|
|
Предикатные синхронизационные блокировки
Несмотря на привлекательность метода гранулированных синхронизационных захватов, следует отметить, что он не решает проблему фантомов (если, конечно, не ограничиться использованием блокировок таблиц в режимах S и X). Давно известно, что для решения этой проблемы необходимо перейти от блокировок индивидуальных («физических») объектов базы данных, к блокировке условий (предикатов), которым удовлетворяют эти объекты. Проблема фантомов не возникает при использовании для блокировок уровня таблиц именно потому, что таблица как логический объект представляет собой неявное условие для входящих в него кортежей. Блокировка таблицы – это простой и частный случай предикатной блокировки.
Поскольку любая операция над реляционной базой данных задается некоторым условием (т.е. в ней указывается не конкретный набор объектов базы данных, над которыми нужно выполнить операцию, а условие, которому должны удовлетворять объекты этого набора), идеальным выбором было бы требовать синхронизационную блокировку в режиме S или X именно этого условия. Но если посмотреть на общий вид условий, допускаемых, например, в языке SQL, то становится абсолютно непонятно, как определить совместимость двух предикатных блокировок. Ясно, что без этого использовать предикатные блокировки для сериализации транзакций невозможно, а в общей форме проблема неразрешима.
Один из компромиссных подходов предлагался участниками проекта System R. Подход основывался на том, что при открытии сканирования таблицы по индексу в RSS передается дополнительная информация (диапазон сканирования), которая ограничивает множество кортежей, среди которых не должны возникать фантомы.
Опираясь на наличие этой информации, предлагалось ввести в систему блокировок System R элементы предикатных блокировок. Заметим сначала, что в System R блокировки сегментов (файлов), таблиц и кортежей технически трактовались единообразно, как блокировки идентификаторов кортежей (tid'ов). При блокировке кортежа на самом деле блокировался его tid. При блокировке сегмента или таблицы на самом деле блокировался tid описателя соответствующего объекта во внутренних таблицах-каталогах сегментов или таблиц.
Предлагалось расширить систему синхронизации, разрешив применять блокировки к паре «идентификатор индекса, интервал значений ключа этого индекса». К такой паре можно было применять блокировки в любом из допустимых режимов, причем две такие блокировки считались совместимыми в том и только в том случае, если они были совместимы в соответствии с приведенной таб. 13.2 или указанные диапазоны значений ключей не пересекались.
При наличии такой возможности, если открывается сканирование таблицы через индекс, то таблица блокируется в режиме IS, и в этом же режиме блокируется пара «идентификатор индекса, диапазон сканирования». При занесении (удалении) кортежа таблица блокируется в режиме IX, и в этом же режиме для каждого индекса, определенного на данной таблице отношении, блокируется пара «идентификатор индекса, значение ключа из затрагиваемого операцией кортежа». Это позволяет избежать конфликтов читающих транзакций с теми изменяющими транзакциями, которые затрагивают диапазоны сканирования читающих транзакций. При этом решается проблема фантомов, и параллельность транзакций ограничивается «по существу», т.е. только в тех случаях, когда их параллельное выполнение создает проблемы.
Заметим сразу, что описанное решение проблемы фантомов далеко от идеального. Во-первых, по-прежнему при сканировании таблиц без использования индексов отсутствие фантомов можно гарантировать только при блокировке всего отношения в режиме S. Во-вторых, даже при сканировании по индексу условие реальной выборки кортежа часто может быть гораздо строже простого указания диапазона сканирования, а это значит, что блокировка этого диапазона будет слишком сильной, т.е. затронет более широкое множество кортежей, чем то, которое будет реальным результатом сканирования.
