|
|
Материнська плата ASUS P8P67 Deluxe Rev 3.0
Одна з флагманських моделей серії P8P67, побудована на основі набору системної логіки Intel P67 Express. На рисунку 1.3 зображена материнська плата ASUS P8P67 Deluxe Rev 3.0.

Рисунок 1.3 - Материнська плата ASUS P8P67 Deluxe Rev 3.0
Перша модифікація цієї материнської плати була випущена майже відразу після офіційної презентації платформи Sandy Bridge і чипсетів шестидесятих серії. Після відкликання системної логіки ревізії B2 її продажі були припинені, і зараз на прилавках можна знайти нову модифікацію на основі чипсета ревізії B3, що окремо підкреслюється в назві.
На додаток до інтерфейсів, реалізованих на рівні чипсета, на платі встановлені контролери Marvell на два порти Serial ATA 6 Гбіт / с, JMicron JMB363 на два порти eSATA 3 Гбіт / с, NEC μPD720200 на чотири порти UAB 3.0, VIA 6315N на два порти IEEE 1394a (FireWire), міст PCIe-OCI ASMedia ASM1083 на три пристрої, додатковий гігабітний мережевий контролер Realtek 8111E, контролер Bluetooth 2.1 + EDR і багатоканальний (7.1) звуковий кодек Realtek ALC 889. Підтримка інтерфейсу IDE відсутня.
Для розгону системи використовується чип ASUS TurboV EVO і однойменна утиліта. У комплект постачання входить модуль на два порти USB 3.0 для установки в зовнішній 3,5-дюймовий відсік (для флоппі-дисководів). Реалізований на платі стабілізатор живлення має 23 каналу: шістнадцять з них виділені для обчислювальних ядер процесора, два для вбудованого відеоядра, два для "системного агента" і три для модулів пам'яті. До складу системи живлення включений фірмовий контролер широтно-імпульсної модуляції (ШІМ) Digi + VRM, яка вміє автоматично регулювати частоту, змінювати навантаження каналів в залежності від температури і відключати невикористовувані канали живлення процесора. У конструкції використовуються тільки високоякісні полімерні конденсатори японського виробництва.
Серед особливостей плати - заміна класичної BIOS на EFI (Extensible Firmware Interface), який може похвалитися графічним інтерфейсом, швидкої завантаженням, підтримкою дисків більше 2,2 Тбайта.
Плата стандартного формфактора ATX призначена для процесорів Core i3/i5/i7 для роз'єму LGA1155, підтримує установку двох (включаючи двопроцесорні) відеокарт у режимах ATI CrossFire X і NVIDIA SLI, до 32 гігабайт оперативної пам'яті DDR3-2200/2133/1866/1600/1333 / 1066, до шести (чотири внутрішніх і дві зовнішніх) накопичувачів SATA-II (RAID 0,1,5,10) і до чотирьох накопичувачів SATA-III (6 Гбіт / с).
На платі розміщені три слоти PCI Express x16 (x16 + x4 або x8 + x8 + x4), два слоти PCI Express x1, два слоти PCI і чотири слота для двоканальної оперативної пам'яті.
На задню панель плати виведені вісім портів USB 2.0, два порти USB 3.0, порт FireWire IEEE 1394a, два порти Gigabit Ethernet, багатоканальний аналоговий та цифровий оптичний і коаксіальний аудіовиходи, порт PS / 2, антенний модуль Bluetooth, два порти eSATA, один з яких живить, і кнопка для скидання CMOS. Специфікації материнської плати ASUS P8P67 DELUXE можна побачити в таблиці 1.4.
Таблиця 1.4 Специфікації материнської плати ASUS P8P67 DELUXE
| Виробник | ASUS |
| Модель | P8P67 DELUXE |
| Чипсет | Intel P67 Express |
| Процесорний роз'єм | Socket 1155 |
| Підтримувані процесори | Intel Core i7/ Core i5 / Core i3 |
