|
|
Методи безпосередньої компресії
Компресією мовних сигналів називається зменшення обсягу сигналів за рахунок стиснення одного чи декількох параметрів сигналу (динамічний діапазон, спектр частот, тривалість). Ці методи відрізняються тим, що виробляються тільки деформації обсягу сигналу, а мікроструктура сигналу цілком не знищується. Під час деформації об’єму сигнал частково викривляється, однак ці викривлення відіграють роль завад. Тут сигнал у відповідному вимірі “деформується”, тобто стискається на передавальному кінці з відповідним розширенням його на приймальному кінці.
Отже, після обмеження сигналу по динамічному, частотному діапазону чи в часі відновити сигнал цілком на приймальному кінці не вдається.
Розгляд методів безпосередньої компресії почнемо з амплітудної компресії. У динамічному діапазоні сигналу міститься переважно інформація про якість звучання й у значно меншому ступені – інформація про розбірливість звуків, тобто компресований за рівнем мовний сигнал має розбірливість, що мало відрізняється від вихідного сигналу. Таким чином, компресія дозволяє підвищувати завадостійкість передачі.
Стиснення динамічного діапазону мови виробляється або методом автоматичного регулювання фонетичного рівня мови, або миттєвою компресією сигналу. При першому способі стиснення рівні звуків мови так чи інакше зближаються один з одним. У результаті піковий і мінімальний рівні компресованої мови також зближаються. Перехідні процеси, що залежать від сталої часу компресуючого пристрою, дуже спотворюють деякі звуки мови (б, п, д, т). В цілому динамічне компандування мови, крім корисного ефекту, має недолік – поява викривлень через наявність перехідних процесів. Корисна дія компандування виявляється в тому, що при заданій піковій потужності передавача, незважаючи на викривлення, розбірливість мови підвищується навіть при наявності завад. У цьому випадку максимальний рівень мови на виході компресора буде таким же, як і на вході, а більш низькі рівні будуть піднятими.
Внаслідок “підтягування” слабких складових мови збільшується її розбірливість на тлі завад. Крім того, стиснення динамічного діапазону при заданій піковій потужності генератора забезпечує краще використання вихідних каскадів. Більш ефективним є спосіб стиснення динамічного діапазону шляхом миттєвої компресії (амплітудного обмеження). Цей спосіб є без інерційним. Розрізняють обмеження по максимуму (рис.2.9, а, в) і по мінімуму (рис.2.9, б, г).
Під ступенем обмеження зверху розуміють величину  , а при обмеженні знизу –
, а при обмеженні знизу –  , де
, де  – максимальне значення напруги на вході обмежувача;
– максимальне значення напруги на вході обмежувача;  – напруга початку обмеження.
– напруга початку обмеження.
Вплив обмеження знизу і зверху на розбірливість мови різний (рис. 2.10). Незначне обмеження знизу викликає істотне зниження розбірливості мови, а навіть при сильному обмеженні зверху розбірливість мови неістотно падає. Встановлено, що висока розбірливість мови зберігається навіть при граничному обмеженні, що називається кліпуванням. Кліпована мова має вигляд прямокутних імпульсів різної тривалості (рис. 2.11). При цьому єдиною інформацією про первісну мову є послідовність нульових переходів. Виходячи з високої розбірливості процесу кліпування, випливає, що ті чи інші властивості розташування нулів (рис. 2.11) містять велику кількість інформації про мовне повідомлення.
Ще краща розбірливість, якщо мову попередньо диференціюють, а потім обмежують похідну мовного процесу. У цьому випадку зберігається положення не нульових, а екстремальних значень мовного повідомлення. Більш висока розбірливість мови для цього випадку пояснюється тим, що число екстремальних значень у мовному повідомленні більше числа нульових значень. Експериментально встановлено, що для чоловічих голосів нульові значення випливають з частотою 2780 Гц, а екстремальні – з частотою 4700 Гц. Таким чином, при збереженні положень екстремальних значень за допомогою диференціювання зберігається і передається в лінію зв’язку більш повна інформація про структуру сигналу.

Рис. 2.9. Епюри напруг, що пояснюють принцип обмеження по максимуму і мінімуму
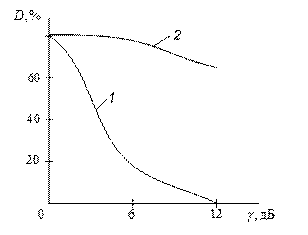
Рис. 2.10. Вплив на розбірливість обмеження зверху (2), і знизу (1)

Рис. 2.11. Осцилограма кліпованої мови
Мовний сигнал у разі дотримання деяких умов може бути записаний як
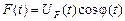 .
.
При цьому функції  і
і  визначені у такий спосіб:
визначені у такий спосіб:
 ;
;  ,
,
де вихідна функція  і сполучена функція
і сполучена функція  однозначно пов’язані між собою інтегральними перетвореннями Гільберта:
однозначно пов’язані між собою інтегральними перетвореннями Гільберта:
 ;
;  .