Известно следующее более совершенное решение. Будем называть простым условием конъюнкцию простых предикатов сравнения, имеющих вид имя_поля { = > < } значение. В типичных СУБД, поддерживающих двухуровневую организацию (языковой уровень и уровень управления внешней памяти), в интерфейсе подсистемы управления памятью (которая обычно заведует и сериализацией транзакций) допускаются только простые условия. Подсистема языкового уровня производит компиляцию оператора SQL со сложным условием в последовательность обращений к подсистеме управления памятью, в каждом из которых содержатся только простые условия.
Более точно, простое условие явно указывается в операции открытия сканирования таблицы (напрямую или через индекс; в последнем случае оно конъюнктивно соединяется с условием, задаваемым диапазоном сканирования). Кроме того, при открытии сканирования всегда можно указать, для какой цели оно будет использоваться: для выборки кортежей, для их удаления или для их обновления (это известно компилятору SQL). Кроме того, неявные условия задаются операциями вставки и удаления кортежей (конъюнктивное логическое выражение, состоящее из простых предикатов вида имя_поля = значение для всех полей таблицы), а также операциями обновления кортежей (конъюнктивное логическое выражение, состоящее из простых предикатов вида имя_поля = значение для всех обновляемых полей таблицы). Поэтому в случае типовой организации SQL-ориентированной СУБД простые условия можно использовать как основу предикатных захватов.
Для простых условий совместимость предикатных блокировок легко определяется на основе следующей геометрической интерпретации. Пусть Tab – таблица с полями a1, a2, ..., an, а m1, m2, ..., mn – множества допустимых значений a1, a2, ..., an соответственно (естественно, все эти множества – конечные). Тогда можно сопоставить Tab конечное n-мерное пространство возможных значений кортежей Tab. Легко видеть, что любое простое условие, представляющее собой конъюнкцию простых предикатов, «вырезает» в этом пространстве k-мерный прямоугольник (k ≤ n).
Достаточно очевидно следующее утверждение:
Пусть имеются два простых условия scond1 и scond2. Пусть транзакция T1 запрашивает блокировку scond1, а транзакция T2 – scond2 в режимах, которые были бы несовместимы, если бы scond1 и scond2 являлись не условиями, а объектами базы данных (S-X, X-S, X-X). Эти блокировки совместимы в том и только в том случае, когда прямоугольники, соответствующие scond1 и scond2, не пересекаются.
Это утверждение действительно очевидно (каждому k-мерному прямоугольнику в n-мерном пространстве возможных значений кортежей Tab соответствует некоторое подмножество возможных значений кортежей, и отсутствие пересечения у двух прямоугольников гарантирует отсутствие конфликтов транзакций), но для наглядности на рис. 13.5 приводится иллюстрирующий пример, показывающий, что в каких бы режимах не требовала транзакция T1 блокировки условия (0 < a < 5) & (b = 5), а транзакция T2 – блокировки условия (0 < a <6) & (0 < b <4), эти блокировки всегда будут совместимы.
Интересно, что при поддержке такой системы блокировок простых условий можно обойтись без гранулированных блокировок. В частности, чтобы гарантированно заблокировать таблицу целиком, достаточно заблокировать условие &1  i n (min(mi) < имя_поляi < max(mi)). Чтобы заблокировать базу данных, достаточно заблокировать условие, являющееся конъюнкцией условий блокировки всех таблиц этой базы данных.
i n (min(mi) < имя_поляi < max(mi)). Чтобы заблокировать базу данных, достаточно заблокировать условие, являющееся конъюнкцией условий блокировки всех таблиц этой базы данных.
Заметим, что блокировки простых условий описываются таблицами, немногим отличающимися от таблиц традиционных синхронизаторов с гранулированными блокировками. Поэтому введение в СУБД механизма предикатных блокировок не приводит к значительным усложнениям.
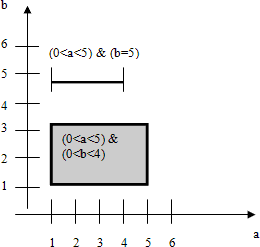
Рис. 13.5. Простые условия, блокировки которых совместимы