| Використовувана пам'ять | DDR3 1333/1066/1600/1866(O.C.)/2133(O.C.)/2200(O.C.) |
| Підтримка пам'яті | 4 x 240-контактних DIMM двуканальной архітектури до 32 ГБ |
| Слоти розширення | 2 x PCI-E x16 (один x16 чи два x8/x8 ліній) 1 x PCI-E x16 (x4 ліній) 2 x PCI-E x1 2 x PCI |
| Дискова підсистема | Чіпсет Intel P67 підтримує : 2 x SATA 6.0 ГБ/с порту 4 x SATA 3.0 ГБ/с порту з можливістю організації SATA RAID 0, 1, 5, 10; Чіп Marvell 9128 підтримує: 2 x SATA 6.0 ГБ/с порту Чип JMicron JMB362 підтримує: 2 x External SATA 3.0 ГБ/с порту (1 x Power eSATA). |
| LAN | Гігабітний мережевий контролер Realtek RTL8111E Гігабітний мережевий контролер Intel 82579 |
Продовження таблиці 1.4
| Звукова підсистема | Realtek ALC889, 8-канальний High-Definition Audio кодек |
| живлення | 24- контактний роз'єм живлення ATX 8- контактний ATX12V роз'єм живлення |
| охолодження | Алюмінієві радіатори, теплова трубка |
| Роз'єми для вентиляторів | 1 x CPU 4 x корпусних вентилятори |
| Зовнішні порти I / O | 1 x PS/2 (клавіатура / миша) 1 x Clr CMOS кнопка 2 x LAN (RJ45) порт 1 x S/PDIF коаксіальний вихід 1 x S/PDIF оптичний вихід 2 x USB 3.0 8 x USB 2.0 2 x eSATA 1 x IEEE 1394a 8 канальний аудіо вихід |
| Внутрішні порти I / O | 2 x USB 2.0 (до 4 дополнительных) 1 x USB 3.0 (2 дополнительных, 19-pin разъем) 1 x S/PDIF выход 4 x SATA 3.0 Гб/с 4 x SATA 6.0 Гб/с 1 x IEEE 1394a 1 x Power-on кнопка 1 x Reset кнопка Аудіо роз'єм передньої панелі Роз'єм системної панелі |
Продовження таблиці 1.4
| BIOS | 32 Мб ПЗУ EFI AMI BIOS, PnP, DMI2.0, WfM2.0, SM BIOS 2.5, ACPI 2.0a, Multi-language BIOS, ASUS EZ Flash 2, ASUS CrashFree BIOS 3 |
| Фірмові технології | ASUS Dual Intelligent Processors 2 with DIGI+ VRM: ASUS Digital Power Design ASUS BT GO! (Bluetooth) MemOK! AI Suite II AI Charger Anti Surge ASUS EFI BIOS EZ Mode featuring friendly graphics user interface ASUS Q-Design Precision Tweaker 2 SFS (Stepless Frequency Selection) ASUS C.P.R |
| Форм-фактор, розміри, мм | ATX 305 x 244 |
1.4 Модулі пам'яті Kingston HyperX
Модель HyperX PC3-11000 продовжує лінійку продуктів компанії Kingston HyperX, яка представлена на ринку широким спектром рішень як в області DDR3-модулів, так і більш молодших стандартів DDR і DDR2. Виробник позиціонує продукти лінійки HyperX як високопродуктивні, про що свідчать підвищені частоти, прискорені таймінги і збільшена пропускна здатність. Зразок, про який піде мова, є молодшим представником сімейства HyperX DD3 SDRAM. Модулі під артикулом KHX11000D3LLK2/2G поставляються в звичному здвоєному комплекті Memory Kit. Усередині класичної прозорої упаковки містяться два модулі PC3-11000 по 1024 Мбайт кожен. Друкована плата кожного з них несе на собі шістнадцять 512-мегабітних модулів, які охолоджуються за допомогою металевих тепловідвідних пластин, що покривають плату з обох сторін. На синій поверхні тепловідвідних пластин розміщений логотип компанії Kingston, а також опуклий логотип серії HyperX, до якої належить зразок. На тильній стороні модуля є гарантійна наклейка з короткою специфікацією зразка і дублююча пара логотипів. Виходячи зі специфікації модулів, розміщеної на сайті виробника, модулі HyperX PC3-11000 працюють на частоті 1375 МГц при стандартному наборі таймінгів 7-7-7-20-4-48-8-4-4 під напругою 1,7 В.

