|
|
Восстановление базы данных после жесткого сбоя
Понятно, что для восстановления последнего согласованного состояния базы данных после жесткого сбоя журнала изменений базы данных явно недостаточно. Самый простой способ восстановления основывается на использовании логического журнала и архивной копии базы данных.
Восстановление начинается с обратного копирования (на исправный носитель) базы данных из архивной копии. Затем для всех закончившихся транзакций выполняется redo, т.е. операции повторно выполняются в прямом смысле.
Более точно, происходит следующее:
- по журналу в прямом направлении выполняются все операции;
- для транзакций, которые не закончились к моменту сбоя, выполняется откат.
Очевидно, что после этого будет получено хронологически последнее до момента жесткого сбоя логически согласованное состояние базы данных.
Следует заметить, что при некоторой дисциплине выполнения логических операций над базой данных при восстановлении базы данных после жесткого сбоя можно просто последовательно повторно выполнять операции в соответствии с журнальными записями, не обращая внимание на то, в каких транзакциях они выполнялись до жесткого сбоя. В частности, если сериализация транзакций основывается на блокировках объектов, то эта дисциплина заключается в том, что при выполнении операции в штатном режиме нужно сначала дождаться удовлетворения блокировки изменяемого объекта, затем поместить запись в буфер логического журнала, и только после этого реально выполнять операцию.
На самом деле, поскольку жесткий сбой не сопровождается утратой буферов оперативной памяти, можно восстановить базу данных до такого уровня, чтобы можно было продолжить даже выполнение незавершенных транзакций. Но обычно это не делается, потому что восстановление после жесткого сбоя – это достаточно длительный процесс.
Хотя к ведению журнала предъявляются особые требования по части надежности, в принципе возможна и его утрата. Тогда единственным способом восстановления базы данных является возврат к архивной копии. Конечно, в этом случае не удастся получить последнее согласованное состояние базы данных, но это лучше, чем ничего.
Последний вопрос, который здесь следует еще раз обсудить, касается производства архивных копий базы данных и/или журнала. Самый простой способ состоит в архивировании базы данных по явному указанию администратора или при переполнении журнала. Но можно выполнять архивацию базы данных реже, чем переполняется журнал. Вместо базы данных можно архивировать сам журнал. В пределе для полного восстановления базы данных после жесткого сбоя достаточно иметь исходную архивную копию базы данных, последовательность архивных копий журналов и последний логический журнал. Может показаться, что восстановление базы данных на основе таких архивных источников будет занимать недопустимо большое время, однако здесь возможна значительная оптимизация.
Во-первых, архивированный логический журнал можно сжимать. Для этого для каждого объекта базы данных нужно найти последовательность журнальных записей, относящихся к этому объекту, в хронологическом порядке и заменить их одной записью, соответствующей операции над объектом, результат которой эквивалентен результату последовательного выполнения журнализованных операций из построенной последовательности. Например, на рис. 14.4 показан процесс сжатия последовательности журнальных записей, соответствующих последовательности операций над кортежем, у которого tid = k и имеются четыре целочисленных поля. Заметим, что если хронологически последней в последовательности является запись, соответствующая операции DELETE, то после сжатия этой последовательности она станет пустой.
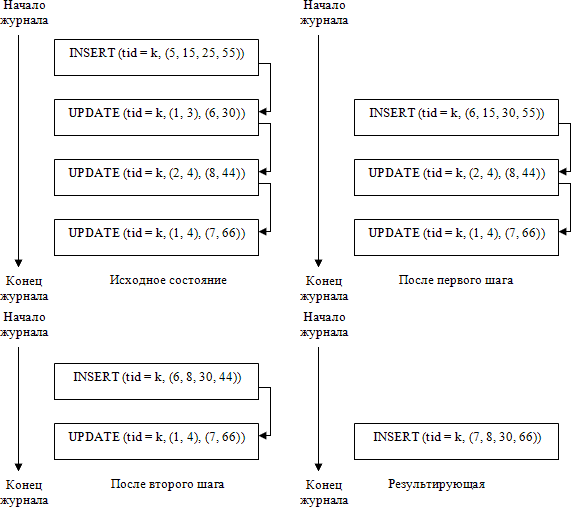
Рис. 14.4. Процесс сжатия последовательности журнальных записей
Во-вторых, точно таким же образом можно совместно сжать два хронологически последовательных полных или сжатых журнала. Таким образом, для восстановления после жесткого сбоя можно воспользоваться исходной архивной копией, одним сжатым архивным журналом и последним логическим журналом. Снова могут возникнуть сомнения относительно сложности и продолжительности процесса сжатия журнала. Но здесь следует заметить, что эта работа может выполняться на отдельном компьютере в режиме off-line. Кроме того, если имеется архивная копия базы данных, сжатый архивный журнал и набор еще не сжатых архивных журналов, то этого уже достаточно для восстановления, так что сроки завершения процесса полного сжатия не являются критическими.
Заключение
В этой лекции рассматривались основные принципы и алгоритмы подсистем СУБД, предназначенных для управления буферами основной памяти, журнализации и восстановления базы данных после различных сбоев. Изложение велось без технических деталей, таких как возможные структуры данных журналов.
Заметим, что во многих современных производственных СУБД журнализация и восстановление основаны на применении семейства алгоритмов ARIES, разработанных в 1980-е гг. известным исследователем из компании IBM К. Моханом (C. Mohan). В этой лекции не приводится описание алгоритмов семейства ARIES, поскольку, по мнению автора, это перегрузило бы ее подробностями, не способствующими пониманию основных идей. Тем не менее, читателям, которых заинтересовала эта тема, полезно познакомится с этими алгоритмами, для чего можно воспользоваться, например, [3.16] или оригинальными статьями Мохана и его коллег.