.
Визначені таким способом функції і являють собою на комплексній площині функцію 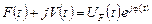 , що називається аналітичною формою сигналу, утвореного з функції .
, що називається аналітичною формою сигналу, утвореного з функції .
Сигнал є дійсною частиною аналітичного виразу  .
.
Вхідні у виразі (2.7) функції 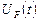 і
і  являють собою огинаючу і фазу сигналу і містять відповідно амплітудну і частотну інформації. Очевидно, що похідна миттєвої фази
являють собою огинаючу і фазу сигналу і містять відповідно амплітудну і частотну інформації. Очевидно, що похідна миттєвої фази  є миттєва частота сигналу .
є миттєва частота сигналу .
Кліпування мови зводиться до усунення амплітудної інформації і до виділення та передачі частотної інформації, що міститься у функції 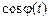 , тобто в передачі мови постійного рівня. Виділення частотної інформації не можна здійснювати шляхом безмежного стискання, тому що спектри
, тобто в передачі мови постійного рівня. Виділення частотної інформації не можна здійснювати шляхом безмежного стискання, тому що спектри  і
і  перекриваються, а ширина спектра перевершує октаву. У такому випадку частина гармонік, що виникли в результаті сильного обмеження, потрапить у вхідний діапазон частот і буде засмічувати обмежений сигнал на виході. Один зі способів усунення зазначеного недоліку полягає в зменшенні продуктів нелінійного викривлення шляхом попередньої корекції частотної характеристики мови до обмеження.
перекриваються, а ширина спектра перевершує октаву. У такому випадку частина гармонік, що виникли в результаті сильного обмеження, потрапить у вхідний діапазон частот і буде засмічувати обмежений сигнал на виході. Один зі способів усунення зазначеного недоліку полягає в зменшенні продуктів нелінійного викривлення шляхом попередньої корекції частотної характеристики мови до обмеження.
При стисненні динамічного діапазону сигналу найбільш обмежуються низькочастотні складові спектра, що мають найбільшу частку енергії мови, в результаті чого утворюються інтенсивні гармоніки, що не виходять за межі спектра мови, і тому спотворюють її. Крім того, в обмежувачі має місце безпосереднє придушення високочастотних складових низькочастотними. Якщо перед обмежувачем підняти високочастотні складові мови, то воно буде більш рівномірним, і зазначені викривлення зменшаться. Таке піднімання частотної характеристики може бути отримано під час проходження мовного сигналу через ланку, що диференціює. Це також є причиною підвищення розбірливості попередньо диференційованої обмеженої мови. Ще більш ефективним способом зменшення продуктів нелінійних викривлень є перенесення обмеження в область високих частот. Так, якщо
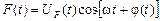 ,
,
то частоту  можна вибрати настільки великою, що спектри функцій і
можна вибрати настільки великою, що спектри функцій і  не будуть перекриватися, тобто порівняно з буде змінюватися повільно. Крім того, можна домогтися, щоб ширина спектра сигналу, зміщеного на частоту , була меншою порівняно зі значенням
не будуть перекриватися, тобто порівняно з буде змінюватися повільно. Крім того, можна домогтися, щоб ширина спектра сигналу, зміщеного на частоту , була меншою порівняно зі значенням  , тобто вже октави.
, тобто вже октави.
Таким чином, гармоніки, що виникають при обмеженнях, виявляються поза межами діапазону частот функції і тому можуть бути відфільтровані на виході обмежувача.
У результаті замість сигналу прямокутної форми процес на виході фільтра буде мати вигляд частотно-модульованого коливання.
Отже, оптимальний ступінь обмеження залежить від виду модуляції, від заходів, прийнятих для боротьби з нелінійними викривленнями, а також від умов, за яких здійснюється передача мовних повідомлень. Так, під час передачі з тиші оптимальним є обмеження на 18...24 дБ щодо пікового рівня мови. Таке обмеження прийнятне доти, поки відношення шум/сигнал менше одиниці. У разі більш інтенсивних завад розбірливість обмеженого сигналу різко знижується. Розбірливість необмеженого сигналу за таких умов знижується менш різко, однак вона буде також незадовільною. У разі ступеня обмеження 40 дБ розбірливість обмеженого сигналу при будь-якому рівні завад буде нижче розбірливості необмеженого сигналу.
За умов роботи з високим рівнем шуму  за рахунок мимовільного збільшення рівня мови оператором на 6...8 дБ ступінь обмеження можна вибирати в межах 18...24 дБ. Слід зазначити, що передача обмеженої мови пов’язана з необхідністю великого підсилення в низькочастотному тракті передавального пристрою. Це призводить до відносного зростання шумів у паузах, що погіршує якість звучання, і є істотним недоліком систем зв’язку, що використовують граничну компресію динамічного діапазону.