Рисунок 1.4 Дані SPD модулів пам'яті Kingston HyperX PC3-11000
Комбінація SPD для даних модулів виглядає наступним чином: DDR3 - 1066 МГц, таймінги - 7-7-7, напруга - 1,5 В. Невелика неузгодженість специфікації модулів з даними SPD означає лише одне: інженери компанії попрацювали на славу, вклавши в свій продукт додаткову продуктивність, злегка змінивши комбінацію таймінгів і частоти. Подивимося, як відбилося це зміна на практиці.
2 СПЕЦІАЛЬНИЙ РОЗДІЛ
2.1 Мікроархітектура Sandy Bridge
Нова процесорна мікроархітектура Sandy Bridge побудована на 32 нм техпроцесі, освоєному і обкатаним ще на минулому поколінні - Nehalem (Westmere), наступником якої і є. Структура процесора, по суті, залишилася колишньою - він як і раніше містить ряд обчислювальних ядер, контролер пам'яті, шину PCI Express, DMI та графічне ядро, але тепер все це розміщено в єдиному кристалі, в той час як в Nehalem графічне ядро, контролери пам'яті і шини PCIe, хоч і розташовувалися в корпусі CPU, фізично були реалізовані на окремому кристалі. Однак компонування елементів була значно перероблена. Обчислювальні ядра (Core), кожне з яких оснащене своєї кеш-пам'яттю рівнів L1 і L2 підключені до загальної кільцевої шині розрядністю 256-bit. До неї ж підключені блоки загальною кеш-пам'яті L3, набір системної логіки отримала назву System Agent і включає в себе двоканальний контролер пам'яті (IMC), а так само графічне ядро (IGP). На рисунку 2.1 зображено блоки продуктивності та енергоефективності.

Рисунок 2.1– Блоки продуктивності та енергоефективності
Таким чином, інтегрований графічний процесор тепер не тільки фізично розміщений на одному кристалі з іншими блоками CPU, але і підключений до загальної кеш-пам'яті 3го рівня, що піднімає швидкість обміну з буфером кадру на новий рівень. На рисунку 2.2 зображено кеш останнього рівня.

