|
|
Какие процедуры используются в рамках контент - анализа ?
Контент -анализ позволяет выполнить следующие процедуры анализа:
§ частотный анализ текста, построение смысловых групп;
§ смысловой анализ текста, нахождение синонимичных выражений;
§ поиск связей в тексте для заданных слов;
§ построение карт текстов и сравнение их между собой;
§ вычисление стандартных коэффициентов (число слов, предложений, средняя длина предложения);
§ вычисление интегральных характеристик текста (лексическое разнообразие, структурная и грамматическая сложность);
§ сравнение текстов между собой различными методами и вычисление интегральных индексов сходства текстов по результатам сравнения;
§ нахождение функциональных зависимостей между характеристиками текста и проверка этих зависимостей на других текстах.
Определение
Определений контент-анализа существует много, но среди них трудно найти удовлетворительное. Например, можно встретить следующие формулировки:
- статистическая (квантитативная) семантика;
- техника для объективного количественного анализа содержания коммуникации;
- техника для делания выводов при помощи объективного и систематического установления характеристик сообщений.
Каждая из приведенных выше формулировок неудовлетворительна уже по той причине, что основной акцент в них делается на количественные параметры анализа текстов и в них совершенно не отражена специфика качественных методов контент-анализа.
Слишком широким является определение контент-анализа как "исследовательского метода, используемого для определения присутствия определенных слов или понятий в тексте или массивах текстов".
Под текстами в контент-анализе понимают книги, книжные главы, эссе, интервью, дискуссии, заголовки газетных статей и сами статьи, исторические документы, дневниковые записи, речи выступлений, рекламные тексты и т.д.
 Качественный vs количественный
Качественный vs количественный
Количественный контент-анализ в первую очередь интересуется частотой появления в тексте определенных характеристик (переменных) содержания.
Качественный контент-анализ позволяет делать выводы даже на основе единственного присутствия или отсутствия определенной характеристики содержания.
Различие двух подходов довольно легко проиллюстрировать примерами.
В 50-е годы западные аналитики на основе количественного анализа статей газеты "Правда" обнаружили резкое снижение числа ссылок на Сталина. Отсюда они сделали закономерный вывод, что последователи Сталина стремятся дистанцироваться от него.
С другой стороны, качественный аналитик мог бы сделать аналогичный вывод на основе единственного факта, что в публичной речи одного из партийных функционеров, посвященной победе СССР в Великой Отечественной войне, Сталин вообще не был упомянут. Прежде такое было бы немыслимо.
Очевидно, что количественный контент-анализ легче поддается реализации в компьютерных программах. Именно по этой причине в дальнейшем мы будем вести речь исключительно о методах количественного контент-анализа.
Следует обратить внимание на то, что когда говорят о контент-анализе текстов, то главный интерес всегда заключается не в самих характеристиках содержания, а во внеязыковой реальности, которая за ними стоит - личных характеристиках автора текста, преследуемых им целях, характеристиках адресата текста, различных событиях общественной жизни и пр.
Простые частоты
Первым можно назвать этап в развитии контент-анализа, когда внимание исследователей было направлено в основном просто на подсчет частот появления в текстах различных слов или тем. Г.Г. Почепцов условно относит появление контент-анализа к 18 веку, "когда в Швеции частота появления тем, связанных с Христом, использовалась для принятия решения о еретичности книги."
Относительные частоты
Однако, просто частота появления того или иного слова или темы мало что говорят. Гораздо более информативны не абсолютные, а относительные частоты, которые вычисляются как отношение абсолютной частоты к длине анализируемого текста. В зависимости от того, что является переменной содержания, под длиной текста может пониматься количество слов в нем, количество предложений, абзацев и пр.
В качестве реального примера такого анализа текстов можно привести анализ президентских посланий стране, с которыми обратился Б.Клинтон в 1994 и 1995 годах. Эти послания содержат от 7000 до 10000 слов. Были сформированы категории слов, относящихся к экономике, бюджету страны, образованию, преступности, вопросам семьи, международным делам, социальной помощи и др. По изменению относительных частот в посланиях 1994 и 1995 годов были сделаны выводы об изменении политики государства в различных областях. Т.е. все эти темы нашли отражение в обоих посланиях, но в одном из них некоторым темам уделялось больше внимания, а в другом меньше. Например, в послании 1995 года больше внимания было уделено вопросам образования, семьи, но меньше внимания - преступности, международным делам, социальной помощи. Это дало основания для того, чтобы судить о приоритетах правительства США.