за рахунок мимовільного збільшення рівня мови оператором на 6...8 дБ ступінь обмеження можна вибирати в межах 18...24 дБ. Слід зазначити, що передача обмеженої мови пов’язана з необхідністю великого підсилення в низькочастотному тракті передавального пристрою. Це призводить до відносного зростання шумів у паузах, що погіршує якість звучання, і є істотним недоліком систем зв’язку, що використовують граничну компресію динамічного діапазону.
Одним зі способів зменшення шумів у паузах є запирання мовного тракту за допомогою обмежувача по мінімуму. Однак у цьому випадку погіршується якість відтворення внаслідок пропадання коротких вибухових звуків, особливо на початку слів. Високу розбірливість і гарну якість звучання мови можна одержати шляхом передачі по рівнобіжних каналах кліпованого сигналу і його огинаючої з наступним перемножуванням на приймальному кінці. Порівнюючи між собою перший і другий способи стиснення динамічного діапазону, бачимо, що при другому способі відбувається більше звуження динамічного діапазону, однак нелінійні викривлення при цьому більш значні. Пристрої, що реалізують цей спосіб, дуже прості, тоді як пристрої автоматичного регулювання рівня досить складні, нестійкі в роботі і вносять помітні викривлення внаслідок процесів, що відбуваються в них.
Існує третій спосіб стиснення динамічного діапазону, що називається амплітудною селекцією. Сутність його полягає в передачі тільки максимальних і мінімальних значень мовного сигналу. Амплітудна селекція, маючи всі достоїнства кліпованої мови, має перевагу перед нею, тому що потребує смугу передачі в 2,5 рази вужчу.
Розглянемо основні методи частотної компресії. Спектр мови займає смугу частот 100...9000 Гц. Найпростіший і найбільш поширений спосіб частотної компресії полягає в обмеженні спектра мовних сигналів, переданих по лінії зв’язку. Для передачі вибирається ділянка спектра, що є найбільш важливою для забезпечення необхідної якості зв’язку. Високочастотні складові мови понад 3...5 кГц несуттєво впливають на її розбірливість, тому з метою звуження спектра телефонного каналу і зниження внаслідок цього рівня завад ці складові доцільно обрізати. Це також доцільно і для низькочастотних складових нижче 250...300 Гц, що мають досить високу інтенсивність, однак мало впливають на розбірливість мови. Результати досліджень показали, що під час телефонної передачі мови, особливо за умов флуктуаційних шумів з рівномірною щільністю по частоті, обмеження частотного діапазону зверху частотою 3500 Гц і знизу частотою 300 Гц призводить лише до підвищення розбірливості мови.
Компресія спектра телефонного сигналу може бути отримана також за рахунок збільшення часу передачі. Якщо мову спочатку записати на плівку і зменшувати частоту обертання магнітофона проти нормальної в n разів, то у таке ж число разів звузиться спектр мови. На приймальній стороні для відновлення нормальної мови частота обертання повинна бути збільшена в n разів. Хоча розглянуті вище методи безпосередньої частотної компресії мають практичне значення, стиснення спектра мови в цьому випадку невелике і дуже далеке від гранично можливого стиснення.
Теоретична межа можливого стиснення спектра телефонного сигналу може бути встановлена на основі формули Шеннона [1]:
 ,
,
де F – ширина спектра сигналу;  – відношення потужності сигналу до потужності функціональної завади.
– відношення потужності сигналу до потужності функціональної завади.
Нормальна розмова ведеться зі швидкістю  фонем/с. У разі ідеального кодування кількість двоїчних одиниць, необхідних для передачі кожної букви, близька до ентропії повідомлення, тобто
фонем/с. У разі ідеального кодування кількість двоїчних одиниць, необхідних для передачі кожної букви, близька до ентропії повідомлення, тобто  біт/фонем. Тоді швидкість передачі при розмові
біт/фонем. Тоді швидкість передачі при розмові  біт/с. Якщо взяти відношення сигналу до завади в каналі зв’язку рівним
біт/с. Якщо взяти відношення сигналу до завади в каналі зв’язку рівним  , тобто
, тобто  , що необхідно для системи зв’язку з амплітудною модуляцією (АМ), то необхідна смуга частот визначиться з умови
, що необхідно для системи зв’язку з амплітудною модуляцією (АМ), то необхідна смуга частот визначиться з умови
 .
.
Якщо біт/фонем, то  Гц, а при
Гц, а при  біт/фонем
біт/фонем  Гц. Системи телефонного радіозв’язку з безпосередньою компресією, які застосовуються на практиці, займають значно більшу смугу частот.
Гц. Системи телефонного радіозв’язку з безпосередньою компресією, які застосовуються на практиці, займають значно більшу смугу частот.
