|
|
Прогнозирование значений экономических показателей на основе трендовых моделей
Экономическое прогнозирование на основе трендовых моделей базируется на предположении, что закономерность развития, действовавшая в прошлом (внутри ряда экономической динамики), сохранится и в прогнозируемом будущем. В этом смысле прогноз основан наэкстраполяции. Экстраполяция, проводимая в будущее, называетсяперспективной, а в прошлое – ретроспективной.
Прогнозирование методом экстраполяции базируется на следующих предположениях:
а) развитие исследуемого явления в целом описывается плавной кривой;
б) общая тенденция развития явления в прошлом и настоящем не указывает на серьезные изменения в будущем;
в) учет случайности позволяет оценить вероятность отклонения от закономерного развития.
Поэтому надежность и точность прогноза зависят от того, насколько близкими к действительности окажутся эти предположения и насколько точно удалось охарактеризовать выявленную в прошлом закономерность.
На основе построенной модели рассчитываются точечные и интервальные прогнозы. Точечный прогноз  прогноз на основе временных моделей получается подстановкой в модель (уравнение тренда)
прогноз на основе временных моделей получается подстановкой в модель (уравнение тренда) 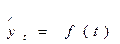 соответствующего значения фактора времени, т.е. t=n+1, n+2,..., n+k.
соответствующего значения фактора времени, т.е. t=n+1, n+2,..., n+k.
Точное совпадение фактических данных и прогностических точечных оценок, полученных путем экстраполяции кривых, характеризующих тенденцию, имеет малую вероятность. Возникновение соответствующих отклонений объясняется следующими причинами.
Выбранная для прогнозирования кривая не является единственно возможной для описания тенденции. Можно подобрать такую кривую, которая дает более точные результаты.
Прогноз осуществляется на основании ограниченного числа исходных данных. Кроме того, каждый исходный уровень обладает еще и случайной компонентой. Поэтому и кривая, по которой осуществляется экстраполяция, также будет содержать случайную компоненту.
Тенденция характеризует движение среднего уровня ряда динамики, поэтому отдельные наблюдения могут от него отклоняться. Если такие отклонения наблюдались в прошлом, то они будут наблюдаться и в будущем.
Интервальные прогнозы строятся на основе точечных прогнозов. Доверительным интервалом называется такой интервал, относительно которого можно с заранее выбранной вероятностью утверждать, что он содержит значение прогнозируемого показателя. Ширина интервала зависит от качества модели, т.е. степени ее близости к фактическим данным, числа наблюдений, горизонта прогнозирования и выбранного пользователем уровня вероятности.
При построении доверительного интервала прогноза рассчитывается величина отклонения от линии тренда U(k), которая для линейной модели имеет вид /1/:
 ,
,
где 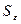 - стандартная ошибка модели (среднеквадратическое отклонение от линии тренда):
- стандартная ошибка модели (среднеквадратическое отклонение от линии тренда):
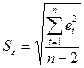 .
.
Коэффициент  [3] является табличным значениемt-статистики Стьюдента при заданном уровне значимости α и числе степеней свободы n-2. Если исследователь задает уровень вероятности попадания прогнозируемой величины внутрь доверительного интервала, равным 70%, то при n =9 коэффициент = 1,12. При вероятности, равной 95%, будет = 2,36.
[3] является табличным значениемt-статистики Стьюдента при заданном уровне значимости α и числе степеней свободы n-2. Если исследователь задает уровень вероятности попадания прогнозируемой величины внутрь доверительного интервала, равным 70%, то при n =9 коэффициент = 1,12. При вероятности, равной 95%, будет = 2,36.
Для других моделей величина U(k) рассчитывается аналогичным образом, но имеет более громоздкий вид. Как видно из формулы, величина U зависит прямо пропорционально от точности модели, коэффициента доверительной вероятности  , степени углубления в будущее на k шагов вперед (т.е. на момент t = n+k) и обратно пропорциональна объему наблюдений. Доверительный интервал прогноза будет иметь следующие границы:
, степени углубления в будущее на k шагов вперед (т.е. на момент t = n+k) и обратно пропорциональна объему наблюдений. Доверительный интервал прогноза будет иметь следующие границы:
– верхняя граница прогноза = прогноз(n+k) + U(k);
– нижняя граница прогноза = прогноз(n+k) – U(k).
Если построенная модель адекватна, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадает в интервал, образованный верхней и нижней границей.
Пример.
По месячным данным об объемах реализации аудиторских услуг организации (уt,факт на рис. 2): оценить наличие в ряду аномальных наблюдений; построить линейную трендовую модель; оценить ее адекватность и точность; осуществить прогноз выручки на последующих два месяца(доверительная вероятность - 70%). Фактические значения показателя, результаты моделирования и прогнозирования представить графически.
Решение
Оценим методом Ирвина наличие в ряду (уt,факт) аномальных наблюдений (см. рис. 2, n =9). После чего получим МНК-оценки параметров  линейной модели кривой роста (линейной трендовой модели):
линейной модели кривой роста (линейной трендовой модели):
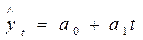 .