Рисунок 2.2 Кеш останнього рівня
Крім цього, використання єдиного кристала вирішує і чисто економічні завдання, дозволяючи знизити собівартість виготовлення CPU, що збільшує їх конкурентоспроможність і прибуток від виробництва. Обкатаний на Westmere 32 нм технологічний процес цілком дозволяє випускати хороший відсоток придатних кремнієвих пластин високої складності. До того ж практика виготовлення і подальша упаковка в один корпус двох кристалів, вироблених за різними техпроцесами не тільки менш рентабельна, але і явно незручна в організаційному плані. На рисунку 2.3 зображена повна інтеграція графічного процесора.
Використовувані в складі Sandy Bridge обчислювальні ядра були доопрацьовані і отримали підтримку нових інструкцій для роботи з векторними обчисленнями - Advanced Vector Extensions (AVX) на додаток до існуючих SSE. Причому, в той час як набір інструкцій SSE працював із 128-бітними регістрами, розрядність регістрів AVX становить 256-біт. За запевненням Intel, використання AVX здатне прискорити деякі алгоритми майже на 90%.
Крім цього був значно перероблений блок пророкування розгалужень, збільшені буфери проміжних даних і оновлений блок регістрів.
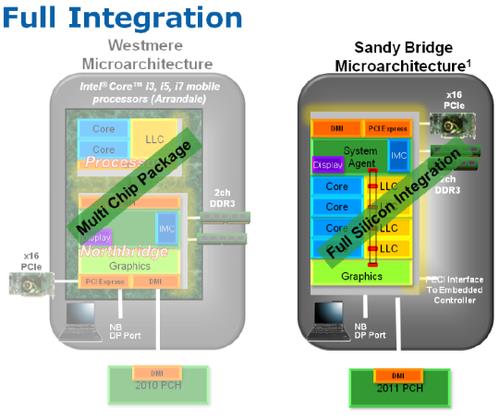
Рисунок 2.3 Схема графічного процесора
Основні представники архітектури Sandy Bridge містять чотири ядра і підтримують технологію Hyper-Threading, завдяки якій процесори можуть виконувати вісім потоків одночасно. Кеш-пам'ять третього рівня (або LLC - last level cache, кеш останнього рівня) тепер працює на частоті процесора, має обсяг у вісім мегабайт і може використовуватися всіма блоками ЦП, які його потребують. Враховуючи велику кількість споживачів і можливе зростання числа ядер в майбутніх процесорах, інженерам Intel довелося відмовитися від звичної топології зв'язку між вузлами і віддати перевагу 256-бітної кільцевої шині, що з'єднує обчислювальні ядра, кеш, графічний процесор і «системний агент». Пропускна здатність такої шини за такт дорівнює добутку кількості процесорних ядер на її ширину. Для чотирьохядерного Sandy Bridge з 8 мегабайтами кеша і частотою 3,0 ГГц вона складе 384 Гбайт в секунду (96 Гбайт / с на одне з'єднання), а для двоядерного - лише 192 Гбайт / с.
2.2 Структура процессорного ядра Sandy Bridge
Если сравнивать строение процессорного ядра Sandy Bridge с самыми первыми представителями микроархитектуры Core, изменения заметны во всём - разница впечатляющая. Если же сравнить ядро Sandy Bridge с его «ближайшим родственником», ядром Nehalem, число действительно серьезных различий будет значительно меньшим.
Тем не менее отличия Sandy Bridge настолько существенны, что они обеспечили увеличение ключевого показателя «производительность/ энергопотребление» в размерах, опережающих традиционный для очередного обновления мікроархітектури линейный прирост. На рисунку 2.4 зображена архітектура ядра Sandy Bridge.

Рисунок 2.4 Архітектура ядра Sandy Bridge
Крім того, процесорна мікроархітектура Sandy Bridge набагато краще попередників відповідає вимогам, що пред'являються додатками до дійсно сучасним системам. Крім збільшеної продуктивності і поліпшених обчислень з плаваючою комою, нова архітектура підтримує розширений набір векторних команд Intel AVX (Advanced Vector Extensions), що важливо для сучасних ресурсномістких додатків; володіє апаратним модулем прискореної обробки інструкцій шифрування AES (Advanced Encryption Standard) і алгоритмів шифрування RSA і SHA; а також містить ряд оптимізацій для більш ефективної віртуалізації і виконання серверних додатків.
2.2.1 Елементи вхідних ланцюгів конвеєра
Блок вибірки команд ядра Sandy Bridge призначений для забезпечення безперебійної вибірки і попереднього декодування інструкцій x86, для подальшого їх декодування в операції мікрокоду. Таким чином, нагадаємо, з інструкцій x86 різної довжини виходить упорядкований потік рівномірних операцій, іменуються в Intel «мікрооперацій» (μops), для наступної обробки зі зміною послідовності (out-of-order).
Процес попереднього декодування увазі формування черги з інструкцій x86 (до шести інструкцій за такт), що завантажуються з кеша L1 в проміжний буфер для подальшої передачі на декодування. Від оперативності роботи декодерів, від їх узгодженості з модулем пророкування розгалужень і «вміння» заповнювати конвеєр прямо залежить безперебійність потоку мікрооперацій, завантаження конвеєра, і в остаточному підсумку продуктивність процесора. На рисунку 2.5 зображений Блок Попереджувальної вибірки команд.