Існує також метод тимчасової компресії телефонного сигналу, що полягає в збереженні часу передачі і заснований на надмірності мови, обумовленої її тимчасовими характеристиками. Зазначена надмірність характеризується наявністю повторюваних ділянок у тимчасовій функції. Так, при розгляді спектрограм голосних звуків помітні повторювані ділянки, що випливають одна за одною з частотою основного тону. Наявність основного тону в мові може бути визначена за її осцилограмою (див. рис.2.2). Осцилограма являє собою серію згасаючих коливань. Інтервал між сусідніми коливальними процесами дорівнює періоду основного тону. Статистика показує, що основний тон чоловічих голосів знаходиться в межах від 70...120 до 150...160 Гц із середньою частотою 120 Гц, для жіночих голосів в межах від 180...220 до 300...330 Гц із середньою частотою 240 Гц.
Враховуючи, що більшість дзвінких звуків має тривалість 50...300 мс, процес коливань можна вважати до середини звуку цілком сталим і тому говорять про частоту тимчасової огинаючої процесу коливань, вимірюваної системами з невеликою сталою часу (не більше 1/50 с). При цьому розрізняють два основних аспекти основного тону: мелодію, що представляє собою зміну миттєвої частоти тону, та інтегральний розподіл миттєвої частоти тону. Можна сформулювати три основні особливості характеристик основного тону.
Першою особливістю є те, що основний тон голосу є майже періодичним процесом і, отже, має спектр, що складається з ряду груп складових. У кожній групі є складові, які розташовані на частотних інтервалах, близьких до інтервалів між гармоніками основного тону при тривалому його звучанні. Таке представлення про особливості основного тону не завжди правомірно, тому що тільки для деяких тривалих звуків можна говорити про встановлення процесу. У більшості ж випадків тривалість звучання основного тону невелика. Вважають, що якщо різниця в інтервалах не виходить за межі 10...15 %, то основний тон незмінний. Однак слух розрізняє таку зміну основного тону як характерну рису, за якою можна впізнати голос.
Другою особливістю основного тону є зміна в значних межах тривалості інтервалів під час вимови окремих фраз, а також наявність у багатьох людей різного основного тону для вимови тих чи інших фраз. Перше явище називається мелодією основного тону. Вона характерна, наприклад, для питальних і окличних речень. За цією особливістю можна впізнати голос людини, що говорить.
Третьою особливістю основного тону є швидка зміна його інтервалів, особливо при переходах від голосного до приголосного, і навпаки. Якщо ввести поняття швидкості зміни основного тону, то виявляється, що вона доходить до 6000 Гц/с.
Розглянуті вище характеристики основного тону допомагають краще зрозуміти процес тимчасової компресії мовного сигналу. На відміну від спектрограми голосних звуків багато приголосних звуків за своїми властивостями наближаються до шумів, а, отже, не мають періодичності. Однак і в цьому випадку деякі параметри коливання на невеликому відрізку часу залишаються постійними.
Для розпізнавання звуків необов’язково передавати їх протягом всього інтервалу часу мовного повідомлення. Щоб зрозуміти звук мови, потрібно інтервал часу близько 10 мс. Отже, скорочення часу передачі можливо шляхом усунення тимчасової надмірності. Дослідження показують, що можна скоротити половину чи навіть більше половини загальної тривалості передачі при збереженні досить високої розбірливості.
В роботі запропонований метод тимчасової компресії мови, синхронної з частотою основного тону. Тут із сигналу, що надходить, виділяється частота основного тону і замикає канал передачі сигналу в момент найбільш слабких коливань на час, рівний трьом періодам основного тону, після чого канал відкривається на один період основного тону і т. ін.
На приймальному кінці є лінія затримки з паралельними послідовними ланками, керована імпульсами основного тону. Сумарний сигнал від відповідних ланок лінії затримки представляє безупинний сигнал.
2.4. Статистичні характеристики мовних повідомлень
Дослідження статистичних характеристик мовного сигналу базується на математичному представленні акустичного процесу утворення мови, який, у свою чергу, базується на фізичних процесах утворення мови. Розглянемо дискретну модель утворення мови (рис 2.12).
В цій моделі можна виділити дві системи, модель збудження і модель випромінювання. Більшість звуків мови можна віднести або до вокалізованих (голосних), або до невокалізованих (приголосних). У випадку вокалізованих звуків джерело збудження повинно формувати квазіперіодичну послідовність імпульсів. У випадку невокалізованих – випадкові шумові коливання [2].
Структурна схема пристрою, який реалізує один із способів одержання такого сигналу, показана на рис.2.12. Вона складається з генератора імпульсної послідовності (ГІП) з періодом слідування імпульсів  , який дорівнює періоду основного тону
, який дорівнює періоду основного тону  мовного сигналу. З виходу ГІП сигнал надходить на лінійну інерційну систему імпульсна характеристика
мовного сигналу. З виходу ГІП сигнал надходить на лінійну інерційну систему імпульсна характеристика  якої відповідає формі коливань в голосовій щілині. Коефіцієнт підсилення вокалізованого звуку
якої відповідає формі коливань в голосовій щілині. Коефіцієнт підсилення вокалізованого звуку  визначає інтенсивність голосового збудження.
