|
|
ТЕОРЕТИЧЕСКИЕСВЕНИЯ
Способы контроля правильности передачи данных. Код с проверкой на четность. Контроль целостности информации при передаче от источника к приемнику может осуществляться с использованием корректирующих кодов.
Простейший корректирующий код - код с проверкой на четность, который образуется добавлением к группе информационных разрядов одного избыточного, значение которого выбирается таким образом, чтобы сумма единиц в кодовой комбинации, Т.е. вес кодовой комбинации, была всегда четна.
Пример 3.1. Рассмотрим код с проверкой на четность, образованный добавлением контрольного разряда к простому двоичному коду:

Такой код обнаруживает все одиночные ошибки и групповые ошиб I<и нечетной кратности, так как четность количества единиц в этом случае будет также нарушаться.
Следует отметить, что при кодировании целесообразно число единиц в кодовой комбинации делать нечетным и осуществлять контроль на нечетность. В этом случае любая комбинация в том числе и изображающая ноль, будет иметь хотя бы одну единицу, что дает возможность отличить полное отсутствие информации от передачи нуля.
Коды Хэмминга. N - значный код Хэмминга имеет m - информационных разрядов и k - контрольных. Число контрольных разрядов должно удовлетворять соотношению

откуда 
Код Хэмминга строится следующим образом; к имеющимся информационным разрядам кодовой комбинации добавляется вычисленное по вышеприведенной формуле количество контрольных разрядов, которые формируются путем подсчета четности суммы единиц для определенных групп информационных разрядов. При приеме такой кодовой комбинации из полученных информационных и контрольных разрядов путем аналогичных подсчетов четности составляют корректирующее число, которое равно нулю, при отсутствии ошибки, либо указывает номер ошибочного разряда.
Рассмотрим подробнее процесс кодирования. Пусть первый контрольный разряд имеет нечетный порядковый номер, установим его при кодировании таким образом, чтобы сумма единиц всех разрядов с нечетными порядковыми номерами была равна нулю. Такая операция может быть записана в виде следующего соотношения:

где а1 а3, a5, а7 - двоичные символы, размещенные в разрядах с номерами 1, З, 5, 7, ...
Появление единицы во втором разряде (справа) корректирующего числа означает ошибку в тех разрядах кодовой комбинации, порядковые номера которых (2, 3, 6, 7, ... ) в двоичном изображении имеют единицу во втором справа разряде. Поэтому вторая операция кодирования, позволяющая найти второй контрольный разряд, имеет вид
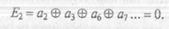
Рассуждая аналогичным образом:

После приема кодовой комбинации совместно со сформированными контрольными разрядами выполняются те же операции подсчета, что были описаны выше, а полученное число
Ек, Ек-1 ... Е2, Е1
считается корректирующим, причем при Ек, Ек-1 ... Е2, Е1 = 0 ошибки отсутствуют; а при наличии ошибок неравными нулю оказываются те суммы Е;, в образовании которых участвовал ошибочный разряд. Корректирующее число при этом будет равно порядковому номеру этого разряда.
Выбор места для контрольных разрядов в каждой из кодовых комбинаций определяется таким образом, чтобы контрольные разряды участвовали только в одной операции подсчета четности. Такими позициями являются целые степени двойки: 1,2,4,8, 16, ...
Пример 3.2. Составим шестизначный код Хэмминга (табл. 3.1) для n = 6, k >=log27, k=3, m=n-k=3
Таблица 3.1
| Цифра | Простой | Код Хэмминга |
| двоичный код | ||
| О | ||
Варианты исправления ошибок:
принят код: 111100 исправлено 110100 - ошибка по корректирующему числу в разряде 4;
принят код: 111010 исправлено 101010 - ошибка по корректирующему числу в разряде 5;
принят код: 100000 исправлено 000000 - ошибка по корректирующему числу в разряде 6.
Циклические коды. Циклические коды - разновидность систематических кодов и поэтому обладают всеми их свойствами. Характерной Особенностью циклического кода, определяющей его название, является то, что если
n-значная кодовая комбинация а0 al а2 ... аn-1 аn принадлежит данному коду, то и комбинация аn а0 al а2 ... аn-1, полученная циклической перестановкой знаков, также принадлежит этому коду.
Идея построения циклических кодов базируется на использовании неприводимых многочленов. Неприводимым называется многочлен, который не может быть представлен в виде произведения многочленов низших степеней, т.е. такой многочлен, который делится только на самого себя или на единицу.
Неприводимые многочлены при построении циклических кодов играют роль так называемых образующих полиномов, от вида которых, собственно, и зависят основные характеристики полученного кода: избыточность и корректирующая способность. В таблице 3.2 указаны неприводимые многочлены со степенями k = 1,2,3,4.
Таблица 3.2
| к | р(х) | Р(1,0) |
| k=1 | х + 1 | |
| k=2 | х2+ x+ 1 | |
| k=3 | х3+х+1 | |
| x3+ х2+l | ||
| k=4 | х4+х+1 | |
| х4+х3+1 | ||
| x4+x3+ х2+x+1 |
Основные принципы кодирования в циклическом коде заключаются в следующем. Двоично-кодированное n-разрядное число представляется полиномом (n - l)-й степени некоторой переменной х, причем коэффициентами полинома являются двоичные знаки соответствующих разрядов. Запись, чтение и передача кодовых комбинаций в циклическом коде производятся, начиная со старшего разряда. В соответствии с этим правилом в дальнейшем сами числа и соответствующие им полиномы будем записывать так, чтобы старший разряд оказывался справа:
Пример 3.3. Число110101 (нумерация разрядов согласно выше приведенному правилу, ведется слева направо от О до 5) будет представлено полиномом пятой степени: 1 +х +х3 +х5.
Следует отметить, что циклическая перестановка разрядов в двоичном представлении числа соответствует умножению полинома на х, при котором xn заменяется единицей и переходит в начало полинома.
Пример 3.4. Выполним умножение полинома, полученного в предыдущем при мере, на х. Новый полином: х + х2 + х4 + х6 преобразуем, заменив х6 на 1.
Окончательно получим 1 + х +х2 + х4, что соответствует числу 111010.
Циклический код n-значного числа, как и всякий систематический код, состоит из m информационных и k контрольных знаков, причем последние занимают k младших разрядов. Поскольку последовательная передача кодовых комбинаций производится, как уже указывалось, начиная со старших разрядов, контрольные знаки передаются в конце кода.
Образование кода выполняется при помощи так называемого порождающего полинома, р(х) степени k, видом которого определяются основные свойства кода - избыточность и корректирующая способность.
Кодовым полиномом F(x) является полином степени, меньшей (m + k), если он делится без остатка на порождающий полином Р(х). После передачи сообщения декодирование состоит' в выполнении деления полинома Н(х), соответствующего принятому коду, на Р(х). При отсутствии ошибок Н(х) = F(x), и деление выполняется без остатка, Наличие ненулевого остатка указывает на то, что при передаче или хранении про изошли искажения информации.
Для получения систематического циклического кода используется следующее соотношение:

где G(x) - полином, представляющий информационные символы (информационный полином); R(х) - остаток от деления xkG(x) на Р(х).
Пример 3.5.Рассмотрим кодирование восьмизначного числа 10110111. Пусть для кодирования задан порождающий полином третий степени Р(х) = 1 + х + х3.
Делим х3G(x) на P(х): G(x) = 1 + х2 + х3 + х5 + х6 + х7;
х3G(x) =х3 + х5 + х6 + х8 + х9 + xl0;

Используя соотношение для получения систематического циклического кода, находим F(x):
F(x) = (х3 + х5 + х6 + х8 + х9 + xl0)  х2.
х2.
Таким образом, окончательно кодовая комбинация, соответствующая F(x), имеет вид

Практически применяемая процедура кодирования еще более проста. Так как нас интересует только остаток, а частное в конечном результате не используется, то можно производить последовательное вычитание по mod 2 делителя из делимого и полученных разностей до тех пор, пока разность не будет иметь более низкую степень, чем делитель. Эта разность и есть остаток. Такой алгоритм может быть реализован аппаратно при помощи k-разрядного сдвигающего регистра, имеющего обратные связи. Очевидно, что полученный этим способом циклический код будет являться систематическим.
Существует и второй способ получения циклического кода, когда очередная кодовая комбинация образуется путем умножения кодовой комбинации С(х) простого n-значного кода на образующий полином Р(х). При этом способе образования циклических кодов информационные и контрольные символы в комбинациях циклического кода не отделены друг от друга, что затрудняет процесс декодирования. Поэтому такой способ кодирования применяется реже, чем первый.
Пример 3.6. Рассмотрим кодирование вторым способом, причем при выполнении операций будем использовать непосредственно записи исходных кодовых комбинаций в двоичном виде. Дан порождающий полином вида Р(1,0) = 1101. Требуется построить циклический код из простого четырехзначного кода вторым способом. Для построения в качестве примера используем исходную комбинацию С(1 ,О) = 0011. Операция умножения этой комбинации на образующий полином запишется следующим образом:

Аналогичным образом получены остальные кодовые комбинации несистематического циклического кода, приведенные в табл. 3.3.
Таблица 3.3
| Простой четырехсимвольный код | Циклический (7,4) - код |
| С(х) | С(х) Р(х), где Р(I,О) = 1101 |
| 0011·• | 0010111 • |
Проблема обнаружения различного типа ошибок с помощью циклического кода, как уже указывалось, сводится к нахождению нужного порождающего полинома. В нашу задачу не входит рассмотрение этого вопроса, достаточно полно основные принципы подбора порождающих полиномов изложены в учебнике'.
Эффективное кодирование информации. Общие положения. Напомним, что кодирование - это представление сообщений в форме, Удобной для передачи по данному каналу, а декодирование - восстановление информации по принятому сигналу. Одним из важнейших Вопросов кодирования является повышение его эффективности, т.е. путем устранения избыточности снижение среднего числа символов, требующихся на букву сообщения. Такое кодирование получило название эффективное кодирование. Из сказанного выше следует, что Эффективное кодирование решает задачу максимального сжатия информации.
Учитывая статистические свойства источника информации, можно минимизировать среднее число двоичных символов, требующихся для выражения одной буквы сообщения, что при отсутствии помех позволяет уменьшить время передачи сообщения и его объем.
Эффективное кодирование базируется на основной теореме Шеннона для канала без помех, суть которой сводится к следующему: сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины.
Наличие в сообщениях избыточности позволяет рассматривать вопрос о сжатии данных, т.е. о передаче того же количества информации с помощью последовательностей символов меньшей длины - методы сжатия без потерь (обратимые). Для этого используют специальные алгоритмы сжатия, уменьшающие избыточность. Эффект сжатия оценивают коэффициентом сжатия
K=n/q,
где n - число минимально необходимых символов для передачи сообщения;
q - число символов в сообщении, сжатом данным методом.
Так, при эффективном двоичном кодировании n равно энтропии источника информации.
Наряду с методами сжатия, не уменьшающими количество информации в сообщении, применяют методы сжатия, основанные на потере малосущественной информации, - методы сжатия с потерями (необратимые). Следует отметить, что применение методов сжатия с потерями неприемлемо для некоторых видов информации, например текстовой или числовой.
Обратимое сжатие всегда приводит к снижению объема выходного потока информативности. Из выходного потока при помощи восстанавливающего алгоритма можно получить исходный поток.
Основные методы обратимого сжатия:
• Шеннона - Фан о (Shannon - Рапо);
• Хаффмена (Huffman);
• LZW (Lanper - Ziv - Welch);
• арифметическое сжатие.
Преобразование входного потока данных, при котором выходной поток представляет похожий по внешним характеристикам на входной поток объект, однако отличается от него объемом. Используется понятие качества - степени соответствия исходного и результирующего потока.
Основные алгоритмы необратимого сжатия'
• MPEG (Moving Pictues Experts Group);
• JPEG (Joint Photographic Expert Group);
• фрактальное сжатие.
Простейший способ сжатия числовой информации, представленной в коде ASCII, заключается в использовании сокращенного кода с четырьмя битами на символ вместо восьми, так как в ASCII-кодировке цифры, а также символы «.», «,» И « » В качестве первого кодового символа имеют нуль, который может быть отброшен.
Среди широко используемых благодаря своей простоте алгоритмов сжатия наиболее известен алгоритм RLE (Run Length Encoding), в котором вместо передачи цепочки из одинаковых символов передаются символ и значение длины цепочки. Этот метод эффективен при передаче растровых изображений, особенно монохромных, где имеется большое число цепочек из единиц и «улей, но малополезен при передаче текста. Алгоритм RLE реализован в формате PCX.
Пример З. 7. Рассмотрим сжатие по алгоритму RLE. Исходный текст (9 байт); 77 77 77 7711 11.11 01 FF
В исходной последовательности;
1) выделяется повторяющаяся последовательность байт;
2) заменяется счетчиком повторов (04) и кодирующим байтом (77);
3) 00 - нет повторений;
4) 02 - сколько байт не повторяется;
5) какие байты не повторяются (01 FF).
Результат сжатия (8 байт); 04 77 03 11 0002 01 FF.
Недостатками алгоритма RLE являются:
• низкая степень сжатия;
• сильная зависимость от количества повторов байт в исходной информационной последовательности.
Достоинство этого алгоритма состоит в простоте его реализации. Основная сфера использования методов сжатия с потерями - графические, аудио- и видеофайлы, где есть возможность, частично пожeртвовaния качественными характеристиками информации, добиться Значительного уменьшения ее объемов.
Наибольшее распространение среди методов сжатия информации без потерь нашли статистические алгоритмы сжатия, учитывающие вероятность появления отдельных символов в информационном потоке. В первую очередь это алгоритмы Шеннона - Фано и Хаффмена.
Алгоритм Шеннона - Фано. Эффективное кодирование методом Шеннона - Фано базируется на основной теореме Шеннона для канала без помех.
Алгоритм Шеннона - Фано:
• буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей;
• буквы алфавита разделяются на две группы так, чтобы суммы вероятностей в каждой группе были по возможности одинаковы;
• всем буквам верхней половины в качестве первого символа приписывается единица, а всем нижним - нули;
• каждая из полученных групп в свою очередь разбивается на две подгруппы с одинаковыми суммарными вероятностями и Т.д., процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Пример 3.8. Рассмотрим алфавит из семи букв, приписав каждой букве вероятность ее появления в сообщении Pi (существуют специальные таблицы вероятности появления букв русского или латинского алфавитов в сообщениях, например, табл. З.4).
Таблица 3.4