.
Для автоматизации расчетов используем программу Регрессия надстройки (статистического пакета) Анализ данных Excel (основное меню Сервис/Анализ данных/ Регрессия). На рис.2 показано оформление окна диалога Регрессияуказанной программы.

Рис.2. Применение метода Ирвина и оформление окна диалога Регрессия
После выполнения команды ОКна лист с заданным названиемРезультаты регрессиивыводятся итоги расчетов (результаты регрессионного анализа). Ниже в таблицах 1 и 2 приводятся фрагменты этого листа.
Таблица 1
| Коэффициенты | Стандартная ошибка | t-статистика | |
| Y-пересечение | 20,33 | 1,920785774 | 10,5859454 |
| t | 7,13 | 0,341332589 | 20,89848306 |
Второй столбец таблицы 1 содержит параметры модели, т.е. получена следующая модель кривой роста (трендовая модель):
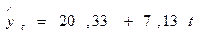 .
.
Таблица 2
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное yt,факт. | Остатки |
| 27,47 | -2,47 | |
| 34,60 | -0,60 | |
| 41,73 | 0,27 | |
| 48,87 | 2,13 | |
| 56,00 | -1,00 | |
| 63,13 | 3,87 | |
| 70,27 | 2,73 | |
| 77,40 | -1,40 | |
| 84,53 | -3,53 |
3. Для оценки адекватности построенной модели исследуются свойства остаточной компоненты (остатков) 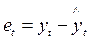 (t = 1, 2, … , 9), т.е. расхождения уровней, рассчитанных по модели, и фактических наблюдений (Таблица 2).
(t = 1, 2, … , 9), т.е. расхождения уровней, рассчитанных по модели, и фактических наблюдений (Таблица 2).
· С помощью функции =СРЗНАЧ убеждаемся, что для рассматриваемой линейной модели действительно  = 0, так что гипотеза о равенстве математического ожидания значений ряда остатков нулю выполняется.
= 0, так что гипотеза о равенстве математического ожидания значений ряда остатков нулю выполняется.
· Проверку случайности уровней ряда остатков проведем на основе критерия поворотных точек.
Количество поворотных точек в ряду остатков р=3 (см. рис. 3)
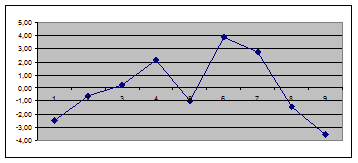
Рис. 3. График остатков
Неравенство критерия поворотных точек выполняется:
 .
.
Следовательно, свойство случайности выполняется.
· При проверке свойства независимости оценивается наличие (отсутствие) автокорреляции в ряду остатков.Воспользуемся коэффициентом автокорреляции (первого порядка) и получим его значение с помощью функции Excel =КОРРЕЛ (в первый массив включаем остатки с первого по восьмой включительно, во второй массив – остатки со второго по девятый включительно):
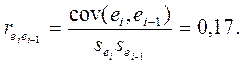
Оценим его значимость с применением  - критерия Стьюдента. Для этого рассчитаем значение - критерия по формуле:
- критерия Стьюдента. Для этого рассчитаем значение - критерия по формуле:
 =0,45.
=0,45.
Табличное значение  критерия Стьюдента с уровнем значимости
критерия Стьюдента с уровнем значимости 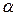 =0,05 и
=0,05 и  =7 степенями свободы получим с помощью функции Excel =СТЬЮДРАСПОБР(0,05;7) = 2,36. Сравним его с расчетным значением - критерия (
=7 степенями свободы получим с помощью функции Excel =СТЬЮДРАСПОБР(0,05;7) = 2,36. Сравним его с расчетным значением - критерия ( 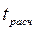 =0,45). Поскольку
=0,45). Поскольку  , то полученное значение коэффициента автокорреляции
, то полученное значение коэффициента автокорреляции  незначимо и делаются вывод об отсутствии автокорреляции в ряду остатков, т.е. свойство независимости остатков выполняется.
незначимо и делаются вывод об отсутствии автокорреляции в ряду остатков, т.е. свойство независимости остатков выполняется.
· Соответствие ряда остатков нормальному закону распределения проверим с помощью R/S-критерия
 , где
, где  =3,87 и
=3,87 и  = -3,53 соответственно максимальный и минимальный уровни ряда остатков;
= -3,53 соответственно максимальный и минимальный уровни ряда остатков; 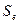 =2,47- среднеквадратическое отклонение в ряду остатков (вычисляем с помощью функции =СТАНДОТКЛОН).
=2,47- среднеквадратическое отклонение в ряду остатков (вычисляем с помощью функции =СТАНДОТКЛОН).
Расчетное значение этого критерия попадает между табулированными границами (2,7—3,7) (для n = 9 и 5%-ного уровня значимости), то гипотеза о нормальном распределении ряда остатков принимается.
Построенная модель по всем критериям адекватна, т.е. адекватна в целом.
4. Для оценки точности модели определим среднюю относительную ошибку аппроксимации:  .
.