визначає інтенсивність голосового збудження.
Для невокалізованих звуків модель збудження реалізується у вигляді генератора шуму (ГШ) з коефіцієнтом підсилення  , який регулюється. Так, у дискретному часі замість ГШ може бути використано генератор випадкових чисел, який формує послідовність із рівномірним спектром та довільною функцією розподілу.
, який регулюється. Так, у дискретному часі замість ГШ може бути використано генератор випадкових чисел, який формує послідовність із рівномірним спектром та довільною функцією розподілу.

Рис.2.12. Дискретна модель утворення мови
Модель голосового тракту цілком характеризується передавальною функцією 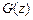 , полюси якої відповідають резонансам (формантам) мовного сигналу. Полюсна модель дає у більшості випадків хороше зображення голосового тракту для більшості звуків мови. Для розширення можливостей описаних звуків необхідно використовувати не тільки резонанси, а й антирезонанси, тобто враховувати не тільки полюси, але й нулі функції , що в деяких випадках і робиться.
, полюси якої відповідають резонансам (формантам) мовного сигналу. Полюсна модель дає у більшості випадків хороше зображення голосового тракту для більшості звуків мови. Для розширення можливостей описаних звуків необхідно використовувати не тільки резонанси, а й антирезонанси, тобто враховувати не тільки полюси, але й нулі функції , що в деяких випадках і робиться.
Передавальну функцію можна реалізувати як аналоговими, так і цифровими пристроями.
Ефект випромінювання мови можна описати за допомогою передавальної функції  . Звичайно, моделі голосового тракту об’єднують разом. При цьому результуючу передатну функцію процесу утворення мови записують у вигляді
. Звичайно, моделі голосового тракту об’єднують разом. При цьому результуючу передатну функцію процесу утворення мови записують у вигляді
 .
.
Для управління такою моделлю повинна бути апріорна інформація про залежність відповідних параметрів (частоти основного тону, положення перемикача гучності та коефіцієнти передачі фільтрів) від часу.
Для вокалізованих звуків, які повільно змінюються у часі, ця модель виявляється найбільш точною. Для невокалізованих звуків, які швидко змінюються, розглянута модель утворення мови може не відповідати реальним фізичним процесам.
У будь-якому випадку припускається, що мовний процес, який є випадковим нестаціонарним процесом, повинен бути підданий короткочасному аналізу. Найчастіше вважають, що параметри моделі незмінні протягом 10...20 мс.
Під час синтезу та аналізу систем передачі мови використовують різні абстрактні моделі мовного процесу, що в якійсь мірі відповідають реальній дійсності. Найбільш поширена модель являє собою нестаціонарний гауссівський випадковий процес з дисперсією та спектральною щільністю, що повільно змінюються. У разі використання такої моделі можна синтезувати систему зв’язку з найкращими характеристиками. Але при цьому виходить досить складна система, яка сама настроюється, синтез її досить складний, тому що відсутні численні статистичні характеристики таких моделей мовного процесу.
Меншу точність має модель мовного сигналу, який являє собою нестаціонарний гауссівський процес з повільно змінюваною дисперсією та постійною усередненою спектральною щільністю, яка визначається експериментально з використанням усереднення за часом.
Разом з тим, для реальних мовних процесів на досить великих відрізках часу задовольняються умови стаціонарності, що дає можливість розглядати мовний сигнал як квазістаціонарний.
Для оцінки якості передачі мовного сигналу в цифрових системах передачі інформації широко використовуються різні апроксимації усередненої за часом щільності розподілу вірогідності розподілу мови (ЩВР)  .
.
Найбільш зручною вважається така модель апроксимації ЩВР:
 ,
,
де  ;
; 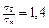 .
.
Вважається, що вірогідності голосних  та приголосних
та приголосних  звуків однакові та дорівнюють 0,5.
звуків однакові та дорівнюють 0,5.
Поряд з ЩВР важливе прикладне значення для аналізу систем передачі мови мають спектральні  та кореляційні
та кореляційні  характеристики.
характеристики.
Найбільш поширена модель мовного процесу, який пройшов попереднє обмеження спектра за допомогою фільтра нижніх частот з частотою зрізу  . Спектральна щільність потужності мовного процесу на виході такого фільтра визначається за співвідношенням:
. Спектральна щільність потужності мовного процесу на виході такого фільтра визначається за співвідношенням:
 ;
;
 ; (2.5)
; (2.5)
 ;
;  ;
;  . (2.6)
. (2.6)
Для аналізу пристроїв перетворення мови, наприклад у вокодерах, використовують апроксимацію у вигляді
 ;
; 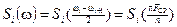 .
.
Взагалі мовні випадкові процеси не є суттєво гауссівськими випадковими процесами.
