|
|
Задания для самостоятельной paбoты
1. Написать процедуру, обеспечивающую эффективное кодирование и подсчет среднего количества информации на знак Нi; избыточности (L - Н) и относительной избыточности получаемого кода (L - Н)/L. для тестирования программы использовать два контрольных варианта, приведенных в табл. 3.7
Таблица 3.7
| Буква | Вариант 1 | Вариант2 , | ||
| Вероятность | Код Шеннона | Вероятность | Код Хаффмена | |
| Z1 | 0,22 | 1/2 | ||
| Z2 | 0,20 | 1/4 | ||
| Z3 | 0,16 | 1/8 | ||
| Z4 | 0,16 | 1/16 | ||
| Z5 | 0,10 | 1/32 | ||
| Z6 | 0,10 | 1/64 | ||
| Z7 | 0,04 | 1/128 | ||
| Z8 | 0,02 | Н = 2,76; L = 2,84; L-H=0,08 | 1/128 | Н= 16/64; L= 163/64; L-H·>0 |
2. Источник сообщений порождает знаки А, В, С с вероятностями 0,7; 0,2; 0,1.
Написать процедуру, позволяющую:
• определить энтропию источника;
• указать для этих трех знаков оптимальное бинарное кодирование и определить среднюю длину кодовых комбинаций;
• закодировать все пары АА, АВ, ... (табл. 3.8);
• построить для этих девяти пар оптимальный бинарный код;
• увеличить блочность кода до трехсимвольных комбинаций и построить оптимальный бинарный код.
Сделать вывод об изменении избыточности кода с увеличением блочности. Как это влияет на эффективность кода?
Таблица 3.8
| Буква | Вероятность | КОД | Знак | Вероятность | Код-пары |
| А | 0,7 | О | АА | 0,49 | |
| В | 0,2 | АВ | 0,14 | ||
| С | 0,1 | ВА | 0,14 | ||
| АС | 0,07 | ||||
| СА | 0,07 | ||||
| ВВ | 0,04 | ||||
| ВС | 0,02 | ||||
| СВ | 0,02 | ||||
| СС | 0,01 | ||||
| Н = 1,1571; L = 1,3; Lзнак = 2,33; Lсимвол = Lзнак /2 = 1,165 |
LZW-сжатие. Одним из наиболее широко используемых в настоящее время методов сжатия без потерь является алгоритм Лемпела - Зива - Уэлча (Lempel - Ziv - Welch).
Метод сжатия был предложен в 1977 г., усовершенствованный (Теrrу Welch) вариант был опубликован в 1984 г. В дальнейшем этот метод неоднократно модернизировался. Этот алгоритм используется, в частности, стандартной процедурой UNIX Compress. Алгоритмы группы LZ (LZ77, LZ78, LZSS) лежат в основе почти всех современных программных и аппаратных средств сжатия информации. Архиваторы PКZIP, LНA, Stacker, SuperStor, Dblspace и многие другие используют ту или иную модификацию алгоритма LZ.
Идея сжатия, предложенная Лемпелом и Зивом, заключается в следующем: если в тексте сообщения появляется последовательность из двух ранее уже встречавшихся символов, то эта последовательность объявляется новым символом, для нее назначается код, который при определенных условиях может быть значительно короче исходной последовательности. В дальнейшем в сжатом сообщении вместо исходной последовательности записывается назначенный код. При декодировании повторяются аналогичные действия и потому становятся известными последовательности символов для каждого кода.
Процесс кодирования.
1. Каждому символу исходного алфавита присваивается определенный код (здесь код - порядковый номер, начиная с нуля).
2. Выбирается первый символ сообщения и заменяется на его код.
3. Выбираются следующие два символа и заменяются своими кодами. Одновременно этой двухсимвольной комбинации присваивается свой код (обычно это порядковый номер, равный числу уже использованных кодов). Так, если алфавит включает восемь символов, имеющих коды от 000 до 111, то первая двухсимвольная комбинация получит код 1000, следующая - код 1001 и т.д.
4. Выбираются из исходного текста очередные 2, 3, ... N-символьные комбинации до тех пор, пока не образуется еще не встречавшаяся комбинация. Тогда этой комбинации присваивается очередной код, и поскольку совокупность из первых N - 1 символов уже встречалась, то она имеет свой код, который и записывается вместо этих N - 1 символов. Каждый акт введения нового кода назовем шагом кодирования.
5. Процесс продолжается до исчерпания исходного текста.
Процесс декодирования. При декодировании код первого символа, а затем второго и третьего заменяются на символы алфавита. При этом становится известным код комбинации второго и третьего символов. В следующей позиции могут быть только коды уже известных символов и их комбинаций. Процесс декодирования продолжается до исчерпания сжатого текста.
Пример 3.10. Пусть исходный текст представляет собой двоичный код (первая строка табл. 3.9), Т.е. исходный алфавит А = {1, О}. Коды этих символов соответственно также О и 1.
Образующийся по методу Лемпела - Зива LZ-код показан во второй строке табл. 3.9. В третьей строке отмечены шаги кодирования, после которых происходит переход на представление кодов А с увеличенным числом разрядов r. Так, на первом шаге вводится код 10 для комбинации 00 и поэтому на следующих двух шагах r = 2, после третьего шага r= 3, после седьмого шага г=4. В общем случае г=k после шага 2k-1 - 1.
В приведенном примере LZ-код оказался даже длиннее исходного кода, так как обычно короткие тексты с небольшим количеством повторяющихся символов не дают эффекта сжатия. Эффект сжатия проявляется в достаточно длинных текстах и особенно заметен, например, в графических файлах.
Таблица 3.9
| Исходный текст | 0.00.000.01.11.111.1111.110.0000.00000.1101.1110. |
| LZ-код | 0.00.100.001.0011.1011.1101. 1010.00110.10010.10001.10110. |
| г | |
| Вводимые коды | - 10 11100 101110 1111000 10011010 10111100 |
Усовершенствованный алгоритм сжатия и распаковки по методу Лемпела - Зива - Уэлча приведен ниже:
Алгоритм компрессии:
СТРОКА = очередной символ из входного потока WHILE входной поток не пуст 00
СИМВОЛ = очередной символ из входного потока
IF СТРОКА + СИМВОЛ в таблице строк THEN
СТРОКА = СТРОКА + СИМВОЛ
ELSE
вывести в выходной поток код для СТРОКА
добавить в таблицу строк СТРОКА + СИМВОЛ
СТРОКА = СИМВОЛ
ENO of IF ENO of WHILE
вывести в выходной поток код для СТРОКА
Алгоритм декомпрессии:
Читать СТАРЫЙ_КОД
вывести СТАРЫЙ_КОД
WHILE входной поток не пуст DO
читать НОВЫЙ_КОД
СТРОКА = перевести НОВЫЙ_КОД
вывести строку
СИМВОЛ = первый символ СТРОКИ
добавить в таблицу перевода СТАРЫЙ_КОД + СИМВОЛ
СТАРЫЙ_КОД = НОВЫЙ_КОД
END of WНILE
На рисунке 3.2 представлен пример программной реализации алгоритма LZW.
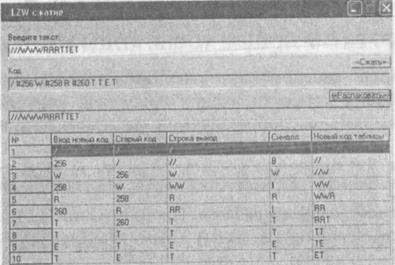
Рис. 3.2. Пример программной реализации алгоритма LZW