Рисунок 2.5 Блок Попереджувальної вибірки команд
Кеш інструкцій L1 ядра Sandy Bridge розміром 32 Кбайт володіє восьмиканальний (8-way) асоціативністю. Після попереджувальної вибірки і попереднього декодування команди x86 подаються на декодери, які, в свою чергу, видають на виході мікрооперації фіксованої довжини для подальшої обробки зі зміною послідовності (out-of-order). В повній аналогії з ядром Nehalem, три з чотирьох декодерів ядра Sandy Bridge обробляють прості команди, в результаті чого кожен видає по одній мікрооперації на виході, в той час як четвертий декодер обробляє складні інструкції та видає до чотирьох мікрооперацій. Крім того, мікропрограмні інструкції розміром більше чотирьох мікрооперацій розбиваються на блоки по чотири мікрооперації. На рисунку 2.6 зображений Кеш інструкцій L1.

Рисунок 2.6 Кеш інструкцій L1
В повній аналогії з попередніми поколіннями процесорів, блоки декодування Sandy Bridge підтримують як мікро-злиття (Micro Fusion), які об'єднують кілька інструкцій в ряд одиночних мікрооперацій, так і макро-злиття (Macro Fusion), що об'єднують пари інструкцій в одну мікроінструкцій. У будь-якому випадку, декодери Sandy Bridge, як і декодери Nehalem, незалежно від характеру надходять інструкцій видають на виході не більше чотирьох мікрооперацій за такт.
Одним з найбільш важливих нововведень мікроархітектури Sandy Bridge є кеш декодувати мікрооперацій, або кеш інструкцій L0. По суті своїй кеш декодувати мікрооперацій нагадує трассіровочние кеш мікроархітектури NetBurst (Pentium 4), однак принцип роботи у них абсолютно різний, схожість закінчується на тому, що обидва вони працюють з мікрооперацій. На рисунку 2.7 зображений Кеш декодування мікрооперацій.
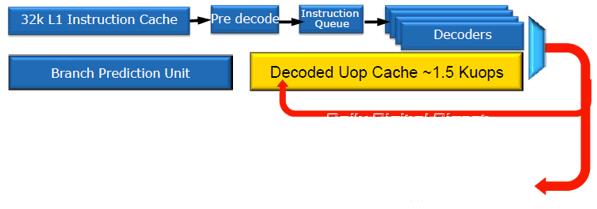
Рисунок 2.7 Кеш декодування мікрооперацій
Завдяки структурної організації формату 32х8 з можливістю зберігання шести мікрооперацій в лінії, кеш декодувати мікрооперацій вміщує трохи більше півтори тисячі мікрооперацій. Без особливих затій він кешує на виході декодерів всі попередньо декодовані мікрооперації. Як тільки надходить на обробку нова інструкція, блок вибірки першою справою виробляє звірку з кешем L0, і в разі виявлення збігів, завантаження конвеєра по чотири мікрооперації за такт в обхід декодерів здійснюється вже з кешу L0. Незадіяні і простоюють ланцюга декодерів, до речі, вельми складні, і тому досить «ненажерливі», в цей момент просто ... відключаються від живлення. В іншому випадку, коли кеш декодувати операцій виявляється незатребуваним, продовжується звичайна робота по вибірці і декодуванню команд, а кеш декодувати операцій переводиться в режим економії енергії.
Кеш L0 в якійсь мірі можна вважати частиною кеша L1, в який він, до речі, інтегрований, але окремої і дуже швидкої його частиною. За словами представників Intel, при роботі з більшістю додатків, ймовірність вдалого «попадання» в кеш декодувати мікрооперацій дуже велика і може досягати 80%.
На рисунку 2.8 зображений Кеш інструкцій L0.