2.5. Параметрична компресія мовних сигналів
Загальні положення
Методи компресії телефонних сигналів з функціональним перетворенням мови (параметрична компресія) ґрунтуються на заміні мови її параметрами, відомості про які передаються в лінію зв’язку для відновлення повідомлення в приймальному пристрої. Найчастіше вибирають параметри, які повільно змінюються в часі, тому для передачі інформації про такі параметри треба використовувати смугу частот, вужчу ніж для передачі самої мови [8].
Пристрої для функціонального перетворення мови називають вокодерами (від англ. voice – голос та coder – кодувальник).
Робота вокодерів ґрунтується на моделюванні людської мови з урахуванням її характерних особливостей. Замість безпосереднього вимірювання амплітуди вокодер перетворює вхідний сигнал в деякий інший, схожий на первинний. При цьому характеристики мовного сигналу використовують для коригування параметрів прийнятої моделі мовного сигналу. Саме ці параметри і передаються приймачу, який за ними відновлює первинний мовний сигнал. По суті йдеться про синтез мови. У цьому випадку випромінювання спотворень відношення сигнал/шум не має сенсу для вокодерів, а тому необхідні інші суб’єктивні оцінки, такі як середня експертна оцінка, діагностичний римований текст та інші оцінки.
Вокодери можна розділити на два класи: мовноелементні та параметричні. У мовноелементних вокодерах під час передачі розпізнаються елементи мови (наприклад фонеми) і передаються тільки їх номери. На приймальному кінці ці елементи створюють за правилами мовоутворення або беруть із пам’яті пристрою. Галузь застосування фонемних вокодерів – лінії командного зв’язку, мовне керування та інформаційно-довідкові служби. Практично в таких вокодерах здійснюється автоматичне розпізнавання слухових образів, а не визначення параметрів мови.
В параметричних вокодерах з мовного сигналу виділяють два типи параметрів:
- параметри, які характеризують огинаючу спектра мовного сигналу (фільтрову функцію);
- параметри, які характеризують джерело мовних коливань (генераторну функцію) – частота основного тону, її зміни в часі, моменти появи та зникнення основного тону, шумового сигналу.
За цими параметрами на приймальній стороні синтезують мову.
За принципом визначення параметрів фільтрової функції мови розрізняють вокодери:
- смугові канальні (channel);
- формантні;
- ортогональні;
- ліпредери (з лінійним передбаченням мови);
- гомоморфні.
У смугових вокодерах спектр мови ділиться на 7...20 смуг (каналів) аналоговими або цифровими смуговими фільтрами. Велике число каналів у вокодері дозволяє збільшити натуральність та розбірливість. З кожного смугового фільтра сигнал надходить на детектор та фільтр низьких частот з частотою зрізу . Таким чином, сигнали на виході кожного каналу змінюються з частотою не більше . Їх передача можлива в аналоговому та цифровому вигляді.
У формантних вокодерах огинаюча спектра мови зображується комбінацією формант (резонансних частот голосового тракту). Основні параметри формант – центральна частота, амплітуда та ширина смуги частот.
В ортогональних вокодерах огинаюча миттєвого спектра розкладається в ряд за вибраною системою ортогональних базисних функцій. Коефіцієнти цього розкладання передаються на приймальну сторону. Найбільше поширення отримали гармонічні вокодери, які використовують розкладання в ряд Фур’є.
Вокодери з лінійним передбаченням (LPC – Linear Prediction Coding) ґрунтуються на оригінальному математичному апараті.
Гомоформна обробка дозволяє розділити генераторну та фільтрову функції, які утворюють мовний сигнал.
Враховуючи складність одержання параметрів генераторної функції, широке застосування отримали напіввокодери (VE – Voice Excited Vocodec), в яких замість сигналів основного тону та тон-шум використовується смуга мовного сигналу. Смуга частот до 1000 Гц передається по каналу зв’язку в аналоговому або цифровому вигляді. Найбільш відомі напіввокодери VELP (Voice Excited Linear Prediction) та RELP (Residual Excited Linear Prediction).
Вокодери VELP використовують голосове збудження та коефіцієнти лінійного передбачення (КЛП). У вокодерах RELP по вихідному сигналу також обчислюють КЛП.
Якість мови вокодерів є функція від швидкості передачі, продуктивності та затримки обробки. Так, наприклад, низькошвидкісні вокодери звичайно мають більшу затримку та нижчу якість мови ніж високошвидкісні.
У зв’язку з тим, що вокодер використовує канал разом з іншими споживачами або Інтернет з іншими інформаційними потоками, максимальна швидкість повинна бути якомога меншою. Метою сучасних розробок є вокодери зі змінною швидкістю. При цьому використовують фіксовану швидкість для мови та низьку швидкість для фонових шумів. Це досягається за допомогою алгоритмів стискання пауз. У цьому випадку використовують детектор активності мови (VAD), який визначає, чи є вхідний сигнал мовою, чи фоновим шумом. Якщо сигнал вважається мовою, він кодується на номінальній фіксованій швидкості, а коли сигнал вважається шумом, він кодується на більш низькій швидкості.
