического отклонения остатков.

Расчет R/S-критерия: 
Для n = 11 критическими значениями критерия являются 2,67 и 3,57.
Т.к. расчетное значений R/S-критерия = 0,94 не попадает внутрь табличного интервала критических значений, то свойство не выполняется. Распределение ряда остатков не подчиняется нормальному закону распределения.
3.4. Проверка свойства, что средняя величина остатков стремится к нулю
Поскольку сумма остатков равна нулю  , то свойство выполняется.
, то свойство выполняется.
Общий вывод. Т.к. рядом остатков модели не выполняется одно свойство (подчинение нормальному закону распределения), то модель считается не вполне адекватной.
4. Оценка точности построенной модели
Для оценки точности модели рассчитываем среднюю относительную ошибку аппроксимации, которая показывает, на сколько процентов в среднем теоретические значения, полученные по модели отличаются от фактических значений.
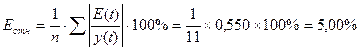
Вывод. Теоретические значения, полученные по линейной трендовой модели отличаются от фактических (исходных) в среднем на 5,00%. Ошибка меньше 7% - модель считается точной.
Общий вывод. Модель является не совсем качественной.
5. Прогнозирование объема продаж на следующие 2 месяца
Интервальный прогноз определяется по формуле:
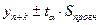 , где
, где
 - точечный прогноз
- точечный прогноз
 - ширина доверительного интервала.
- ширина доверительного интервала.
Sпрогн – средняя квадратическая ошибка прогноза
tα – табличное значения критерия Стьюдента.
Средняя квадратическая ошибка прогноза определяется по формуле:
 , где
, где
 - стандартная ошибка модели.
- стандартная ошибка модели.
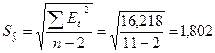
Рассчитываем точечный прогноз:
Точечный прогноз при k = 1: 
Точечный прогноз при k = 2: 
 = 226
= 226
Расчет среднеквадратических ошибок прогноза:


По условию, доверительная вероятность прогноза Р = 75%. Тогда уровень значимости α = 1 – 0,75 = 0,25. Для уровня значимости α = 0,25 с числа степеней свободы df= n-2 = 7 табличное значение критерия составит 1,254.
Расчет ширины доверительного интервала:
 (12) = 1,254 × 1,60 = 2,005
(12) = 1,254 × 1,60 = 2,005
(13) = 1,254 × 1,66 = 2,087
29,600 ± 2,005 – интервальный прогноз при k=1
27,595 – нижняя граница 29,022 – верхняя граница
31,109 ± 2,087 – интервальный прогноз при k=2
31,605 – нижняя граница 33,196 – верхняя граница
С вероятностью 75 % можно утверждать, что спрос на изделие фирмы на 12-й месяц будет находиться в пределах от 27,595 до 29,022 тыс. штук, на 13-й месяц – от 31,605 до 33,196 тыс. штук
График фактических значений, результатов моделирования и прогнозирования представлен на рисунке 13.
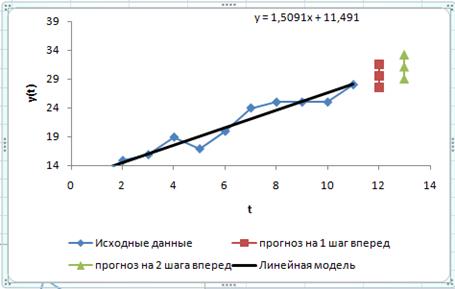
Рисунок 13–Фактические даннеы, результаты моделирования и прогнозирования
7. Подбор трендовых моделей
Для подбора моделей используем возможности MS Excel, возможность добавить линию тренда и коэффициент детерминации. Рассмотрим разные возможности сглаживания тренда: линейный, экспоненциальный, логарифмический, степенной, полиноминальный. Визуально и на основе значения коэффициента детерминации (R2) необходимо выбрать наилучший вариант описания тренда. Чем больше значение коэффициента детерминации, тем в значительной степени изменение объема продаж y(t) объясняется течением времени.

Рисунок 14 – Линейный тренд

Рисунок 15 – Экспоненциальный тренд

Рисунок 16 – Логарифмический тренд

Рисунок 17 – Полиноминальный тренд

Рисунок 18 – Степенной тренд
По данным рисунков видно, что наилучшей из рассмотренных зависимостей является полиноминальная, так как по данной модели изменение объема продаж товара на 94,4% обусловлено влиянием времени.
Лучшая трендовая модель:

Прогноз:
k = 1, t = 12:  (тыс. шт.)
(тыс. шт.)
k = 2, t = 13:  (тыс. шт.)
(тыс. шт.)
По полиноминальной трендовой модели второго порядка можно ожидать, что спрос на товар в 12-й месяц составит 28,5738 тыс. шт., в 13-й месяц – 29,5684 тыс. шт.
Задание 4.
Затраты на заказ составляют 10 руб., затраты на хранение продукции — 1 руб. в сутки. Интенсивность потребления товара —5 шт. в день. Цена товара — 2 руб./шт., а при объеме закупки 15 шт.и более — 1 руб./шт.
Определить оптимальный размер заказа, цену покупки и затраты на управление запасами.
Решение :
Уравнение общих затрат для ситуации, когда учитываются затраты на покупку товара, имеет вид :

где с – цена товара [руб./ед.тов.]; – затраты на покупку товара в единицу времени [руб./ед.t]. Если цена закупки складируемого товара постоянна и не зависит от Q, то ее включение в уравнение общих затрат приводит к перемещению графика этого уравнения параллельно оси Q и не изменяет его формы . Т.е. в случае постоянной цены товара ее учет не меняет оптимального решения .
Начинаем решение с приблизительного построения пунктирными линиями графиков двух функций общих затрат, соответствующих двум ценам, которые указываем над соответствующими линиями затрат: с1=2 руб./шт. и с2=1 руб./шт.