Рисунок 2.8 Кеш інструкцій L0
Анітрохи не менше змінився блок пророкування розгалужень (branch prediction). Зокрема, буфер передбачення результату розгалуження (branch target buffer, BTB) чіпа Sandy Bridge вміщає в два рази більше адрес результатів розгалуження і вдвічі більшу історію комбінацій команд, ніж аналогічний буфер Nehalem. Крім того, збільшено розміри області зберігання історії розгалужень, в тому числі передвіщених і виконаних. Так, вдалося знизити кількість невдалих прогнозів розгалужень, що позитивно відгукнулося як на збільшенні продуктивності за рахунок зменшення часу вимушеного простою для скидання конвеєра з десятками оброблених даремно інструкцій, так і на споживанні енергії, затрачуваної даремно на обробку невдалих розгалужень.
2.2.3 Формування потоку команд зі зміною послідовності
Процеси розподілу, перейменування, планування та виведення даних в процесі конвеєрного виконання макрооперацій в мікроархітектурі Sandy Bridge піддалися самої значній переробці. На рисунку 2.9 зображені макрооперації в мікроархітектурі Sandy Bridge.

Рисунок 2.9 Mакрооперації в мікроархітектурі Sandy Bridge
Реалізація алгоритму виконання інструкцій зі зміною послідовності в попередніх поколіннях процесорів Intel Core, аж до Westmere, базувалася на використанні буфера переупорядочування - ROB (reorder buffer), який в кінцевому підсумку також служить для відновлення послідовності інструкцій. За структурою цей буфер являє собою матрицю із записами всіх виконуваних в даний момент інструкцій, а також гігантський масив віртуальних даних зі значеннями регістрів та інформацією про переміщення між регістрами. На рисунку 2.10 зображений - ROB (reorder buffer).

Рисунок 2.10 ROB (reorder buffer)
Тепер, в мікроархітектурі Sandy Bridge, результати відстеження та перейменування мікрооперацій фіксуються за допомогою фізичного реєстрового файлу, PRF (physical register file), властивого архітектурі NetBurst (Pentium 4) і також характерного для багатьох Out-of-Order архітектур зразок AMD Bulldozer / Bobcat, IBM POWER, але відсутнього в ядрах Nehalem. Фактично, на буфер переупорядочивания в ядрі Sandy Bridge покладена тільки функція «трасування» інструкцій, оброблюваних в даний момент часу, в той час як функції зберігання даних покладені на незалежний фізичний регістровий файла. Іншими словами, факт виконання операції в Out-of-Order структурі Sandy Bridge призводить лише до того, що регістр вказує на інше значення в PRF, а не до перенесення 32 -, 64 -, 128 - або 256-бітових даних, як у випадку, коли використовується тільки буфер переупорядочивания. В таблиці 2.2 приведена ємність компонентів виконавчого Out-of-Order кластера.
Таблиця 2.1 Ємність компонентів виконавчого Out-of-Order кластера
| Ємність компонентів виконавчого Out-of-Order кластера | |||
| Покоління мікроархітектури Intel | Core Merom | Core Nehalem | Core II Sandy Bridge |
| Буфер переупорядочивания - ROB (Re-Order Buffer) | |||
| Фізичний регістровий файл - Physical Register File (PRF), Integer | - | - | |
| Фізичний регістровий файл - Physical Register File (PRF), FP / Vector | - | - | |
| Буфер декодувати, але ще не виконаних команд - Reservation Station (RS) | |||
| Буфери запису - Load Buffers | |||
| Буфери запису - Store Buffers |
Розподіл процесів між двома структурами замість однієї може здатися архітектурним ретроградством, провідним до ускладнення конструкції і додаткового збільшення кількості транзисторів, тобто, до зростання енергоспоживання чипа. Тим не менш в кінцевому підсумку такий поділ функцій значно розвантажує буфер переупорядочивания, постоянно перегруженный в чипах Nehalem и от того постоянно «горячий».
Крім появи в архітектурі Sandy Bridge фізичного реєстрового файлу, змінилися і характеристики традиційних модулів кластера Out-of-Order процесів. Так, буфер переупорядочивания здатний обробляти до 168 мікрооперацій одночасно. Цілочисельний фізичний регістровий файл Sandy Bridge зберігає 160 окремих 64-бітових записів; фізичний регістровий файл для векторно-речових даних з плаваючою комою зберігає 144 56-бітних запису, тобто регістри YMM з новими векторними x86-64 командами AVX цілком.
2.3.4 Виконавчі блоки
Як і раніше, в чипах Nehalem, завантаження мікрооперацій всіх типів: SIMD, цілочисельних і з плаваючою комою, відбувається за однаковим сценарієм, єдиним уніфікованим планувальником, динамічно розподіленим між всіма потоками. Різниця в тому, що в архітектурі Sandy Bridge планувальник більш ємний і завантажується відразу 54 перейменованим і готовими до виконання мікрокомандами. На рисунку 2.11 зображено SIMD.
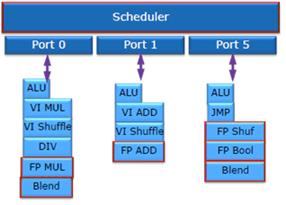
Рисунок 2.11 SIMD
Завдяки суттєвого доопрацювання, націленої на подвоєння продуктивності при роботі з 256-бітними векторними інструкціями AVX і можливості виконання більшості з них як єдиної мікрооперації, виконавчі блоки мікроархітектури Sandy Bridge стали вдвічі потужніша, ніж у чипів Nehalem. Тепер вони здатні обробляти вісім операцій подвійної точності з плаваючою комою (FP) або 16 FP-операцій одинарної точності за такт. Таким чином, як показано на слайді вище, ядро Sandy Bridge здатне виконувати за кожен такт 256-бітове FP-множення, 256-бітове FP-додавання і 256-бітове зсув. На рисунку 2.12 зображено YMM0.