На приймальній стороні відбувається генерація комфортного шуму. Спосіб генерації комфортного шуму повинен бути таким, щоб кодер та декодер залишалися синхронізованими, навіть якщо протягом деякого часу передача даних не здійснюється. Це дозволяє згладжувати переходи між сегментами активної та неактивної мов.
Смугові вокодери
Типова схема смугового вокодера показана на рис 2.13. Мовний сигнал із мікрофона надходить на гребінку смугових фільтрів (СФ) аналізатора. Кількість фільтрів, а отже і кількість смуг можуть бути різними (від 5 до 20). На виході кожного СФ підключено детектор та згладжувальний фільтр НЧ, який виділяє огинаючу мовного сигналу в даній частотній смузі. Отримана повільно змінювана напруга на виході ФНЧ характеризує амплітуду мовного сигналу в даній смузі частот  . Практика показує, що при досить великій кількості смуг напруга на виході ФНЧ змінюється повільно, тому за амплітуду мовного сигналу в i-й смузі для інженерних розрахунків приймають значення мовного сигналу на середній частоті i-ї смуги. Мовний сигнал надходить також на пристрій виділення основного тону (ОТ), на виході якого формується сигнал, який характеризує частоту основного тону
. Практика показує, що при досить великій кількості смуг напруга на виході ФНЧ змінюється повільно, тому за амплітуду мовного сигналу в i-й смузі для інженерних розрахунків приймають значення мовного сигналу на середній частоті i-ї смуги. Мовний сигнал надходить також на пристрій виділення основного тону (ОТ), на виході якого формується сигнал, який характеризує частоту основного тону  .
.
Крім того, в аналізаторі виділяється сигнал тон-шум (Т-Ш), який характеризує склад спектра звуків мови – дискретний для вокалізованих звуків (тон) або безперервний для невокалізованих звуків (шум). Пристрій виділення сигналів Т-Ш може працювати або безпосередньо від мовних сигналів, або від сигналів, отриманих на виході пристрою виділення ОТ. Тому на рис. 2.13. схема виділення сигналів має два входи.
Сигнали, отримані на виході згладжувального фільтра та на виходах схеми виділення сигналів ОТ та Т-Ш, об’єднуються і перетворюються у форму, яка придатна для передачі каналом зв’язку.
Об’єднання та перетворення сигналів  ,
,  виконуються в пристрої (рис. 2.13), який називається об’єднуючим. На приймальній стороні каналу зв’язку здійснюється розділення сигналів (у розділювальному пристрої) та перетворення їх у форму, яка необхідна для роботи синтезатора.
виконуються в пристрої (рис. 2.13), який називається об’єднуючим. На приймальній стороні каналу зв’язку здійснюється розділення сигналів (у розділювальному пристрої) та перетворення їх у форму, яка необхідна для роботи синтезатора.
В аналогових вокодерах об’єднувальні та розділювальні пристрої реалізуються за принципами частотного розділення сигналів, а в аналогових та цифрових вокодерах – за часовим розділенням сигналів.
Сигнали Т-Ш керують приймачем, за допомогою якого на вхідну гребінку смугових фільтрів подається або широкосмуговий шум від генератора шуму, або імпульси від генератора ОТ. Цей генератор керується сигналом таким чином, що частота слідування імпульсів на виході дорівнює частоті основного тону мовного сигналу на передавальній стороні. Сукупність генераторів ОТ, шуму та схеми переключення Т-Ш називають генератором мовного сигналу (ГМС).
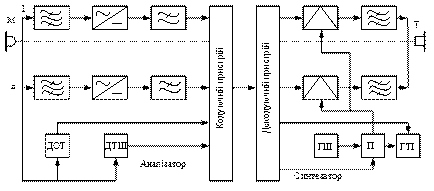
2.13. Функціональна схема полосного вокодера
З виходу смугових фільтрів сигнали надходять на амплітудні модулятори (АМ). На інший вхід АМ як модулюючі надходять сигнали , , які після розділювального пристрою проходять через згладжувальні фільтри ФНЧ. З виходу АМ сигнали надходять на гребінку вихідних смугових фільтрів, які застосовуються для зменшення впливу побічних продуктів модуляції, які виникають в АМ. Сукупність схем та вузлів, у яких перетворюють мовні сигнали в межах кожної з частотних смуг (від входу смугового фільтра до виходу вихідного смугового фільтра синтезатора), називають спектральним каналом смугового вокодера. Звичайно, схеми смугових вокодерів доповнюються пристроями лінійного передбачення, що дозволяє створити смугові вокодери з лінійним передбаченням або ЛПК-вокодери. У таких вокодерах використовуються алгоритми лінійного передбачування, за допомогою яких під час аналізу в передавальному пристрої визначаються коефіцієнти передбачення, а в приймальному пристрої на основі цих коефіцієнтів за допомогою рекурсивного цифрового фільтра синтезується еквівалент голосового тракту.