Рисунок 19 – График для задачи
Поскольку объем заказа, задаваемый формулой Уилсона , легко определяется зрительно как точка минимума обеих функций, то без предварительных вычислений графически находим объем Уилсона  и отмечаем его на графике.
и отмечаем его на графике.
Только после этого, используя параметры  руб.,
руб.,  шт. в день,
шт. в день,  руб. за 1 шт. в сутки, вычисляем значение и подписываем его на графике под обозначением .
руб. за 1 шт. в сутки, вычисляем значение и подписываем его на графике под обозначением .

Очевидно, что в область I  шт. не попадает, т.к.
шт. не попадает, т.к.  . Таким образом,
. Таким образом, 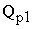 может попасть в области II или III. Границей между этими областями служит размер заказа
может попасть в области II или III. Границей между этими областями служит размер заказа  , уравнивающий общие затраты при цене со скидкой 1 руб./шт. и затраты при заказе по исходной цене 2 руб./шт. Сначала строим графически .
, уравнивающий общие затраты при цене со скидкой 1 руб./шт. и затраты при заказе по исходной цене 2 руб./шт. Сначала строим графически .

Рисунок 20 – График для задачи 2
Только после этого найдем численно. Используя рисунок 20, запишем выражение, показывающее равенство затрат,

с численными значениями параметров:

После использования уравнения общих затрат для ситуации, когда учитываются затраты на покупку товара , для раскрытия левой и правой частей выражения ,показывающего равенство затрат , получаем
 руб./сут.
руб./сут.



 шт. или
шт. или  шт.
шт.
Всегда выбираем больший из корней  , т.к. меньший по значению корень не дает нам информации о границе областей II и III , и отмечаем численное значение 26,18 на графике.
, т.к. меньший по значению корень не дает нам информации о границе областей II и III , и отмечаем численное значение 26,18 на графике.
Таким образом, точка разрыва цен попадает в область II, т.к.


Отметим эту точку на графике в любом месте области II (рисунок 21)

Рисунок 21 – Итоговый график задачи
После этого сплошной линией обведем те участки обеих функций затрат, которые соответствуют действующим ценам, т.е. до объема обведем верхнюю линию затрат, а после – нижнюю.
Согласно правилу и графику оптимальным является объем заказа  шт. по цене 1 руб./шт. Таким образом, в данной ситуации скидкой пользоваться выгодно. Общие затраты при этом составляют
шт. по цене 1 руб./шт. Таким образом, в данной ситуации скидкой пользоваться выгодно. Общие затраты при этом составляют  [руб./сут.]. Если бы заказывали по 10 шт. товара, то общие затраты составили бы 20 рублей, т.е. при заказе в 15 шт. экономия средств составляет 4,17 рублей в сутки.
[руб./сут.]. Если бы заказывали по 10 шт. товара, то общие затраты составили бы 20 рублей, т.е. при заказе в 15 шт. экономия средств составляет 4,17 рублей в сутки.
Задание 5.
Двенадцать экспертов оценили перспективный объем продажи механических наручных часов (тыс. шт.).
Таблица 4
Оценки экспертов
| Эксперт | ||||||||||||
| Прогноз | 7,8 | 9,6 | 13,1 | 8,4 | 10,2 | 11,6 | 12,5 | 13,6 | 9,8 | 10,4 |
Получить точечный и интервальный прогнозы объема продаж часов, используя метод статистической обработки результатов экспертных оценок.
Решение:
Рассчитываем среднее прогнозируемое значение объема продаж (точечный прогноз):
 (тыс.шт.)
(тыс.шт.)
Рассчитываем дисперсию прогнозируемого объема продаж:

Таблица 7
Вспомогательная таблица для расчета дисперсии
| Эксперт | Прогноз | 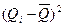
|
| 7,8 | 6,81 | |
| 9,6 | 0,65 | |
| 13,1 | 7,23 | |
| 8,4 | 4,04 | |
| 10,2 | 0,04 | |
| 11,6 | 1,41 | |
| 12,5 | 4,36 | |
| 13,6 | 10,17 | |
| 5,8 | ||
| 0,16 | ||
| 9,8 | 0,37 | |
| 10,4 | 0,0001 | |
| Итого | 41,04 |
Находим табличное значение t-критерия Стьюдента:
t(α = 0.05; 6) = 2,45
Находим ширину доверительного интервала:
 (тыс. шт.)
(тыс. шт.)
Нижняя граница прогноза:
 (тыс. шт.)
(тыс. шт.)
Верхняя граница прогноза:
 (тыс. шт.)
(тыс. шт.)
Вывод. С вероятностью 95% средний объем продаж механических наручных часов будет находиться в пределах от 9,05 до 11,77 тыс. шт.
Список используемой литературы.
1. Гмурман В.Е. Руководство к решению задач по теории вероятностей и математической статистике: Учеб.пособие для студентов втузов. – 3-е изд., перераб. И доп. – М.: Высш. школа, 2010г. [1]
2. Гармаш А.Н., Орлова И.В. Математические методы в управлении: учебное пособие.— М.: Вузовский учебник: ИНФРА-М, 2012.
3. Экономико-математические методы и прикладные модели: учебник для бакалавров / В.В. Федосеев, А.Н. Гармаш, И.В. Орлова; под ред. В.В. Федосеева.— 3-е изд., перераб. и доп.— М.: Юрайт, 2012.