Категории
В приведенном выше примере было упомянуто понятие категории. В качестве категории может выступать набор слов, объединенных по определенному основанию. Можно сказать, что посредством категорий в контент-анализе представлены определенные концептуальные образования. Так в случае с посланиями Б.Клинтона была образована категория
ЭКОНОМИКА, в которую входили слова - экономика, безработица, инфляция. В категорию СЕМЬЯ входили слова - ребенок, семья, родители, мать, отец. Именно учет частот встречаемости категорий, а не отдельных слов, позволяет судить о внимании, уделенном в послании тем или иным вопросам.
Очевидно, что от качества составления таких категорий во многом зависит качество результатов анализа. контент-анализ текстов с использованием категорий иногда называют концептуальным анализом. Сфера его применения довольно широка. Два основных типа задач, решаемых с его помощью:
- Есть два или более текстов, которые необходимо сравнить в отношении нагрузки на определенные категории. Например, задача выяснить, какое внимание уделяют две разные газеты определенным темам. Если эти газеты рассчитаны на одну аудиторию, то существенное различие в частотах позволит судить о различиях в политике, проводимой людьми, стоящими за ними.
- Задача отслеживания динамики изменения нагрузки на определенные категории. Например, выяснить частоту упоминания темы внешнего долга России в фиксированном наборе центральных газет на протяжении какого-то времени и соотнести ее с колебаниями курса доллара путем простого корреляционного анализа.
Из истории разведки известно, как по изменению в специальной литературе частоты упоминания определенных научных тем и фамилий ученых делались достоверные выводы об успехах, достигнутых в конкретных областях исследований.
Из новых функция в четвертой версии появилась оценка архетипичности и агрессивности текста.
Нормы
Относительные частоты позволяют сравнивать два и более текстов, но иногда требуется сделать вывод на основе анализа лишь одного текста.
Например, имеется текст выступления депутата Думы и требуется оценить, насколько оно агрессивно. Прежде всего для решения этой задачи должна быть составлена категория агрессивно окрашенной лексики. После этого мы можем сравнить текст выступления нашего депутата с выступлениями других и сказать, кто из них агрессивнее. Но от нас требуется не это, от нас требуется оценить степень агрессивности выступления. Очевидно, что для ответа на этот вопрос нам потребуется некоторая норма, своеобразная нулевая отметка агрессивности. Мы получим ее, если выясним относительную частоту употребления агрессивно окрашенных слов средним носителем русского языка. Помощь в этом могут оказать частотные словари. Сравнивая относительную частоту употребления агрессивно окрашенной лексики в выступлении депутата с частотой ее употребления средним носителем русского языка мы как раз и можем сделать вывод о степени агрессивности. Но и это еще не все. Небольшие отклонения частот в большую или меньшую сторону могут быть следствием случайных колебаний. На вопрос о значимости отклонения частот позволяет ответить статистическая оценка, известная под названием z-score и вычисляемая по формуле(N-E)/(стандартное отклонение), где N - количество слов данной категории, реально встретившихся в тексте, а E - ожидаемое число вхождений слов данной категории в текст. Величина E вычисляется путем умножения нормальной частоты категории на число слов в анализируемом тексте.
Представим, что мы хотим оценить степень агрессивности выступления не депутата, а профессионального военного. Очевидно, что норма для него будет отличаться от нормы для среднего человека. Поэтому для оценки уровня агрессивности профессионального военного требуются другие нормы, которые могут быть получены путем дополнительной статистической обработки представительной выборки текстов, характерных для военной среды.
Связи категорий
Дальнейшее развитие контент-анализа требовало более тонких методов анализа текстов. К середине 50-х годов исследователи стали все больше уделять внимания не простому наличию или отсутствию категорий в тексте, а связям между категориями. Для этого обращают внимание на совместную встречаемость (cooccurence) слов различных категорий. Например, для каждого предложения текста мы можем выяснить, слова каких категорий в нем встречаются. После этого легко подсчитать обычный коэффициент корреляции, который даст нам силу связи между категориями и знак этой связи. Может оказаться, что для некоторых категорий наблюдается тенденция их совместного употребления, а для других - наоборот.