Рисунок 2.12 YMM0
Незважаючи на збільшення розрядності виконавчих блоків ядра до 256 біт, збільшення ширини шини даних до 256 біт не відбулося. Для виконання 256-бітових мікрооперацій в ядрі Sandy Bridge об'єднуються можливості наявних 128-бітних трактів для роботи з даними SIMD INT і SIMD FP. На рисунку 2.13 зображений SIMD INT.

Рисунок 2.13 SIMD INT
На рисунку 2.14 зображений SIMD FP.
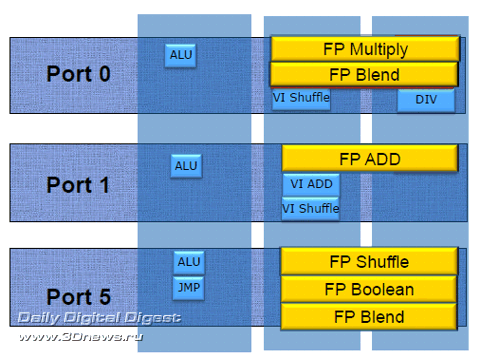
Рисунок 2.14 SIMD FP
Також варто згадати, що в ядрі Sandy Bridge підвищена продуктивність при обробці інструкцій стандарту шифрування AES і RSA, а також продуктивність при обчисленні хешей SHA-1.
2.2.5 Підсистема пам'яті
Необхідність роботи з удвічі збільшеними (до 256 біт) операндами SSE FP не могла не позначитися на навантаженні підсистеми пам'яті ядра Sandy Bridge, яка повинна обслуговувати не менше двох запитів за такт, гарантовано забезпечуючи можливість 16-байт запису і 16-байт читання. На рисунку 2.15 зображений Memory Cluster.

Рисунок 2.15 Пам'ять кластера
Ось чому в структурі 8-банкового кеша даних L1 ядра Sandy Bridge був доданий другий 16-бітний порт читання, завдяки якому сумарна пропускна спроможність кеша виросла до 48 байт за такт: два 16-байт запиту читання і 16-байт запис. Розміри буферів запису і читання, розділених між виконавчими блоками ядра Sandy Bridge, були також збільшені: буфер запису - до 64 осередків, буфер читання - до 36 осередків. На рисунку 2.16 зображений Memory Cluster застосовуемий в архітектурі Sandy Bridge.

Рисунок 2.16 Пам'ять кластера в Sandy Bridge
8-банківський асоціативний кеш L2 мікроархітектури Sandy Bridge, розподілений по 256 Кбайт на кожне ядро, досить схожий з тим, що застосовувалося в попередніх поколіннях процесорів Intel. Тут зміни мінімальні.