Расчет по этой формуле удобно провести в Excel:
| Оценка точности: | ||
| yt, факт. | abs остатков | Расчет Еотн |
| 2,47 | 0,098666667 | |
| 0,60 | 0,017647059 | |
| 0,27 | 0,006349206 | |
| 2,13 | 0,041830065 | |
| 1,00 | 0,018181818 | |
| 3,87 | 0,057711443 | |
| 2,73 | 0,037442922 | |
| 1,40 | 0,018421053 | |
| 3,53 | 0,043621399 | |
| Еотн = | 3,78% |
Таким образом, получена модель достаточно высокой точности (Еотн до 5-7%, модель считается /50/ удовлетворительной точности при Еотн до 10%).
5. Осуществим на основе построенной модели прогноз выручки на два месяца вперед (доверительная вероятность - 70%).
Точечный прогноз прогноз(n+ к) на к – шагов вперед получается путем подстановки в модель соответствующего значения фактора времени, т.е. t= n+k (для рассматриваемой задачи к=1, к=2):
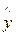 прогноз (n+1) = 20,33 + 7,13∙ t = 20,33 + 7,13∙10 = 91,63,
прогноз (n+1) = 20,33 + 7,13∙ t = 20,33 + 7,13∙10 = 91,63,
прогноз (n+2) = 20,33 + 7,13∙ t = 20,33 + 7,13∙11 = 98,76.
Для построения интервального прогноза определяем ширину доверительного интервала по формуле:
,
где - стандартная ошибка модели (среднеквадратическое отклонение от тренда, см. вывод итогов на листе Результаты регрессии):
 .
.
Коэффициент =СТЬЮДРАСПОБР(0,3;7) = 1,12 является табличным значениемt-статистики Стьюдента при заданном уровне значимости 0,3 (доверительной вероятности 70%) и числе степеней свободы (n – 2)=7.
Итак:  ,
,
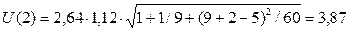 .
.
Доверительный интервал прогноза будет иметь следующие границы (верхняя граница прогноза равна прогноз(n+к) + U(к), нижняя граница прогноза - прогноз(n+к) – U(к)):
| Время t | Шаг k | Прогноз | Нижняя граница | Верхняя граница |
| 91,63 | 87,98 | 95,28 | ||
| 98,76 | 94,89 | 102,63 |
6. Представим графически результаты моделирования и прогнозирования.
Это удобно сделать путем доработки Графика подбора, полученного при выводе итогов работы программы Регрессия на лист Результаты регрессии (рис. 4).
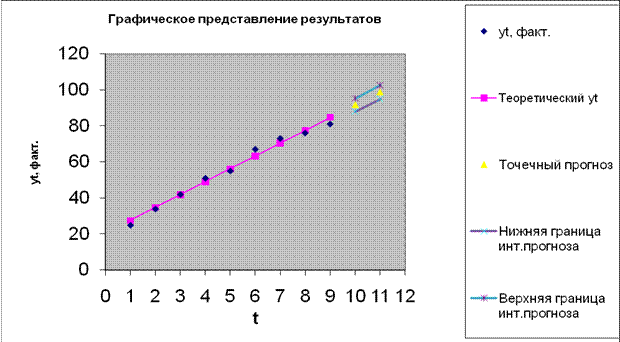
Рис. 4. Графическое представление результатов моделирования и прогнозирования
Таким образом, с вероятностью 70% объем реализации аудиторских услуг в следующем месяце будет находиться в пределах от 87,98 до 95,28у.е., а через месяц - в пределах от 94,89 до 102,63у.е.
Более подробно описание использования средств Excel при решении подобных задач приведено в литературе /3/.
Кроме линейной кривой роста для моделирования и прогнозирования экономических показателей часто используются и другие кривые роста, например: полиномиальные кривые роста (полином второй степени  , третьей степени
, третьей степени  и т.д.); экспоненциальная кривая роста
и т.д.); экспоненциальная кривая роста 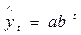 , степенная -
, степенная - 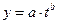 .
.
Модели этих кривых роста можно получить с помощью средств Excel (Мастер диаграмм/Точечная/Добавить линию тренда):
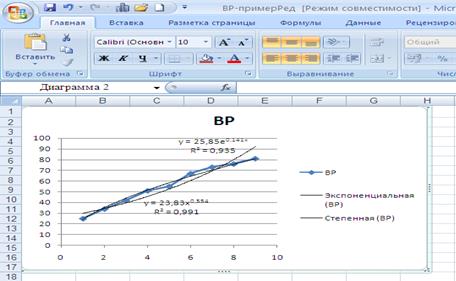
На рис. представлены экспоненциальная и степенная кривые, аргумент функций обозначен x (вместо t).
[1] Экстраполяция - это распространение выявленных при анализе рядов динамики закономерностей развития изучаемого объекта на будущее (при предположении, что выявленная закономерность, выступающая в качестве базы прогнозирования, сохраняется и в дальнейшем).
[2] (intact – целый, англ.)
[3] Значение можно получить с помощью функции Excel =СТЬЮДРАСПОБР.