В качестве гипотетического примера можно привести газетную статью, в которой наблюдается совместное употребление категорий ПРАВИТЕЛЬСТВО и НЕГАТИВ.
Интересно то, что в некоторых случаях это может быть отражением сознательной позиции автора статьи, а в некоторых - связью на уровне подсознания.
Понятно, что изучение связей между категориями значительно расширяет круг задач, которые может решать контент-анализ.
Круг пользователей расширялся. Дополнительно ими становились журналисты, подразделений по связям с общественностью различных банков и крупных компаний. Продолжался расширяться круг пользователей системы ВААЛ и в среде депутатов различных уровней.
Collocations
Представим, что мы взяли статью натуралиста о змеях и решили ее проанализировать. Для этого мы отметили в тексте все предложения, в которые входит слово , и составили статистику слов из этих предложений. Можно предположить, что частотными в этих предложениях окажутся слова: яд, ядовитый, укус, ползать, длинный...т.е. те слова, которыми наиболее часто характеризуются змеи. Таким образом, наш формальный метод анализа текстов позволил выделить существенные признаки, характеризующие змей. В англоязычной литературе такие контексты употребления слов как раз и называют collocations.
Ценность описанного метода анализа текстов очевидна, так как позволяет на основе формальных методов извлекать из массивов текстов содержательную информацию.
Контекстный анализ
Метод нахождения контекстов употребления слов (collocations) допускает дальнейшее развитие. Выбрав предложения, в которых встречается конкретное слово или категория, мы получили некоторую подвыборку текста, к которой в свою очередь применимы все методы контент-анализа. Т.е. контексты употребления слов и категорий в свою очередь могут быть подвергнуты контент-анализу - выяснению простых частот категорий , относительных частот, оценок категорий относительно нормы и т.д.
Если выразиться образно, то контекстный анализ позволяет выделить в тексте несколько тематических нитей и анализировать их отдельно.
Очевиден огромный потенциал контекстного анализа при мониторинге больших объемов информации, так как он позволяет полностью автоматизировать весь процесс сбора информации.
Автоматическая категоризация
Использование при контент-анализа определенного набора категорий задает концептуальную сетку, в терминах которой и анализируется текст. От того, насколько удачен набор используемых категорий, зависит качество результатов анализа. Поэтому исследователей давно интересовала задача автоматической категоризации слов текста, т.е. выделение обсуждаемых в нем тем.
Были предложены ряд подходов для решения этой задачи. Следует отметить, что автоматическая категоризация возможна лишь в том случае, если объем анализируемых текстов достаточно велик.
В течение последних лет арсенал методов, применяемых маркетологами и специалистами в области PR существенно расширился. Например, все больше компаний хотели бы знать, в каком контексте они упоминаются в СМИ и каков их имидж в глазах общественности. До недавнего времени с этой целью чаще всего применялись традиционные аналитические методы:
- простой количественный подсчет выходов публикаций (в лучшем случае в комплексе с определением тональности публикации);
- сравнение количества вышедших абсолютных и относительных материалов;
- сравнение количества вышедших материалов не только по параметрам упоминания персоналий либо названий, но также по брендам/торговым маркам, структуре товаров/услуг;
- выявление частоты упоминания компаний/персоналий.
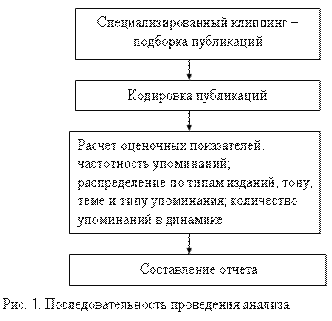
Все перечисленные средства являются по своей природе отдельными элементами полноценного контент-анализа. Собственно же КА представляет собой скрупулезное и тщательное исследование текстов, целью которого является жесткое систематизирование информации в соответствии с заданными параметрами. Применяя этот инструмент можно исследовать такие параметры, как, отношение СМИ к интересующей тематике, дифференцировать материалы по инициаторам подачи материалов (клиент/конкурент/посредник), отслеживать каналы распространения информации, вычислять посредством формул заметность информационных материалов, производить семантический анализ текста (в случаях с неоднозначной, многозначной интерпретацией) и т.д.
Алгоритм проведения контент-анализа выглядит следующим образом.