Ідея методу лінійного передбачення заключається в тому, що величина, яка прогнозується у мовному сигналі  на момент випробування h, визначається як лінійно зважена сума попередніх вибірок:
на момент випробування h, визначається як лінійно зважена сума попередніх вибірок:
 ,
,
де  – мовний сигнал в попередній момент випробувань;
– мовний сигнал в попередній момент випробувань;  ;
;  – коефіцієнти передбачення.
– коефіцієнти передбачення.
Інтервали часу між моментами вимірювань частотної дискретизації  . В момент h, коли відомі , але й дійсне значення мовного сигналу
. В момент h, коли відомі , але й дійсне значення мовного сигналу  , можна визначити помилку передбачення
, можна визначити помилку передбачення
 ,
,
а потім підібрати коефіцієнти передбачення таким чином, щоб помилка передбачення була мінімальною. Звичайно, як критерій мінімізації використовують мінімум середньоквадратичної помилки. В цьому випадку треба визначити такі значення , при яких  . Задача мінімізації зводиться до рішення системи лінійних рівнянь відносно .
. Задача мінімізації зводиться до рішення системи лінійних рівнянь відносно .
Пристрій для обчислення помилки передбачення відповідно до виразу (2.6) представляє собою фільтр, передатна характеристика якого дорівнює передатній характеристиці фільтра, який імітує мовний тракт. Тому перетворення, що відповідає виразу (2.6), називають інверсною фільтрацією.
Усереднення помилки передбачення виконується на інтервалі  вибірок, які утворюють кадр (фрейм). Бажано, щоб довжина аналізованого звуку мови була узгоджена з довжиною кадру, але це технічно виконати складно. Тому звичайно приймають
вибірок, які утворюють кадр (фрейм). Бажано, щоб довжина аналізованого звуку мови була узгоджена з довжиною кадру, але це технічно виконати складно. Тому звичайно приймають  , що при
, що при  8000 Гц відповідає довжині кадру
8000 Гц відповідає довжині кадру  мс.
мс.
Для одержання задовільної якості мовних сигналів, які синтезуються, потрібно підрахувати не менше десяти коефіцієнтів передбачення , що в (2.5) відповідає  . Враховуючи це, в аналізаторі ЛПК-вокодера треба вирішувати 100...200 лінійних рівнянь з 10...12 невідомими.
. Враховуючи це, в аналізаторі ЛПК-вокодера треба вирішувати 100...200 лінійних рівнянь з 10...12 невідомими.
Коефіцієнти передбачення, значення яких передаються каналом зв’язку, використовуються як перемінні параметри у рекурсивному цифровому фільтрі, на вхід якого подаються сигнали збудження. Як сигнали збудження в ЛПК-вокодері використовуються такі ж сигнали, які мають місце на виході генераторів мовного спектра (ГМС) у смугових вокодерах. Під час відтворення вокалізованих звуків – це послідовність імпульсів ОТ, а невокалізованих звуків – це випадкова послідовність імпульсів, сформованих генератором шуму.
Замість коефіцієнтів передбачення в більшості варіантів схем ЛПК-вокодерів передбачено отримання еквівалентного набору величин, які носять назву коефіцієнтів відбиття 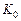 . Ці параметри менш чутливі до квантування, ніж коефіцієнти передбачення . Набори параметрів та пов’язані поміж собою набором стандартних рекурентних співвідношень.
. Ці параметри менш чутливі до квантування, ніж коефіцієнти передбачення . Набори параметрів та пов’язані поміж собою набором стандартних рекурентних співвідношень.
Ширина смуги фільтрів на вході та виході вибирається з урахуванням електроакустичних перетворювачів, які використовуються при цьому. Перетворювачі аналог-код та код-аналог працюють на принципах ІКМ. Аналізатор сигналів збудження здійснює виділення сигналів ОТ та Т-Ш, а також загального рівня (огинаючої мовного сигналу). Інші вузли виконують ті ж функції, що й у смуговому вокодері без лінійного передбачення.
Під час синтезу та дослідження смугових вокодерів з ЛПК використовують різні моделі мовного процесу. Найбільш точна модель мови представляє собою нестаціонарний випадковий процес з повільно змінюваною дисперсією та спектральною щільністю. У разі використання такої моделі можна одержати найбільш точний результат оцінки якості вокодера.
Питання для самоперевірки
1. Яка роль безперервних систем зв’язку в загальній системі зв’язку цивільної авіації?
2. Наведіть основні характеристики мовного сигналу.
3. Що таке основний тон мови, форманта, фонема?
4. Що таке артикуляція?
5. Які орієнтовні цифри, що характеризують норми розбірливості?
6. Яка природа надлишковості мовного сигналу?
7. Що таке кліпування мови?
8. Яка теоретична границя можливого стиснення спектра телефонного сигналу?
9. Що таке вокодер?
10. Які схемні методи підвищення завадостійкості безперервних систем зв’язку ви знаєте?