При обычном двоичном кодировании, не учитывая статистических характеристик, для представления каждой буквы потребуется три символа. Наибольший эффект сжатия получается в случае, когда вероятности букв представляют собой целочисленные отрицательные

степени двойки. Среднее число символов на букву в ЭТОМ случае точно равно энтропии.
Среднее число символов на букву

где Рi - вероятность появления i-гo символа алфавита; ni, - количество символов в кодовой комбинации i-гo символа алфавита.
Для рассмотренного примера 3.8

Разность величин (L - Н) - избыточность кода, а величина (L - Н)/L - относительная избыточность.
Избыточность может трактоваться как мера бесполезно совершаемых альтернативных выборов. Поскольку в практических случаях отдельные знаки никогда не встречаются одинаково часто, то кодирование с постоянной длиной кодовых слов в большинстве случаев избыточно. Несмотря на это, руководствуясь техническими соображениями, такое кодирование применяется достаточно часто.
Алгоритм Хаффмена. Суть алгоритма Хаффмена сводится к следующему:
• буквы алфавита сообщений выписываются в основной столбец таблицы в порядке убывания вероятностей;
• две последние буквы объединяются в одну вспомогательную букву, которой приписывается суммарная вероятность;
• вероятности букв, не участвовавших в объединении, и полученная суммарная вероятность снова располагаются в порядке убывания вероятностей, а две последние объединяются до тех пор, пока не получают единственную вспомогательную букву с вероятностью единица;
• далее для построения кода используется бинарное дерево, в корне которого располагается буква с вероятностью единица, при ветвлении ветви с большей вероятностью присваивается код единица, а с меньшей - код ноль (возможно левой - единица, а правой ноль).
Пример 3.9. Рассмотрим условный алфавит из восьми букв, каждой из которых приписала соответствующая вероятность ее появления в сообщении (табл. 3.5).
Таблица 3.5

L=0,22 * 2 + 0,20 * 2+ 0,16 * 3 +0,16 * 3 + O,lOx 3 +0,10 * 4+0,04 * 5 + 0,02 * 5 = 2,8;
Н=2,76;
L- Н=0,04.
Для сравнения: в коде Шеннона с таким же распределением вероятностей L - Н = 0,08. Бинарное дерево изображено на рис. 3.1.

Рис. 3.1. Бинарное дерево
Для построения кодов Шеннона - Фано и Хаффмена можно использовать таблицу вероятности отдельных букв в русском языке (табл. 3.6).
Таблица 3.6
| Буква | Вероятность | Буква | Вероятность |
| О 175 | Я | ||
| О | Ы | 0,016 | |
| Е | |||
| А | Ъ,Ь | ||
| И | Б | ||
| Т | Г | ||
| Н | Ч | ||
| С | Й | ||
| Р | Х | ||
| В | Ж | ||
| Л | Ю | 0,006 | |
| К | Ш | ||
| М | Ц | ||
| Д | Щ | ||
| П | Э | ||
| У | Ф | 0,002 |