|
|
Параметры распределения ( перцентиль, квартиль, меры положения, изменчивости, формы)
p- Персентиль определяет такое значение заданного распределения, которое больше р-процентов всех значений распределений. Например, если вес новорожденного ребенка относится к 75 персентили, то он весит больше, чяем 75% всех новорожденных детей. Если покупателю известна 90 персентиль для цен на дома по разным районам, то он может лего сопоставить стоимость 90% домов по разным районам.
Близкими по смыслу к персентилям являются квартили. Квартили соответствуют 25, 50, 75 персентилям, т.е. четвертям распределения (их называют первой, второй, третьей квартилью).
Разница между третьей и первой квартилью называется интерквартильным диапазоном, в этом диапазоне располагается 50% данных и он дает представление о ширине распределения.
Один из способов подсчета персентилей и квартилей является построение таблицы частот, по столбцу накопленных частот легко определить значения персентилей. Также имеются специальные статистические функции для расчета по заданному персентилю –значения из выборки или по данному значению из выборки –соответствующего значения персетиля. Это функции ПЕРСЕНТИЛЬ и ПРОЦЕНТРАНГ.
ПЕРСЕНТИЛЬ - Возвращает k-ую персентиль для значений из интервала. Эта функция используется для определения порога приемлемости. Например, можно принять решение экзаменовать только тех кандидатов, которые набрали большее количество баллов, чем 90-ая персентиль.
Синтаксис: ПЕРСЕНТИЛЬ(массив;k)
Массив — массив или интервал данных с числовыми значениями, который определяет относительное положение.
k — значение персентили в интервале от 0 до 1 включительно.
ПРОЦЕНТРАНГ - Возвращает категорию значения в наборе данных как процентное содержание в наборе данных. Эта функция используется для оценки относительного положения точки данных в множестве данных. Например, c помощью функции ПРОЦЕНТРАНГ можно оценить положение подходящего результата тестирования среди всех результатов тестирования.
Синтаксис: ПРОЦЕНТРАНГ(массив;x;разрядность)
Массив — массив или интервал данных с числовыми значениями, который определяет относительное положение.
x — значение, для которого определяется процентное содержание.
Разрядность — необязательное значение, определяющее количество значащих цифр для возвращаемого процентного значения. Если этот аргумент опущен, то функция ПРОЦЕНТРАНГ использует три цифры (0,xxx).
Распределения вероятностей характеризуются функциями плотности вероятности (ПВ). В свою очередь, эти функции характеризуются параметрами генеральной совокупности. Например, ПВ для нормального распределения характеризуется двумя параметрами: средним 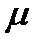 (произносится “мю”), которое обозначает центр распределения, и стандартным отклонением
(произносится “мю”), которое обозначает центр распределения, и стандартным отклонением  (произносится “сигма”), которое характеризует изменчивость значений распределения. (Зная эти параметры, можно рассчитать ПВ для нормального распределения).
(произносится “сигма”), которое характеризует изменчивость значений распределения. (Зная эти параметры, можно рассчитать ПВ для нормального распределения).
В большинстве случаев значения параметров генеральной совокупности неизвестны и их можно только оценить. Именно для этого предусмотрены оценочные функции, или оценки. При анализе данных желательно использовать состоятельные и неискаженные оценки, которые стремятся к истинным значениям параметров генеральной совокупности при увеличении размеров выборки. Теоретически при достаточно большой выборке можно получить оценку с любой заданной точностью.
Для оценки среднего 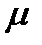 для нормального распределения можно использовать следующую формулу выборочного среднего
для нормального распределения можно использовать следующую формулу выборочного среднего 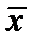 :
:  , а для оценки стандартного отклонения
, а для оценки стандартного отклонения  для нормального распределения можно использовать следующую формулу выборочного стандартного отклонения
для нормального распределения можно использовать следующую формулу выборочного стандартного отклонения 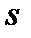 :
:  . Обе оценки являются состоятельными, т.е. стремятся к истинным значениям и при увеличении размеров выборки
. Обе оценки являются состоятельными, т.е. стремятся к истинным значениям и при увеличении размеров выборки 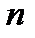 .Насколько большой должна быть выборка, чтобы получить хорошую оценку истинных значений параметров генеральной совокупности? Для ответа на этот вопрос нужно проанализировать выборочное распределение, т.е. определить, какому распределению удовлетворяет оценочная функция. Для этого можно создать несколько выборок и вычислить для них выборочные средние. Затем можно собрать выборочные средние в новую “выборку выборок” и проанализировать ее распределение при увеличении размера каждой исходной выборки.
.Насколько большой должна быть выборка, чтобы получить хорошую оценку истинных значений параметров генеральной совокупности? Для ответа на этот вопрос нужно проанализировать выборочное распределение, т.е. определить, какому распределению удовлетворяет оценочная функция. Для этого можно создать несколько выборок и вычислить для них выборочные средние. Затем можно собрать выборочные средние в новую “выборку выборок” и проанализировать ее распределение при увеличении размера каждой исходной выборки.
Виды средних
Средние величины используются для характеристики обычных, типичных значений признака, когда они рассчитываются по данным однородной совокупности. Например, можно говорить о типичной заработной плате работников определенной профессии в отдельной отрасли, о среднем надое молока от коров определенной породы при соответствующих нормах кормления и т.д. Если средние рассчитываются по неоднородным данным, например, среднее потребление мяса, производство национального дохода надушу населения в республике, то эти средние характеризуют государство как единую народнохозяйственную систему; поэтому они называются системные средние.
Средняя арифметическая простая (невзвешенная) вычисляется по формуле:

х1,х2,х3,…,хn значения осредняемого признака; n - число значений
Средняя арифметическая взвешенная вычисляется по формуле:

где, х1,х2,х3,…хn- значения осредняемых вариантов у отдельных промышленных предприятий, магазинов, хозяйств и других объектов (значения случайной величины) ; f1, f2, f3, …, fn - значения веса у отдельных промышленных предприятий, магазинов, хозяйств и других объектов.
Если осредняемый признак первичный, то в качестве f берутся частоты, если - вторичный, то в качестве f берется признак, по отношению к которому рассчитывается значение вторичного признака. Например, первичным признаком будет надой молока на одну корову, при расчете среднего надоя в качестве веса будут использоваться данные о количестве коров, имеющих определенный надой молока. Процент жирности молока - вторичный признак, рассчитывается в виде соотношения количества жира к количеству молока; при расчете среднего процента жирности в качестве веса будет использоваться количество молока, имеющего определенный процент жирности.
Средняя гармоническая взвешенная вычисляется по формуле:

где, х1,х2,х3,…,хn - значения осредняемого показателя (;
М1,М2,М3,…,Мn- веса у отдельных предприятий, магазинов, хозяйств.
Мода (М0 ) и медиана (Me)
Мода (М0 ) и медиана (Me)относятся к наиболее часто используемым структурным средним
Модой называется значение признака, наиболее часто встречающееся в совокупности, в ряде распределения.
В дискретном ряде распределения моду найти просто - взять значение признака, имеющего наибольшую частоту. При расчете моды по данным интервального ряда распределения используется формула:
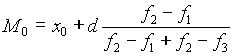 ,
,
где:
х0 - нижняя граница модального интервала, т.е. интервала, который чаще всего встречается;
d - размах интервала;
f2 - частота модального интервала;
f1 и f3 - соответственно частота интервала, предшествующего модальному, и интервала, следующего за модальным.
Примером использования моды является учет цен на рынках: учитывается цена на отдельный товар, наиболее часто встречающийся.
Медианой в статистике называется значение признака, которое делит численность упорядоченного ряда распределения на две равные части.
Упорядоченным рядом распределения называется ряд, значение признака в котором изменяется в порядке возрастания или убывания.
Наглядным примером медианы может быть следующий. Представим шеренгу солдат, стоящих по росту; медианным ростом будет рост солдата, стоящего в середине шеренги.
Мода и медиана дают представление о типичном, обычном значении признака, к тому же они позволяют получить представление о структуре совокупности, поэтому их называют структурными средними.
В отличие от средних значений отдельных признаков модальные и медианные значения не увязываются в систему. Зная медианное значение часовой выработки, продолжительности рабочего дня и рабочего месяца, медианное значение месячной выработки рабочего на их основе получить будет нельзя.
Значение медианы в меньшей степени, чем средней, зависит от резко отличающихся от остальных значений признака